Aprendizado de máquina no trading: teoria, prática, negociação e não só - página 851
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
2 classes
Carregado 1 núcleo
Definição , rfeControl = rfeControl(número = 1,repetições = 1) - tempo reduzido para 10-15 minutos. Mudanças nos resultados - 2 pares de preditores trocados, mas em geral semelhantes ao que era o padrão.
Bem, aí tens, os teus 10 minutos num só núcleo são os meus 2 em 4 e dois minutos que não me lembro.
Eu nunca espero por algo por horas, se 10-15 minutos não funcionou, então algo está errado, então gastar mais tempo não vai servir de nada. Qualquer optimização na construção de um modelo que dure horas é um completo fracasso na compreensão da ideologia da modelação, que diz que o modelo deve ser o mais bruto possível e de forma alguma tão preciso quanto possível.
Agora sobre a selecção dos preditores.
Porque estás a fazer isto e porquê? Que problema estás a tentar resolver?
A coisa mais importante na seleção é tentar resolver o problema da reciclagem. O seu modelo está sobretreinado? Se não, então a seleção pode acelerar a aprendizagem reduzindo o número de preditores. Mas reduzir o número é muito mais eficiente, isolando os componentes principais. Eles não afetam nada, mas podem reduzir o número de preditores por ordem de magnitude e, consequentemente, aumentar a velocidade de encaixe do modelo.
Então, para começar: por que você precisa disso?
Encontrei outro pacote interessante para peneirar os preditores. Chama-se FSelector. Oferece cerca de uma dúzia de métodos para peneirar os preditores, incluindo a entropia.
Eu peguei um arquivo com os preditores e um alvo daqui -https://www.mql5.com/ru/forum/86386/page6#comment_2534058
A avaliação do preditor por cada método que apresentei no gráfico no final.
Azul é bom, vermelho é ruim (para resultados de corrplot foram escalados para [-1:1], para avaliação exata veja resultados de cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), etc.)
Você pode ver que X3, X4, X5, X19, X20 são bem avaliados por quase todos os métodos, você pode começar com eles, então tente adicionar/remover mais.
No entanto, os modelos em guizo não passaram no teste com estes 5 preditores em Rat_DF2, mais uma vez o milagre não aconteceu. Ou seja, mesmo com os demais preditores, você tem que ajustar os parâmetros do modelo, fazer a validação cruzada, adicionar/remover os preditores você mesmo.
Eu fiz a mesma coisa com CORElearn usando dados dos artigos do Vladimir.
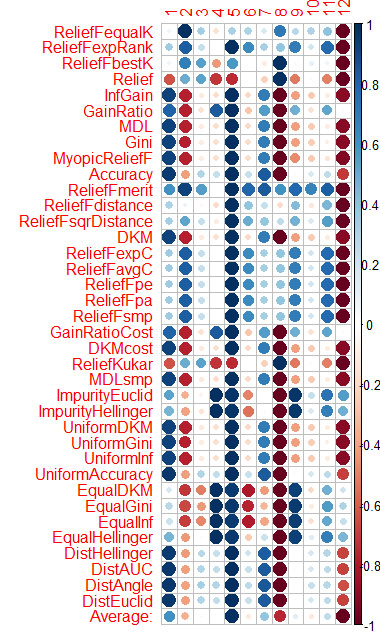
Eu calculei a média das colunas (a linha inferior é Média) e ordenei por ela. É mais fácil perceber a importância total desta forma.
Levou 1,6 minutos - e são 37 algoritmos que funcionam. A velocidade é muito melhor que a do Caret (16 minutos), com resultados semelhantes.
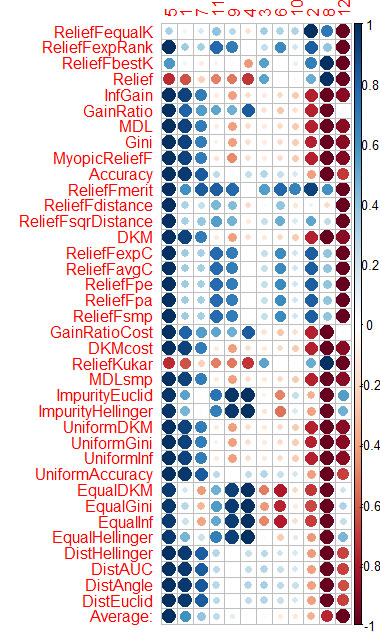
Eu fiz a mesma coisa com CORElearn usando dados dos artigos do Vladimir.
Eu calculei a média por colunas (a linha inferior Média) e ordenei por ela. É mais fácil perceber a importância total desta forma.
Demorou 1,6 minutos e levou 37 algoritmos.
Então, qual é o resultado final?? Você respondeu à pergunta sobre a importância dos preditores ou não, porque eu não entendo um pouco essas fotos.
Para mim agora não há nenhum problema ao construir e selecionar um modelo, eu seleciono os preditores, depois construo 10 modelos sobre eles, depois a informação mútua seleciona aquele que funciona melhor. Você sabe como fazê-lo? É um desafio mental!!! Muito bem, quem o resolve é o melhor !!!!!
Consegui arranjar um conjunto de modelos. E na verdade vporez: Qual dos modelos está a funcionar e porque??????
Ou melhor, todos eles funcionam, mas apenas um deles pode discar. E explicar porquê?
Então, qual é o resultado final?? Você respondeu à pergunta sobre a importância dos preditores ou não, porque eu não entendo um pouco essas fotos.
Para mim agora não há nenhum problema ao construir e selecionar um modelo, eu seleciono os preditores, depois construo 10 modelos sobre eles, depois a informação mútua seleciona aquele que funciona melhor. Você sabe como fazê-lo? É um desafio mental!!! Muito bem, quem o resolve é o melhor !!!!!
Consegui arranjar um conjunto de modelos. E na verdade vporez: Qual dos modelos está a funcionar e porque??????
Ou melhor, todos eles funcionam, mas apenas um deles pode discar. E explicar porquê?
Os prognosticadores do Vtreat são muito semelhantes (importante primeiro)
5 1 7 11 4 10 3 9 6 6 2 12 8
E aqui está a ordenação por meios em CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
Acho que não me vou incomodar com mais pacotes de selecção de preditores.
Então, o Vtreat é suficiente. Excepto que a interacção dos preditores não é tida em conta. Provavelmente também.
Eu estou em lágrimas quando vejo que você continua captando a importância dos preditores para alguns pedaços da história do mercado. Porquê? É uma profanação de métodos estatísticos.
Verificou-se na prática que se o preditor número 2 for introduzido no NS - o erro aumenta de 30% para quase 50%.
e no OOS, como é que o erro muda?
Como é que o erro muda no OOS?
de forma semelhante. Como nos artigos do Vladimir - os dados são de lá.
E se estiver em um OOS diferente?
Na prática, eu verifiquei que se você alimentar o preditor número 2 para o NS, o erro aumenta de 30% para quase 50%.
Cuspa nos preditores, e alimente as séries temporais normalizadas para o NS. Os NS encontrarão os próprios preditores - +1-2 camadas, e aí você tem