계량 경제학: 참고 문헌
다음 링크는 "회귀 분석의 기초" 주제에서 사용할 수 있습니다.
데이비슨 , 러셀 그리고 제임스 G. 매키넌 (1993). 계량 경제학 의 추정 및 추론 , Oxford: 옥스포드 대학 출판부.
Greene, William H. (2008). 계량경제학적 분석 , 6판, Upper Saddle River, NJ: Prentice-Hall.
Johnston, Jack 및 John Enrico DiNardo(1997). 계량경제학적 방법 , 4판, 뉴욕: McGraw-Hill.
Pindyck, Robert S. 및 Daniel L. Rubinfeld(1998). 계량경제학적 모형과 경제전망 , 4판, 뉴욕: McGraw-Hill.
Woodridge, Jeffrey M. (2000). 입문 계량 경제학: 현대적 접근 . 오하이오주 신시내티: South-Western College Publishing.
나는 그 인수(독립 변수, 회귀자)에 따라 함수(종속 변수)에 불과한 회귀의 예를 제공할 것입니다. 회귀를 계산할 때 수행해야 할 몇 가지 단계가 있습니다.
1. 방정식을 쓸 필요가 있습니다.
사랑하는 MA를 가져갈 것이지만 가중치가 있으므로 이전 5개 막대(지연 값)에서 계산하여 용서하겠습니다. 나는 공식을 다음과 같이 씁니다.
EURUSD = C(1)*EURUSD(-1) + C(2)*EURUSD(-2) + C(3)*EURUSD(-3) + C(4)*EURUSD(-4) + C(5) *유로USD(-5)
2. 평가
MA 곡선이 해당 연도의 원래 EURUSD_H1 시리즈와 최대한 일치하도록 이 방정식의 c(i) 계수를 추정할 필요가 있습니다. 미지의 계수를 추정한 결과를 얻습니다.
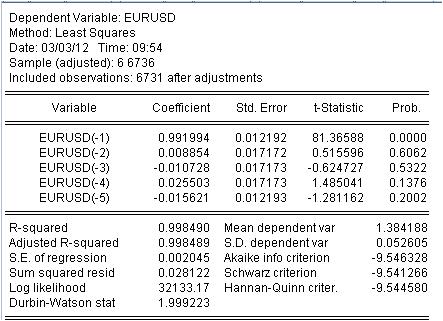
우리는 가중치 자동차의 계수 값을 얻었습니다. 방정식이 있습니다.
EURUSD = 0.991993934254*EURUSD(-1) + 0.00885362355538*EURUSD(-2) - 0.0107282369642*EURUSD(50-3) + 0.0255027160774*EURUSD 5027160774*EUR
3. 결과.
우리는 어떤 결과를 보고 있습니까?
3.1. 우선, 마샤 방정식 자체. 동시에 한 가지 뉘앙스를 기록합니다. 평균을 가르치는 간단한 mashka를 계산할 때 어떤 이유로 든이 평균을 간격 중간이 아니라 끝 부분에 씁니다. 회귀를 통해 이전 값에서 마지막 값을 계산합니다.
3.2. 자동차의 계수는 상수가 아니라 임의의 변수임이 밝혀졌습니다! 당신의 편차와 함께.
3.3. 마지막 열은 표시된 cofs가 전혀 0일 확률이 0이 아닌 가능성이 있다고 말합니다.
4. 방정식으로 작업하기
무게가 실린 자동차를 살펴보겠습니다.

Masha는 kotir를 너무 단단히 덮어서 보이지 않지만 여전히 kotir와 Masha 사이에는 불일치가 있습니다. 다음은 이러한 차이점에 대한 통계입니다.

-137핍에서 215핍으로 큰 오류가 퍼진 것을 볼 수 있습니다. 표준 편차 = 20핍이지만.
결론.
회귀의 도움으로 우리는 통계 특성이 알려진 비정상적으로 고품질의 자동차를 얻었습니다.
마지막 것. 유수프! 트램 아래로 올라가지 말고 한 지점에서 청중을 즐겁게하지 마십시오.
주제 회귀의 문헌 및 적용에 대해 논의할 준비가 되었습니다.
3. 결과.
우리는 어떤 결과를 보고 있습니까?
3.1. 우선, 마샤 방정식 자체. 동시에 한 가지 뉘앙스를 기록합니다. 평균을 가르치는 간단한 mashka를 계산할 때 어떤 이유로 든이 평균을 간격 중간이 아니라 끝 부분에 씁니다. 회귀를 통해 이전 값에서 마지막 값을 계산합니다.
3.2. 자동차의 계수는 상수가 아니라 임의의 변수임이 밝혀졌습니다! 당신의 편차와 함께.
3.3. 마지막 열은 표시된 cofs가 전혀 0일 확률이 0이 아닌 가능성이 있다고 말합니다.
1. 상처에 소금을 한 번 더 뿌려서 죄송합니다. 원래 시리즈는 여전히 고정되어 있지 않습니다.
2. 이 확률은 거의 항상 0이 아닙니다.
3. 다중공선성을 확인하셨나요? 다중 공선성을 제거하면 IMHO는 하나의 변수만 남습니다. 중요한 요소를 식별했습니까?
4. 5개의 변수에 대해 몇 개의 관측치가 있습니까?
그는 어떻게 그렇게 똑똑합니까?
1. 상처에 소금을 한 번 더 뿌려서 죄송합니다. 원래 시리즈는 여전히 고정되어 있지 않습니다.
당연하지만 우리는 다른 사람들에게 관심이 없습니다.
2. 이 확률은 거의 항상 0이 아닙니다 .
사실이 아니다. 0이 아니면 함수형 오류
3. 다중공선성을 확인하셨나요? 다중 공선성을 제거하면 IMHO는 하나의 변수만 남습니다. 중요한 요소를 식별했습니까?
'중요한 요인'이 무엇인지 잘 모르겠지만 계수의 상관관계를 살펴보길 바란다.
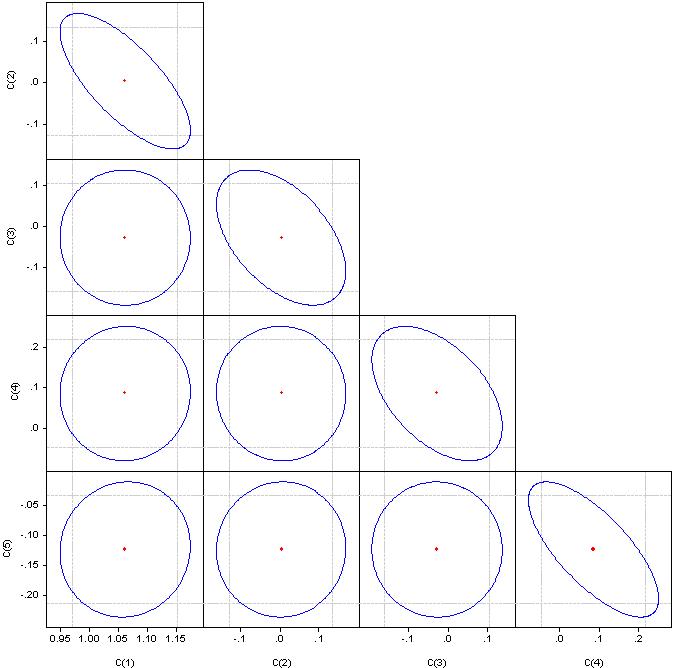
원인 경우 - 상관 관계는 0입니다. 직선으로 병합되면 해당 계수 쌍 간의 상관 관계는 100%입니다.
4. 5개의 변수에 대해 몇 개의 관측치가 있습니까?
관찰 6736
회귀 모델 의 첫 번째 단계는 요인 선택입니다. 단계적 회귀(포함 또는 제외 포함)를 사용하지 않는 경우 수동으로 선택해야 합니다.
다중 공선성 - 단단함 탐닉 ~ 사이 모델에 포함된 요인 기능. 계수의 상관관계가 아니라 요인의 상관관계입니다.
다중 공선성의 존재는 다음을 초래합니다.
- 가치의 왜곡 매개변수 모델, 어느 가지다 경향 과장되게;
- 정규 방정식 시스템의 약한 조건성;
- 복잡 프로세스 정의 최대 중요한 요인 특성.
다중 공선성의 지표 중 하나는 0.8의 쌍 상관 계수의 초과입니다. 여기에서 요인들은 분명히 강한 상관관계를 가지고 있습니다. 그것을 제거하려면 초과 요소를 버려야합니다. 수동 또는 단계적 회귀.
패키지를 살펴보십시오 - 단계적 회귀 또는 능선 회귀.
그리고 6736/4는 관측치가 너무 많습니다. 구글링을 해야 한다 - 요인의 수에 따라 최적의 관측치가 어떻게 결정되는지 기억이 나지 않는다.
내 계량 경제학 주제에 참여할만큼 친절하십시오.
문학 선택을 계속합시다.
다음 주제는 Almon의 로그 입니다.
위에서 언급했듯이 최소 자승법으로 계산된 회귀 계수에는 어려움이 있습니다. 위의 방정식에서와 같이 종속 변수가 독립 변수의 여러 시차 값에 의해 결정되는 회귀 계수에 대한 추가 제한을 부과하는 아이디어가 발생했습니다.
아이디어는 다음과 같습니다. 일부 다항식 분포를 따르는 방식으로 지연 값에서 계수에 제한을 적용합니다. EViews에서 이 접근 방식을 "분산 지연 다항식(PDL)"이라고 합니다. 다항식의 특정 차수의 선택은 실험적으로 결정됩니다.
이 접근 방식은 여기 에 설명되어 있습니다.
실제적인 예를 들어드리겠습니다.
주기가 5인 매쉬의 유사체를 만들어 보겠습니다. 그러나 막대의 계수는 3차 다항식에 있어야 합니다.
EViews에서는 EURUSD에 대해 다음과 같이 작성됩니다.
EURUSD PDL(EURUSD(-1), 5.3)
더 친숙한 방법으로:
EURUSD = + C(5)*EURUSD(-1) + C(6)*EURUSD(-2) + C(7)*EURUSD(-3) + C(8)*EURUSD(-4) + C(9 )*EURUSD(-5) + C(10)*EURUSD(-6)
최소 제곱법을 사용하여 계수를 평가하고 계수 평가 결과를 얻습니다.
EURUSD = + 0.934972661616*EURUSD(-1) + 0.139869148138*EURUSD(-2) - 0.093599954464*EURUSD(-5*0USD0-0.026499USD0-0.02649USD-92987207*EURUSD(USD8) )4-83238(-54)38
방정식 평가 통계는 다음과 같습니다.
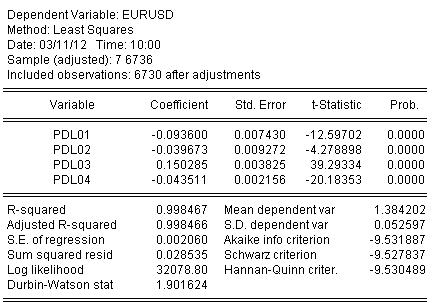
통계에서 우리는 Almon's mach R-square = 0.998467로 원래 인용문을 매우 잘 표시한 것을 볼 수 있습니다.
그래픽으로 다음과 같습니다.

회귀(Almon으로 표시)는 원래 인용문을 완전히 닫았습니다.
그리고 마지막 꿀 한숟가락.
나머지가 무엇인지 봅시다. Almon의 mashka와 원본 인용의 차이점. 이 나머지의 정상성/비정상성은 매우 중요합니다.

단위근 검정은 나머지가 정상임을 나타냅니다.
우리가 사용하는 마스크는 원문과의 대응 정도와 피팅 오차의 고정성 속성이 없습니다.
다음 지점에서 링크를 이전하고 싶습니다.
이러한 참조는 가장 문제가 되는 영역인 예측과 관련이 있습니다.
첫 번째는 첨부 파일입니다. 참고문헌이 있다.
" 계량 경제학 " 이라는 단어를 구글에 검색하면 전문가도 이해하기 힘든 방대한 문헌 목록을 얻을 수 있습니다. 한 책에는 한 책이, 다른 책에는 다른 책이, 세 번째 책에는 일부 부정확한 첫 번째 책이 편집되어 있습니다. 그러나 연상의 "책에서" 접근하는 것은 실제로 이러한 책을 적용 하는 것이 명확하지 않습니다 . 나는 식물의 눈보라로 변하는 철학에는 관심이 없습니다.
예를 들어 통계에 관한 이 포럼의 다른 책 목록과 유사하게, 참가자의 의견으로는 경제 데이터 측정 - 계량 경제학. 동시에 수학적 통계는 계량 경제학의 언니라는 것을 잊지 말자. 나는 이 목록에 기술적 분석과 관련된 모든 것을 포함하지 않을 것을 제안합니다.
식물학에 빠지지 않기 위해 나는 목록에 대한 구체적인 접근 방식과 참고 문헌 목록의 순서를 제안합니다. 이 책의 알고리즘을 구현하는 프로그램이 알려진 경우에만 링크(책 자체)를 게시합니다. 나 자신을 위해 이 범위를 크게 좁히고 EViews를 프로그램으로 사용했습니다. 이 프로그램은 다른 프로그램에 비해 장점이 없고 장점과 단점이 있지만 계량경제학의 기준점으로 삼고 있습니다. 첨부 파일에 사용자 매뉴얼 2권의 목차를 첨부하여 가능한 한 광범위한 문제를 즉시 요약했습니다. 제안된 접근 방식으로 인해 계량경제학에서 사용되지만 EVIEWS에는 포함되지 않은 여러 방향(예: NN, 웨이블릿 등)이 누락되었습니다. 당연히 유사한 프로그램과 그에 대한 책에 대한 링크도 환영합니다.
소스, 알고리즘에 대한 링크를 제공할 뿐만 아니라 특정 계산을 수행할 수 있다면 이 분기에 대한 가격은 없을 것입니다.
그룹 책에 첨부된 장 번호를 사용하는 것이 좋습니다.
따라서 지원하십시오 .