記事"指数平滑法を用いた時系列予測"についてのディスカッション
迷路のようなコードを通り抜けることはできないが、比較してみたい。
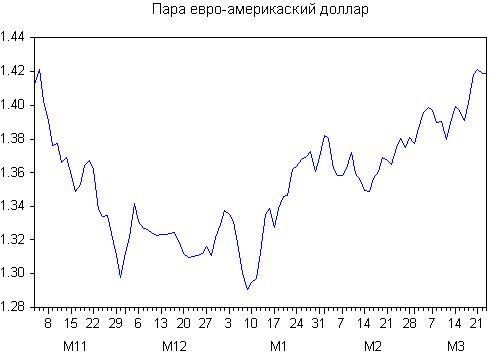
最初の見積もり
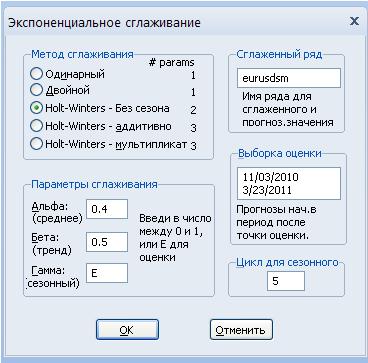
以下のスムージングのバリエーションがあります:
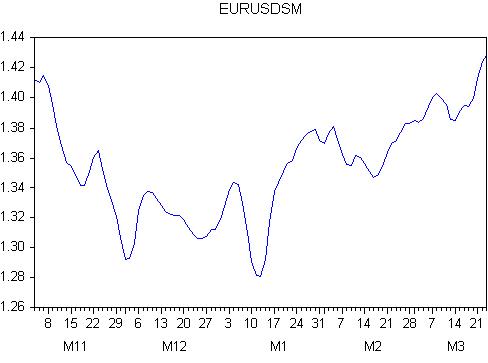
スムージング結果
回帰式
eurusd = c(1)*eurusdsm(-1) + c(2)*trend + c(3)
回帰式の推定
| 変数 | 係数 | Stand.osh. | t 統計量 | 確率 |
| EURUSDSM(-1) | 0.759607 | 0.049127 | 15.46225 | 0.0000 |
| REND | 0.000207 | 5.79E-05 | 3.577804 | 0.0005 |
| C | 0.314884 | 0.065276 | 4.823886 | 0.0000 |
R二乗 = 0.788273
回帰の標準誤差 = 0.015172
得られた数値から、以下のことがわかる:
すべての回帰係数が有意である(それらの係数がゼロと等しくなる確率はゼロに等しい)。
回帰が分散の78%を説明することを示す、かなり高い(しかしあまり高くない)R2乗。
標準誤差は151ピップス。これは大きな数字だ。
この結果の数字は信用できるでしょうか?
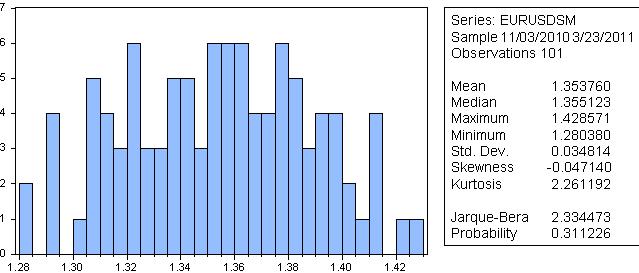
Jarque-Beraによると、平滑化された系列が正規分布を持つ確率は31%である。
予測をしてみよう:
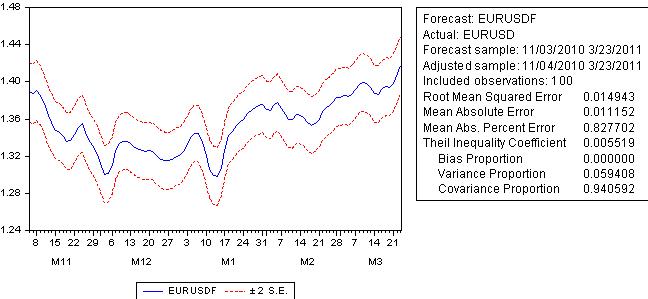
予測誤差は回帰誤差に遠く及ばず、100ピップを超えます。
予測誤差のグラフを見てみよう:
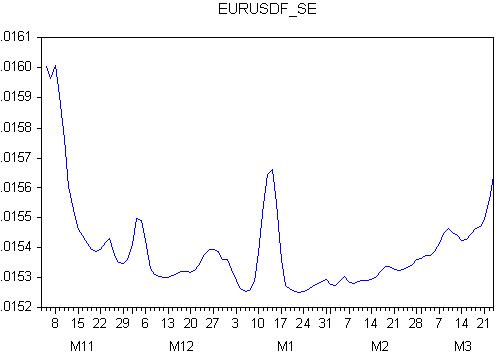
さて、これで完全終了です。誤差は変動しており、予測の将来の挙動が不明であることを意味します!
その理由を知るために、回帰式の係数の相関を見てみましょう:
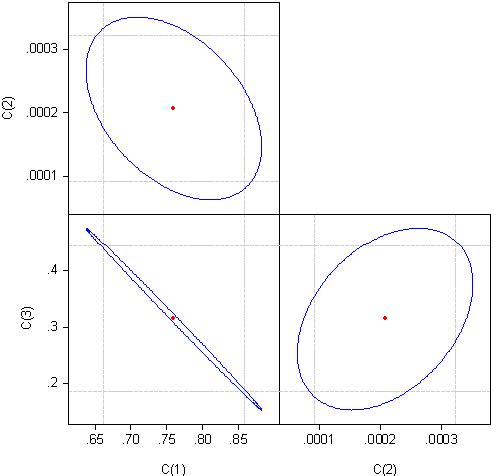
係数c(1)とc(3)はほぼ100%相関していると考えることができる。
私の結論は、予測に指数 平滑化は使えないということです。
なぜ結果が異なるのでしょうか?
あなたが発見した最適なパラメータは、些細なフィッティングに過ぎないことは明らかです。回帰自体が絶望的で、その係数は相関しています。
あなたが見つけた最適なパラメータは、些細なフィッティングに過ぎないことは明らかです。回帰自体が絶望的で、その中の係数は相関している。
論文に興味を持っていただきありがとうございます。
どういう意味か明確にしてください。どのような結果が収束せず、最適なパラメータは何ですか?
どういう意味ですか?
失礼、あなたは使えると言うが、私の結論は使えないということだ。
あなたの文章では、「回帰式:eurusd= c(1)*eurusdsm(-1) +c(2)*trend+c(3)」となっています。この記事は指数平滑化モデルについて書かれているのに、なぜ回帰式なのでしょうか?
盲人と聾唖者の会話にはならない。先送りにしよう。
良い記事をありがとう。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 指数平滑法を用いた時系列予測 はパブリッシュされました:
作者: Victor