Discussão do artigo "Redes neurais de maneira fácil (Parte 22): Aprendizado não supervisionado de modelos recorrentes"
{kind=link}
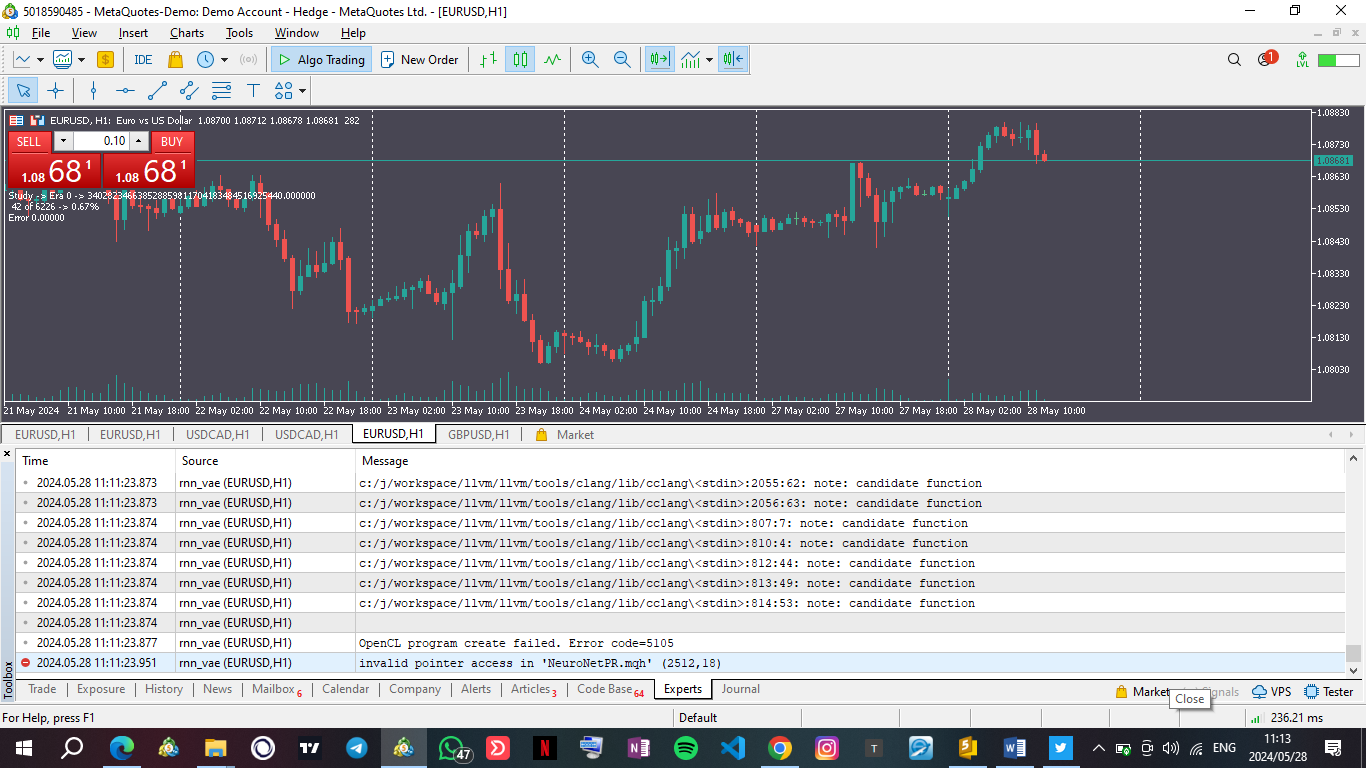
Olá, você pode me ajudar com o erro que diz "acesso de ponteiro inválido em 'NeuroNetPR.mqh' (2512,18)"?
Olá, tentei fazer isso e ainda não funcionou ..... O mesmo erro está presente desde o artigo 8 e não encontrei uma maneira de resolvê-lo.
O erro aponta para a função ::save da CNET no ponto de declaração de bool result=layers.Save(handle); e aponta para a variável "layers".
1432189 #:
Olá, eu tentei isso e ainda não funcionou .... o mesmo erro está presente desde o artigo 8 e não encontrei uma maneira de resolvê-lo
O erro aponta para a função ::save da CNET no ponto de declaração de bool result=layers.Save(handle); e aponta para a variável "layers".
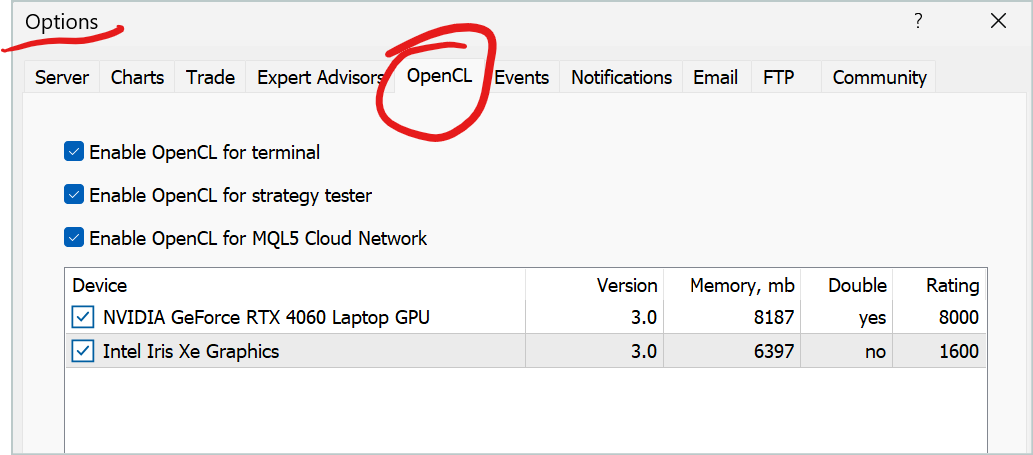
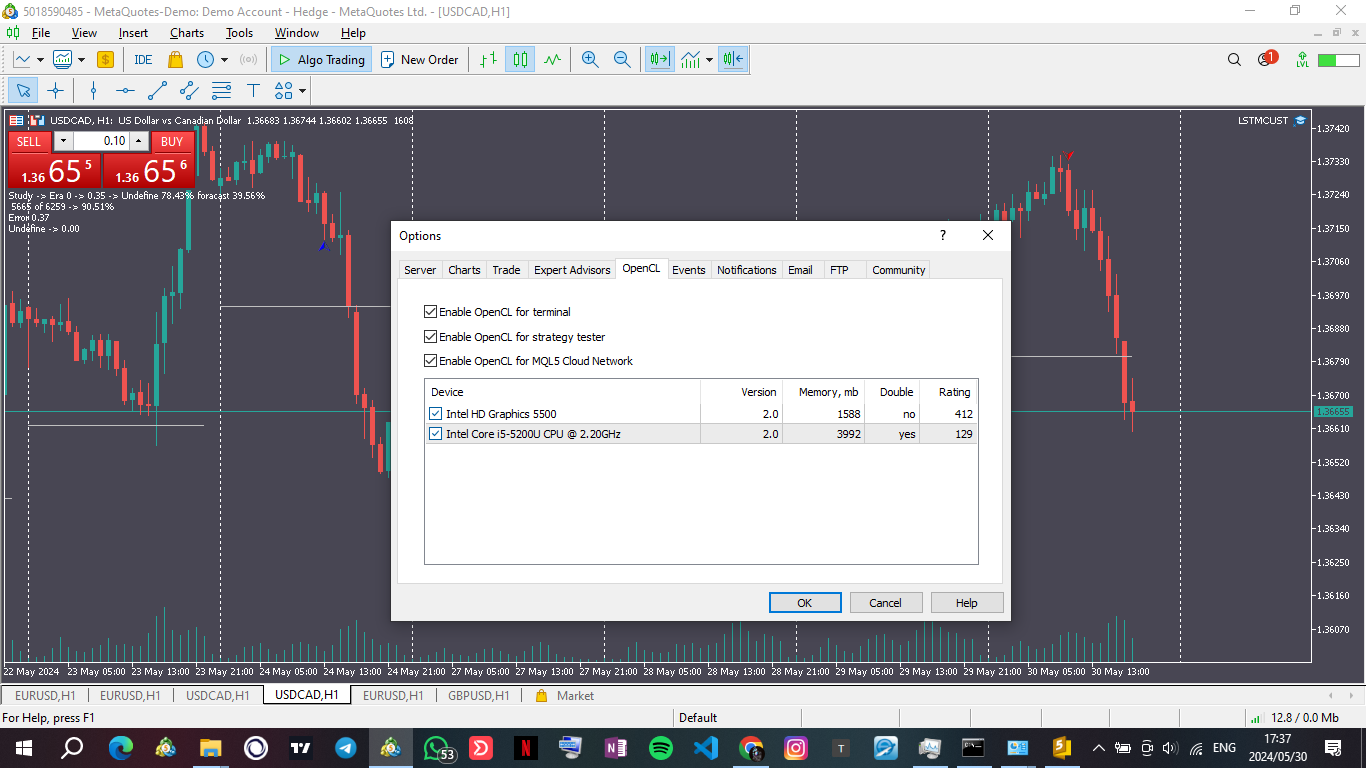
O que você vê nas opções do MetaTrader 5
{kind=link}
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
Novo artigo Redes neurais de maneira fácil (Parte 22): Aprendizado não supervisionado de modelos recorrentes foi publicado:
Continuamos a estudar algoritmos de aprendizado não supervisionado. E agora proponho discutir as particularidades por trás do uso de autocodificadores para treinar modelos recorrentes.
O modelo foi testado com a preservação de todos os parâmetros usados anteriormente: EURUSD, H1, período de teste como últimos 15 anos. Configurações padrão do indicador. As últimas 10 velas são alimentadas na entrada do codificador. Nesse caso, o decodificador é treinado para decifrar as últimas 40 velas. Os resultados do teste são mostrados no gráfico abaixo. Os dados são alimentados na entrada do codificador após a conclusão da formação de cada nova vela.
Como você pode ver no gráfico, os resultados dos testes confirmam a viabilidade dessa abordagem para pré-treinamento não supervisionado de modelos recorrentes. Durante o treinamento de teste do nosso modelo, após 20 épocas de treinamento, o erro do modelo quase se estabilizou com uma taxa de perda inferior a 9%. Ao mesmo tempo, deve-se dizer que as informações sobre pelo menos 30 iterações anteriores são armazenadas no estado latente do modelo.
Autor: Dmitriy Gizlyk