カオスにはパターンがあるのか?それを探してみよう!特定のサンプルを例にした機械学習。 - ページ 18 1...111213141516171819202122232425...32 新しいコメント Aleksei Kuznetsov 2023.01.15 13:51 #171 Aleksey Vyazmikin #:ランダムは固定 :)このシードはトリッキーな方法で計算されているようです。つまり、モデル構築に許容される すべての予測変数がおそらく関与して おり、それらの数を変更すると選択結果も変更されます。 開始シードは固定です。そして、HSCが呼び出されるたびに新しい数字が現れる。それが、予測変数の数とDSTの数が異なると、予測変数の数がいっぱいのときと同じ予測変数にならない理由です。 Aleksey Vyazmikin#: なぜこのようなフィッティングに なるのでしょうか?私は、試験と訓練というよりも、試験とテストサンプルが異なっている、つまり予測変数の確率分布が異なっていると考えがちです。 つまり、予測変数の確率分布が異なるということです。最高の試験に基づいて予測因子を選択します。しかし、それは試験においてのみベストなのです。 Aleksey Vyazmikin#: err_"メトリクスとは何ですか? err_ oob - OOB (試験)のエラー、 err_trn - 訓練のエラー。この式では、両サンプルサイトに共通する誤差が得られます。 ところで、議論の中で、我々は試験とテストを入れ替えた。当初は、中間チェックを試験で、最終チェックを試験で行う予定だった。しかし、名前を変えたとはいえ、文脈から何が何であるかは明らかである。 Aleksey Vyazmikin 2023.01.15 14:32 #172 elibrarius #:開始番号は固定されている。そして,DSTを呼び出すごとに新しい番号が現れる.したがって,予測変数の数とDSTの数が異なると,予測変数の数がいっぱいのときと同じ予測変数にはならない.訓練に使用される予測子が同じ数のままであれば、バリアントはそこで再現される。elibrarius#: まあ、あなたは試験で最も良い変種を取り、それが試験で良いことを望みます。予測変数は最高の試験で選択されます。しかし、それらは試験のためだけに最適なのです。たまたま、このバリアントが最もバランスが取れており、テストでも試験でもそこそこの利益がありました。下の写真は、最初に選択されたモデル「Was」と、10kトレーニング後の最もバランスの取れたモデル「Became」です。一般的に、結果はより良く、より少ない予測変数が使用され、ノイズが除去されています。そして、ここで問題となるのは、トレーニングの前にこのノイズをどのように避けるかということです。 そして、トレーニングはテスト上で停止するので、トレーニングに全く参加しないサンプルよりも、そこでポジティブな結果が出る可能性が高いはずであり、後者に重点を置くというようなロジックになります。elibrarius#: err_ oob - OOBのエラー(あなたは試験を受けている), err_trn - trnのエラー。式によって、我々は両方のサンプルサイトに共通するいくつかのエラーを取得します。つまり、"err "がどのようにカウントされるのかわからない。また、なぜテストではなく試験なのでしょうか?基本的なアプローチでは、試験ではわからないからです。エリブラリウス#: ところで、私たちは議論の中でテストと試験を入れ替えました。当初、中間テストはテスト、最終テストは試験とする予定でした。しかし、名前を変えたとはいえ、文脈から何が何であるかは明らかです。私は何も変えていない(もしかしたら、どこかで自分のことを説明してしまったかもしれない?)。ただ、on trainはトレーニング、testはトレーニングを止めるコントロール、そしてexamはトレーニングとは関係のないセクション、ということだ。私は、平均利益を含むすべてのモデルの平均によってアプローチの有効性を評価しているだけです - それは良い結果を持つエッジよりも得られる可能性があります。 Aleksei Kuznetsov 2023.01.15 15:53 #173 Aleksey Vyazmikin #: 。 どうやらできないようだ。これは、ノイズをフィルタリングし、正しいデータから学習するタスクです。 Aleksey Vyazmikin#: つまり、"err "がどのように考慮されているのかわからないということです - Accuracyでしょうか? それは、テストによるトレーンの誤差を合計/要約する方法です。どんな種類のエラーでも合計することができる。そして(1-accuracy)、RMS、AvgRel、AvgCEなど。 Aleksey Vyazmikin#: 私は何も変えていません(多分、どこかで自分自身を説明 したのでしょうか?)-それはそのようなものです - 訓練 - 訓練、テスト - 訓練を停止するコントロール、試験 - 訓練のいかなる種類にも関与しないセクション。 写真を見る限り、試験とはテストのことだと思った。 例えばここ。 そして上の表では、試験の結果がテストよりも良い。確かにその可能性はあるが、本来は逆であるべきだ。 Aleksey Vyazmikin 2023.01.15 16:07 #174 elibrarius #:どうやら違うようだ。ノイズを断ち切り、正しいデータから学ぶことが課題なのだ。 いや、何か方法があるはずだ。そうでなければ、すべてが無意味でランダムなのだから。 エリブラリウス#: これは、テストによるトレーンの誤差を合計する方法です。あらゆる種類の誤差を合計することができます。(1-accuracy)、RMS、AvgRel、AvgCE など。 私のデータではうまくいきませんが、少なくとも何らかの相関はあるはずです :) elibrarius#: 写真を見る限りでは、試験というのは を意味するようだ。 そして上の表では、試験結果はテストよりも良い。 そう、試験の方がモデラーにとってより多くの収入を得られる可能性が高いことがわかった。 残念なことに、ある時点でサンプル(行)の合計を間違えてしまい、2022年の例題が電車の中にあることに気づいた。 全体像が変わるかどうか見てみよう。 Aleksei Kuznetsov 2023.01.15 16:17 #175 Aleksey Vyazmikin #: 残念なことに、ある時点でサンプル(行)の合計を間違えていたことに気づいた。 数週間後には結果が出ると思うので、全体像が変わるかどうか見てみよう。 試験で評価されたか、テストで評価されたかという違いはない。重要なのは、トレーニングでも最初の査定でも、査定サイトが使われなかったということだ。 2週間。その体力には驚かされる。私も3時間の計算にはイライラする......。それに、すでにMOに合計5年費やしていますが、あなたと同じくらいです。 要するに、定年退職後に何かを稼ぎ始めるんだ ))))たぶんね。 Aleksei Kuznetsov 2023.01.15 16:35 #176 Aleksey Vyazmikin #:残念なことに、ある時点で全体のサンプル(行)を混ぜてしまったことに今気づいた。 私はすべてを1つの連続した配列にまとめました。そして、そこから適切な量を分離しています。そうすれば何も混ざらない。 Aleksey Vyazmikin 2023.01.15 17:06 #177 elibrarius #:試験で評価されたか、テストで評価されたかに違いはない。重要なのは、トレーニングでも最初の査定でも、査定サイトが使用されなかったということだ。 私は、マキシムのように最終的なトレーニングを行うのがよいのか、あるいは、コントロールのために前時代的なサンプルを取るのがよいのか、あるいは、最高のモデルの平均のように、利用可能なサンプル全体を取り、木の本数を制限するのがよいのか、疑問に思っている。 elibrarius#: 2週間...あなたの体力には驚かされます。私も3時間の計算はイライラします...。MOに費やした時間は5年で、あなたと同じくらいです。 もちろん、より早く結果を出したいという気持ちは常にある。私は、自分の計算が他のことの邪魔にならないようにハードウェアに負荷をかけるようにしている。並行して、他のアイデアをコードに実装することもできます。コードでチェックする時間よりも、アイデアを思いつく方が早いのです。 エリブラリウス#: 要するに、私たちは引退後に何かを稼ぎ始めるということです。)そうかもしれない。 そうだね。ゆっくりではあるけれど、研究の進展が見られなかったら、今頃は仕事を終えていたかもしれない。 Aleksey Vyazmikin 2023.01.15 17:10 #178 elibrarius #:私はすべてを1つの連続した配列に糊付けしている。そして、その配列から適切な量を取り分けている。そうすれば何も混ざらない。 そう、サンプルをバイナリファイルに変換し、スクリプトの中に、どうやらサンプルを混ぜる役割をするチェックボックスを偶然に入れてしまったんだ - だから問題ないんだ。CatBoostは3つの別々のサンプルを必要とする - 彼らはクロスバリデーションを内蔵しているが、行の範囲で選択をしなかった。 Aleksei Kuznetsov 2023.01.15 19:09 #179 Aleksey Vyazmikin #:また、マキシムのように最終的なトレーニングを行うのがいいのか、あるいは、コントロールのために前時代的なサンプルを取るのがいいのか、あるいは、最良のモデルの平均のように、利用可能なサンプル全体を取り、木の数を制限するのがいいのか、迷っています。私にとって、事前訓練とテストは、平均的に最適なハイパーパラメータ(木の数など)と予測子を選択する機会です。また、テストがなくても、トレーン上でそれらをトレーニングし、すぐに取引に入ることができます。前時代的なサンプリングのアイデアは、パターンが変化しなければうまくいくでしょう。しかし、変化するリスクもある。だから私はリスクを取らず、将来のサンプリングでテストすることを好む。 もう一つの疑問は、この前史時代のサンプルは何年前のものなのかということだ。半年前ならうまくいくかもしれないが、15年前の市場は今と同じではない。しかし、確実ではない。もしかしたら、何十年も続いているパターンがあるかもしれない。 Aleksey Vyazmikin 2023.01.27 10:51 #180 ここで 説明したのと同じアルゴリズムを使って得られた結果を説明するが、サンプルはミックスされていない、つまり年代順のままである。私が変更した唯一のことは、10000モデルのトレーニングが、除外された予測変数が含まれるサンプル全体ではなく、除外された予測変数の列が削除された再形成されたサンプルで実行されたことです。これらの変更により,予測変数のスクリーニングの6ステップを一貫して実行することができました. 図1: サンプルのすべての予測変数で100個のモデルをトレーニングした後のサンプル試験の利益のヒストグラム。 図 2: 選択された標本予測変数で10kモデルを学習した後の試験標本での利益のヒストグラム - ステップ1. 図3: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルでの利益のヒストグラム - ステップ2. 図4: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益のヒストグラム - ステップ3. 図5: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益のヒストグラム - ステップ4. 図6: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益ヒストグラム - ステップ5. 図7: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益ヒストグラム - ステップ6. 図8 予測変数(特徴量)の数が減少するにつれて、後続のサンプルを形成するために選択されたモデルの特徴を持つ表。予測変数選択の第6ステップで得られた以下の特徴を持つモデルを考えよう.図 9: モデルの特性 図10.X軸はモデルから得られた確率、Y軸は全サンプルに占める割合。 図11.試験サンプル上のモデルのバランス。ここで,予測変数選択のステップ6で得られたそこそこ良いモデルと極端に悪いモデルの予測変数を比較してみよう.図12.モデルの特徴の比較これで、どの予測変数が財務結果に悪い影響を与え、トレーニングを台無しにするかがわかるでしょうか? 図13.つのモデルにおける予測変数の重みづけ.図13は、利用可能な予測変数が1つを除いてほとんどすべて使用されていることを示しているが、これが問題の根源であるとは思えない。つまり,使用量の問題というよりも,モデルを構築する際の使用順序の問題ではないだろうか?指数の代わりに有意性の序数を割り当てて2つの表を比較し、この有意性がモデル中でどのように異なる順位にあるかを見てみました。 図 14: 2つのモデルでの予測変数の有意性(使用)を比較した表.よりよく可視化するためのウェルとヒストグラム - マイナスの偏差は,2番目の(不採算)モデルの予測変数が後で使用されたことを意味し,プラスは早く使用されたことを意味する. 図 15.モデル中の予測変数の有意性の偏差.強い乖離があることがわかるが、多分これがそうなのだろう。おそらく、モデルをベンチマークと比較する複雑なアプローチが必要でしょう。全体的なバイアスを記述するための交絡指数はありますか?おそらく、最初のモデルの予測変数の有意性を考慮に入れます。どのような結論が導き出せるでしょうか?私の推測はこうです:1.結果は過去のサンプルの方がはるかに良かった。これはサンプルの年代を混ぜることによって、未来からの出来事に関する情報が「漏れた」ためだと推測される。混ざったサンプルで得られたモデルがより安定したものになるのか、それとも通常のサンプルで得られたモデルがより安定したものになるのかが問題である。2.予測変数の有意性の構造を構築することは、予測変数のモデルへの応用のために必要である。 1...111213141516171819202122232425...32 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
ランダムは固定 :)このシードはトリッキーな方法で計算されているようです。つまり、モデル構築に許容される すべての予測変数がおそらく関与して おり、それらの数を変更すると選択結果も変更されます。
開始シードは固定です。そして、HSCが呼び出されるたびに新しい数字が現れる。それが、予測変数の数とDSTの数が異なると、予測変数の数がいっぱいのときと同じ予測変数にならない理由です。
なぜこのようなフィッティングに なるのでしょうか?私は、試験と訓練というよりも、試験とテストサンプルが異なっている、つまり予測変数の確率分布が異なっていると考えがちです。
つまり、予測変数の確率分布が異なるということです。最高の試験に基づいて予測因子を選択します。しかし、それは試験においてのみベストなのです。
err_"メトリクスとは何ですか?
err_ oob - OOB (試験)のエラー、 err_trn - 訓練のエラー。この式では、両サンプルサイトに共通する誤差が得られます。
ところで、議論の中で、我々は試験とテストを入れ替えた。当初は、中間チェックを試験で、最終チェックを試験で行う予定だった。しかし、名前を変えたとはいえ、文脈から何が何であるかは明らかである。
開始番号は固定されている。そして,DSTを呼び出すごとに新しい番号が現れる.したがって,予測変数の数とDSTの数が異なると,予測変数の数がいっぱいのときと同じ予測変数にはならない.
訓練に使用される予測子が同じ数のままであれば、バリアントはそこで再現される。
まあ、あなたは試験で最も良い変種を取り、それが試験で良いことを望みます。予測変数は最高の試験で選択されます。しかし、それらは試験のためだけに最適なのです。
たまたま、このバリアントが最もバランスが取れており、テストでも試験でもそこそこの利益がありました。下の写真は、最初に選択されたモデル「Was」と、10kトレーニング後の最もバランスの取れたモデル「Became」です。一般的に、結果はより良く、より少ない予測変数が使用され、ノイズが除去されています。そして、ここで問題となるのは、トレーニングの前にこのノイズをどのように避けるかということです。
そして、トレーニングはテスト上で停止するので、トレーニングに全く参加しないサンプルよりも、そこでポジティブな結果が出る可能性が高いはずであり、後者に重点を置くというようなロジックになります。
err_ oob - OOBのエラー(あなたは試験を受けている), err_trn - trnのエラー。式によって、我々は両方のサンプルサイトに共通するいくつかのエラーを取得します。
つまり、"err "がどのようにカウントされるのかわからない。また、なぜテストではなく試験なのでしょうか?基本的なアプローチでは、試験ではわからないからです。
ところで、私たちは議論の中でテストと試験を入れ替えました。当初、中間テストはテスト、最終テストは試験とする予定でした。しかし、名前を変えたとはいえ、文脈から何が何であるかは明らかです。
私は何も変えていない(もしかしたら、どこかで自分のことを説明してしまったかもしれない?)。ただ、on trainはトレーニング、testはトレーニングを止めるコントロール、そしてexamはトレーニングとは関係のないセクション、ということだ。
私は、平均利益を含むすべてのモデルの平均によってアプローチの有効性を評価しているだけです - それは良い結果を持つエッジよりも得られる可能性があります。
。
どうやらできないようだ。これは、ノイズをフィルタリングし、正しいデータから学習するタスクです。
つまり、"err "がどのように考慮されているのかわからないということです - Accuracyでしょうか?
それは、テストによるトレーンの誤差を合計/要約する方法です。どんな種類のエラーでも合計することができる。そして(1-accuracy)、RMS、AvgRel、AvgCEなど。
私は何も変えていません(多分、どこかで自分自身を説明 したのでしょうか?)-それはそのようなものです - 訓練 - 訓練、テスト - 訓練を停止するコントロール、試験 - 訓練のいかなる種類にも関与しないセクション。
写真を見る限り、試験とはテストのことだと思った。
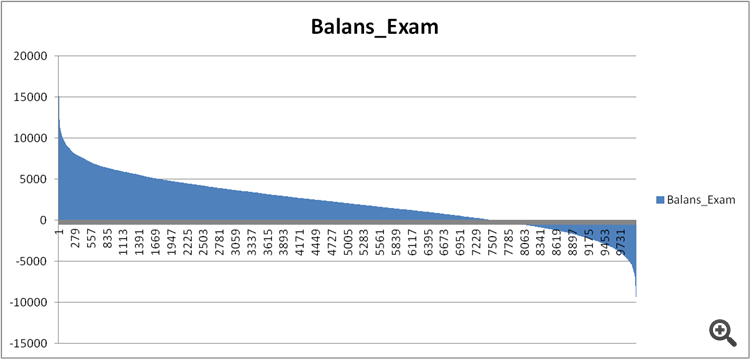
例えばここ。
そして上の表では、試験の結果がテストよりも良い。確かにその可能性はあるが、本来は逆であるべきだ。
どうやら違うようだ。ノイズを断ち切り、正しいデータから学ぶことが課題なのだ。
いや、何か方法があるはずだ。そうでなければ、すべてが無意味でランダムなのだから。
これは、テストによるトレーンの誤差を合計する方法です。あらゆる種類の誤差を合計することができます。(1-accuracy)、RMS、AvgRel、AvgCE など。
私のデータではうまくいきませんが、少なくとも何らかの相関はあるはずです :)
写真を見る限りでは、試験というのは
を意味するようだ。
そして上の表では、試験結果はテストよりも良い。
そう、試験の方がモデラーにとってより多くの収入を得られる可能性が高いことがわかった。
残念なことに、ある時点でサンプル(行)の合計を間違えてしまい、2022年の例題が電車の中にあることに気づいた。
全体像が変わるかどうか見てみよう。
残念なことに、ある時点でサンプル(行)の合計を間違えていたことに気づいた。
数週間後には結果が出ると思うので、全体像が変わるかどうか見てみよう。
試験で評価されたか、テストで評価されたかという違いはない。重要なのは、トレーニングでも最初の査定でも、査定サイトが使われなかったということだ。
2週間。その体力には驚かされる。私も3時間の計算にはイライラする......。それに、すでにMOに合計5年費やしていますが、あなたと同じくらいです。
要するに、定年退職後に何かを稼ぎ始めるんだ ))))たぶんね。
残念なことに、ある時点で全体のサンプル(行)を混ぜてしまったことに今気づいた。
私はすべてを1つの連続した配列にまとめました。そして、そこから適切な量を分離しています。そうすれば何も混ざらない。
試験で評価されたか、テストで評価されたかに違いはない。重要なのは、トレーニングでも最初の査定でも、査定サイトが使用されなかったということだ。
私は、マキシムのように最終的なトレーニングを行うのがよいのか、あるいは、コントロールのために前時代的なサンプルを取るのがよいのか、あるいは、最高のモデルの平均のように、利用可能なサンプル全体を取り、木の本数を制限するのがよいのか、疑問に思っている。
2週間...あなたの体力には驚かされます。私も3時間の計算はイライラします...。MOに費やした時間は5年で、あなたと同じくらいです。
もちろん、より早く結果を出したいという気持ちは常にある。私は、自分の計算が他のことの邪魔にならないようにハードウェアに負荷をかけるようにしている。並行して、他のアイデアをコードに実装することもできます。コードでチェックする時間よりも、アイデアを思いつく方が早いのです。
要するに、私たちは引退後に何かを稼ぎ始めるということです。)そうかもしれない。
そうだね。ゆっくりではあるけれど、研究の進展が見られなかったら、今頃は仕事を終えていたかもしれない。
私はすべてを1つの連続した配列に糊付けしている。そして、その配列から適切な量を取り分けている。そうすれば何も混ざらない。
そう、サンプルをバイナリファイルに変換し、スクリプトの中に、どうやらサンプルを混ぜる役割をするチェックボックスを偶然に入れてしまったんだ - だから問題ないんだ。CatBoostは3つの別々のサンプルを必要とする - 彼らはクロスバリデーションを内蔵しているが、行の範囲で選択をしなかった。
また、マキシムのように最終的なトレーニングを行うのがいいのか、あるいは、コントロールのために前時代的なサンプルを取るのがいいのか、あるいは、最良のモデルの平均のように、利用可能なサンプル全体を取り、木の数を制限するのがいいのか、迷っています。
私にとって、事前訓練とテストは、平均的に最適なハイパーパラメータ(木の数など)と予測子を選択する機会です。また、テストがなくても、トレーン上でそれらをトレーニングし、すぐに取引に入ることができます。
前時代的なサンプリングのアイデアは、パターンが変化しなければうまくいくでしょう。しかし、変化するリスクもある。だから私はリスクを取らず、将来のサンプリングでテストすることを好む。
もう一つの疑問は、この前史時代のサンプルは何年前のものなのかということだ。半年前ならうまくいくかもしれないが、15年前の市場は今と同じではない。しかし、確実ではない。もしかしたら、何十年も続いているパターンがあるかもしれない。ここで 説明したのと同じアルゴリズムを使って得られた結果を説明するが、サンプルはミックスされていない、つまり年代順のままである。
私が変更した唯一のことは、10000モデルのトレーニングが、除外された予測変数が含まれるサンプル全体ではなく、除外された予測変数の列が削除された再形成されたサンプルで実行されたことです。これらの変更により,予測変数のスクリーニングの6ステップを一貫して実行することができました.
図1: サンプルのすべての予測変数で100個のモデルをトレーニングした後のサンプル試験の利益のヒストグラム。
図 2: 選択された標本予測変数で10kモデルを学習した後の試験標本での利益のヒストグラム - ステップ1.
図3: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルでの利益のヒストグラム - ステップ2.
図4: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益のヒストグラム - ステップ3.
図5: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益のヒストグラム - ステップ4.
図6: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益ヒストグラム - ステップ5.
図7: 選択されたサンプル予測変数で10kモデルを学習した後の試験サンプルの利益ヒストグラム - ステップ6.
図8 予測変数(特徴量)の数が減少するにつれて、後続のサンプルを形成するために選択されたモデルの特徴を持つ表。
予測変数選択の第6ステップで得られた以下の特徴を持つモデルを考えよう.
図 9: モデルの特性
図10.X軸はモデルから得られた確率、Y軸は全サンプルに占める割合。
図11.試験サンプル上のモデルのバランス。
ここで,予測変数選択のステップ6で得られたそこそこ良いモデルと極端に悪いモデルの予測変数を比較してみよう.
図12.モデルの特徴の比較
これで、どの予測変数が財務結果に悪い影響を与え、トレーニングを台無しにするかがわかるでしょうか?
図13.つのモデルにおける予測変数の重みづけ.
図13は、利用可能な予測変数が1つを除いてほとんどすべて使用されていることを示しているが、これが問題の根源であるとは思えない。つまり,使用量の問題というよりも,モデルを構築する際の使用順序の問題ではないだろうか?
指数の代わりに有意性の序数を割り当てて2つの表を比較し、この有意性がモデル中でどのように異なる順位にあるかを見てみました。
図 14: 2つのモデルでの予測変数の有意性(使用)を比較した表.
よりよく可視化するためのウェルとヒストグラム - マイナスの偏差は,2番目の(不採算)モデルの予測変数が後で使用されたことを意味し,プラスは早く使用されたことを意味する.
図 15.モデル中の予測変数の有意性の偏差.
強い乖離があることがわかるが、多分これがそうなのだろう。おそらく、モデルをベンチマークと比較する複雑なアプローチが必要でしょう。
全体的なバイアスを記述するための交絡指数はありますか?おそらく、最初のモデルの予測変数の有意性を考慮に入れます。
どのような結論が導き出せるでしょうか?
私の推測はこうです:
1.結果は過去のサンプルの方がはるかに良かった。これはサンプルの年代を混ぜることによって、未来からの出来事に関する情報が「漏れた」ためだと推測される。混ざったサンプルで得られたモデルがより安定したものになるのか、それとも通常のサンプルで得られたモデルがより安定したものになるのかが問題である。
2.予測変数の有意性の構造を構築することは、予測変数のモデルへの応用のために必要である。