Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
В статье рассматриваются новые возможности пакета darch (v.0.12.0). Описаны результаты обучения глубокой нейросети с различными типами данных, структурой и последовательностью обучения. Проанализированы результаты.
この サンプルからさらに2年分をカットしたところ、エグザムの平均はすでに-485点(1214 点だった)、3000点制限をクリアしたモデル数は884(前回は 277)になった。
しかし、テストサンプルの結果は平均2115点から186点に、つまり大幅に悪化した。これは何なのでしょうか?テストサンプルと同じような訓練サンプルの例が少なくなっているのでしょうか?
平均樹木数は10本から7本に減少しました。
グラフ上のゼロのブレークは、バランス分布を中央にシフトしています。
結果は テストに似て いるはずだという発言の根拠は何ですか?私は、サンプルは均質ではないと仮定しています。同じような例がサンプルに匹敵する数存在するわけではありませんし、量子の確率分布も少し異なると思います。
トレーヌ 私が言っているのは、良いパターンがあるデータについてです。掛け算表の1000の変種をトレーニングに投入すると、トレーンには決してマッチしない(しかしトレーンの境界の内側にはある)新しい変種もかなり計算されます。1本の木は最も近い変種を与えるが、ランダムフォレストは100個の最も近い変種を平均し、ほとんどの場合1本の木より正確な答えを与える。
もし市場に規則性のある予測変数が見つかれば、OOSもトレースと同じようになる。しかし、今のように半分以上のモデルがマイナスで、3分の1がプラスということはない。成功したモデルはすべて、ランダムなシードから偶然そのようになった。
シードがモデルの成功をわずかに変えるだけで、一般的にはすべて成功するはずである。現在では、パターンは見つかっていない(オーバートレーニング/アンダートレーニングのいずれか)。
つまり、trainでトレーニングしている間にtestで改善が見られなければ、トレーニングは停止され、testモデルで最後に改善が見られたポイントまでツリーが削除されます。
そうすれば、なぜテストも良いのかが明らかになる。基本的にはテストに合わせるのです。私は1回のトレーニングでそれをやめました。私は、前方に向かってバービングを行い、すべてのOOCを一緒に接着し、その後、接着されたOOCの多くのバリエーションから最適なモデルのハイパーパラメータ(深さ、木の数など)を選択します。試験は、すべてのOOSを選択したグルーイングとほぼ同じになると推測している。そのバリエーションで5年以上、私は週に1回再トレーニングをしています-それは何百ものOOSトレーニングとチャンクです。
どうやら私が使用したサンプルを明確に示していなかったようだ - これはここで 説明した実験から6番目(最後)のサンプルなので、予測変数は61個しかない。
原始的な戦略、特に平坦な市場においては。さて、あなたは5000以上の中からこの61を選んだ。私の総数は少なく、選ばれた数も少ない。そして、1つずつ追加する場合、3-4個選んだ後、さらにサインを追加すると、OOSの結果が悪化するだけです。
一般的に、私は予測変数を追加することができます。なぜなら、現在3つのTFでのみ使用されているからです。
そしてもちろん、予測因子を事前にスクリーニングする必要があり、これはトレーニングをスピードアップする。
もしそれらがすべてほぼ同じであれば、結果を著しく改善するものが見つかる可能性は低い。全く新しいデータやユニークな指標を試すことができる。
予備スクリーニングも長い作業で、一度に1つずつ追加すると、3特徴まででも何倍もかかり、10特徴までなら何日もかかる。 しかし、意味がない。3-4特徴以降は、通常は改善されない。しかし、たまに改善されることもある。私の実験では、ブレークスルーは見つからなかった。
外れ値が外れ値であることは論理的であり、私はただ、これらは非効率であり、ホワイトノイズを除去することによって学習されるべきであると考えている。他の分野では、シンプルで原始的な戦略は、特に平坦な市場においては、しばしば機能する。
一番下の画像は利益を上げているが、5年間で2017年に2回だけ強い成長を遂げた時期があり(どうやら予測可能な強いトレンドがあったようだ)、モデルはこの2つの時期に最も利益を上げた。そして、長期にわたって均一な成長があるのはいいことだ。
もちろんEAを作ることもできる - ホワイトスワンを待つ。しかし、私はアクティブ・トレードを好む。
この サンプルからさらに2年をカットすると、エグザムの平均はすでに-485点(前回は-1214点)となり、3000点制限を突破したモデルの数は884(前回は 277)となっている。
しかし、テストサンプルの結果は平均2115点から186点に、つまり大幅に悪化している。これは何なのでしょうか?テストサンプルと同じような例がトレーニングサンプルに少ないのでしょうか?
平均樹木数は10本から7本に減少しました。
グラフ上のゼロのブレークは、バランス分布を中央にシフトしています。
最初の投稿のファイルを投稿してもらえますか?
トレーネ 私が言っているのは、良いパターンがあるデータのことだ。もしトレーニングのために1000の掛け算表の変種を提出すれば、トラインと決して一致しない(しかしトラインの境界の内側にある)新しい変種もうまく計算されるでしょう。1本の木は最も近い変種を与えるが、ランダムフォレストは100個の最も近い変種を平均し、ほとんどの場合1本の木より正確な答えを与えるだろう。
もし市場に規則性のある予測変数が見つかれば、OOSもトレースと同じようになる。しかし、今のように半分以上のモデルがマイナスで、3分の1がプラスということはない。成功したモデルはすべて、ランダムな種から偶然そのようになったのです。
シードがモデルの成功をわずかに変えるだけで、一般的にはすべて成功するはずだ。現在では、(オーバートレーニング/アンダートレーニングの)パターンは見つかっていない。
良いデータがあれば、すべてが完璧に機能する可能性が高いということに誰も異論はない。しかし、そのようなデータは手に入らないので、今あるものから何を絞り出すかを考えなければならない。
新しいデータに対して有効なモデルをランダムに得ることが可能であるという事実は、このランダム性をどのように減らすか、つまり、モデルが一貫して構築された量子セグメントのための規則的な測定基準があるかどうかを考えさせる。つまり、ターゲットの欲以外の追加的な測定基準について話しているのです。そのような依存関係が確立できれば、より高い成功確率でモデルを構築することができる。もちろん、これは異なるサンプルでも機能するはずである。
それなら、テストが良い理由もわかります。本質的にテストにフィットしているのです。私は1つの勉強のためにそれをやめました。私は、前方に向かって弁をつけ、すべてのOOCを一緒に接着し、その後、接着されたOOCの多くのバリエーションから最適なモデルのハイパーパラメータ(深さ、木の数など)を選択します。試験は、すべてのOOSを選択したグルーイングとほぼ同じになると推測している。5年以上かけて、私は1週間に1回再トレーニングを行い、それは何百ものOOSトレーニングとチャンクになります。
主なものは、最後の試験セクションを分離しないことです。
ハイパーパラメータをフィッティングして、その結果を何で評価するのですか?あなたの論理に従えば、それは平均化の要素を含む同じフィッティングだと思います。
CatBoostのロジックは、(Loglossによって)モデルを改善することが不可能であれば、それ以上のトレーニングは意味がないというものです。この場合、モデルが良いものになったという保証はもちろんありません。
ー5000以上のー以上からーからーからーからーからーからーからーからーからー61人ーー。ー総数とータとータ数。そして、一度に1つを追加する場合、3-4つの選択されたものの後、さらに特徴を追加すると、OOSの結果が悪化するだけです。
いえ、私が選んだわけではありません。すべての予測変数でトレーニングする際に、モデルから除外したのです。
予測モデルはのののののの() 予測モデルは.この理由から、私は量子セグメントを選択する。一般的に、私はすべての予測子をバイナリに分解することもできる。、ののフレンドリーなフレンドリーなフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリー。
それらがすべてほぼ同じであれば、結果を深刻に改善する何かがすでに見つかる可能性は低いでしょう。、、のののの馬は馬の馬の馬の馬の馬の馬の馬の馬の馬の馬の馬
"ほぼ同じ "とはどういう意味ですか?メトリクスのことでしょうか?ータをータはータをータをータをータをータ
事前審査も長い仕事です。1つ1つ機能を追加していくのは、3つまででも何倍も時間がかかりますし、10個になると何日もかかります。、、、、ー。、、フレンドリーなフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリーフレンドリー
あなたが話している変種は長いゲームであり、それが私がそれをプレーしない理由だ(まあ、私は完全な自動化を持っていない)。しかし、私は効果がないということには同意しません - 私はグループでドロップアウトを行い、グループを減らしました - 結果は肯定的でした。しかし、私はまだこれらのアクションをフィッティングまたはランダム性に帰する - 予測変数の選択に正当化はありません。
一番下の図は利益を上げているが、5年間で2017年に強い成長を遂げた2つの期間しかなく(どうやら予測可能な強いトレンドがあったようだ)、モデルはこの2つの期間で最も利益を上げた。、フレンドリーなー。、フレンドリーなー。
もちろん、エキスパート・アドバイザーを作ることもできる。しかし、私は積極的な取引を好む。
だからこそ、私はモデルのセットを使用することに賛成している。私は、それぞれが独自の頻繁ではないパターンをキャッチすることができると理解しているからだ。
一般的に、トレーンとテストの誤差がほぼ同じになるようにすることが目的です。この場合、エグザムはトレインとテストに向かう、つまり上昇し、エグザムはテストに向かう、つまり下降します。オーバートレーニングは下がる。
そして、どのような指標で両者は似ているのでしょうか?
例えば、Precision(精度)という指標を取り、この指標をtrainからtestサンプルで引くと、デルタ(y軸)が得られます。
特別な依存関係はありません。
以下は、各サンプルに対する2つのメトリクスです - データは、新しい木がモデルに追加されるときに取得されます。
このモデルの特徴は以下の通りです
そして以下は、2つのサンプルで損失を出した別のモデルの指標である。
このモデルの特徴は以下の通りです。
何度も返信をクリックして、フォーラム形式で返信するのは不便です。以下、私の回答はカラーでハイライトされています。
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> クアンタがどのように構築されるか、基本的なバリエーションをずっと前に見ました。まず、列がソートされます。
1) 範囲順、偶数ステップ(例えば0から1まで、0.1を正確に通過する値ステップで、10個のクアンタ0.1、0.2、0.3...を合計する)。0.9)
2)パーセンタイル-すなわち例数で。10個の量子で割った場合、各量子には全行数の10%を入れる。替え玉が多い場合、いくつかの量子は10%以上になる。替え玉が他の量子に入らないようにするためである。例えば、替え玉がサンプルの30%であれば、この量子にすべて入ることになる。各量子のサンプル数に応じて、分布は0.001、0.12、0.45、0.51、0.74、...となる。0.98.
3) 両方のタイプの組み合わせがある。
というわけで、量子の構成に超巧みなことは何もない。私はこの2つの量子化方法を自分で作ってみた。そしていつものように、より良いと思う方法でやった。もしかしたら間違えたかもしれない。そして私は通常、量子化せずにフロートデータで計算する。
すべての予測値を2進数にすると、2つの量子が存在することになる。1つはすべて0で、もう1つはすべて1である。
ハイパーパラメータをフィットして、その結果を何で評価するのですか?あなたの論理に従えば、平均化要素を使ったフィッティングと同じだと思います。
> バランスチャートとドローダウンを見ています。選択の自動化はまだできていません。はい、フィットはより良いOOS接着のためです。しかし、モデル自体ではなく(つまりトレースではなく)、モデルの最適なハイパーパラメータの選択です。
ほぼ同じ」とはどういう意味でしょうか?もちろん、他のデータを試すこともできますし、別のツールを使うこともできます。
> これらはすべて、価格とマッシュアップで作られています。
古い質問です。
電車と 同じような結果になるはずだ、というのは何を根拠に言っているのでしょうか?私は、サンプルが均質でないと仮定しています - 類似した例の比較可能な数はありませんし、量子の確率分布はわずかに異なると思います。
>https://www.mql5.com/ru/articles/3473
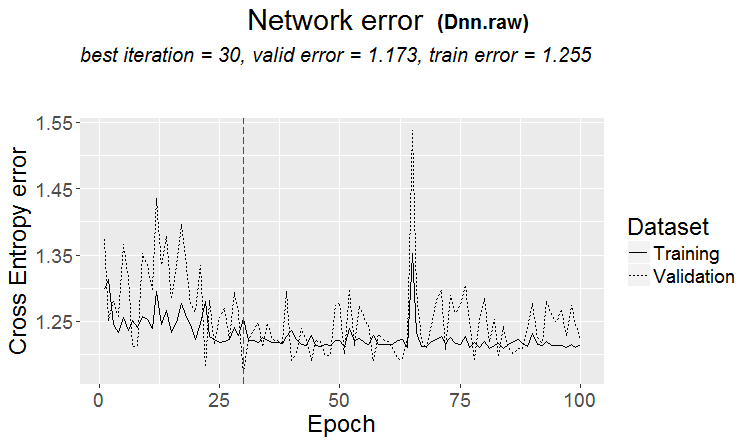
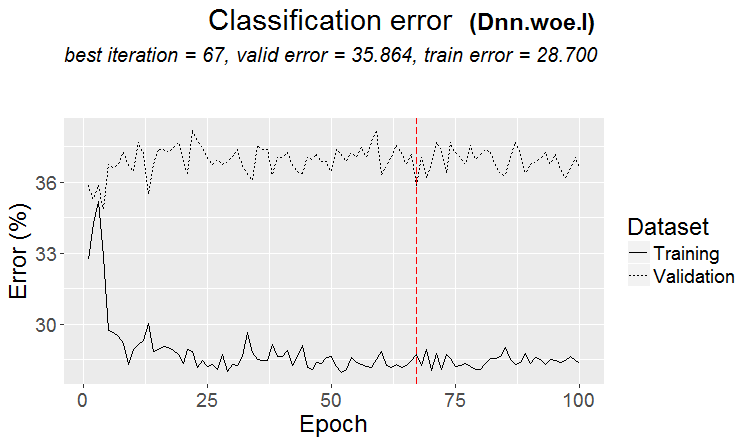
良いバリエーションは、パターンが見つかったときです:ternaryとtestはほとんど同じエラーです
市場では、より頻繁にこのようなことが起こります:良いテストですが、トレーニングのいくつかのステップの後(図では3番目のステップの後)再トレーニングが始まり、テストの誤差が大きくなり始めます。この図はニューラルネットワークの例ですが、フォレストやブーストでもこのようなことがあります。
どのような指標で似ているのでしょうか?
しかし、それはあなたの指標が悪いという意味ではありません。
だから、量子の構成に超巧みなことは何もない。私はこの2つの量子化方法を自分で作ってみた。そしていつものように、より良いと思う方法でやった。もしかしたら間違えたかもしれない。そして私は通常、量子化せずにフロートデータを使って計算する。
もちろん、さまざまな方法がある。私は今、約900の量子テーブルを使っている。
重要なのは方法ではなく、バイナリーターゲットの平均値がサンプルの平均値よりも高い予測値の範囲を選択することです(現在、私は最低5%に加え、例の数にも基準を置いています-最低5%)。もしそのような情報がなければ、数回の分割で現れることを期待できますが、可能性は低いと思います。
実際、そのようなプロットが1-2個あることはありますが、本当にたくさんあることはまれです。そして、このようなプロットだけを取ることもできますし、そのようなプロットを持つ予測だけを取り、最適な量子表を選ぶこともできます。
個人的には、少なくとも私の予測は、確率が滑らかに変化するのではなく、不連続に起こり、逆の偏差に変化する。この確率を順序立てて並べれば、モデルの訓練がしやすくなるのではないかとさえ思う。これが、有益でない領域を除外し、相反する領域を分離することに意味がある理由です。
すべての予測子をバイナリにすると、2つの量子が存在することになります。1つはすべて0で、もう1つはすべて1です。
実際には0,5が1つだけです。)しかし、この方法で予測子を有用な(潜在的に有用な情報を含む)範囲に分解することができます。
> バランスチャートとドローダウンを見ています。選択の自動化はまだうまくいっていません。そうです、フィッティングです。しかし、モデル自体ではなく(つまりトレースではなく)、モデルの最適なハイパーパラメータの選択です。
モデルのメトリクスも重要だと思います。
> これらのすべては、価格とマッシュアップで行われます。
理論的にはそうであり、ニューラルネットワークを使用する場合ですが、実際には - いいえ - あまりにも複雑な依存関係は、別の計算で検索する必要があり、これは単に一般ユーザーの計算能力を持っていません。
古い質問について。
> 例はこちらhttps://www.mql5.com/ru/articles/3473
良いバリエーションは、パターンが見つかったときです:三項とテストはほとんど同じエラーを持っています
市場では、より頻繁にこのようなことが起こります:良いテストが、いくつかのトレーニングステップの後に(図では3番目の後に)再トレーニングが開始され、テストの誤差が成長し始める。この図はニューラルネットワークの例ですが、フォレストやブーストでもこのようなことがあります。
問題はこの規則性が今後も現れるかどうかだ。
どのようなサンプルがあったのか分かりませんが。テストがトレーニングより速く学習するケースもありますが、多くの場合はその逆で、両者の間には顕著な差があります。もちろん理想的な状態であれば、その差は小さいでしょう。
サンプルがあまり似ていないため、モデルの学習が不十分であり、改善が見られない場合に学習が停止していることは確かです。
いつか、再学習されたサンプルがどのように見えるか、グラフでお見せしましょう-それは角で区切られた2つの膨らみです...。
トレーニングサンプルをさらに半分にする。
モデルは306個しかなく、試験による平均利益は-2791ポイントである。
しかし、私はこんなモデルを手に入れた。
こんな特徴がある
マットの期待値は確かに低下しているが、リコールは2倍に伸びている。
このような予測変数が使用された:
そして、サンプルより9個少ない-私は、それらだけを取って、サンプル全体(全列車線)で訓練してみる。
分割は量子までしか行われない。量子の内側はすべて同じ値とみなされ、それ以上分割されることはありません。なぜ量子に何かを求めているのか理解できません。量子の主な目的は計算をスピードアップ することです(副次的な目的は、それ以上の分割がないようにモデルをロード/一般化することですが、フロートデータの深さを制限すればいいだけです)私は使っていません。65000のパーツで定量化を行ったが、結果は定量化なしのモデルとまったく同じだった。
個人的には、少なくとも私の予測モデルは、確率の遷移がスムーズではなく、むしろ突然起こり、逆の偏差に変化することがわかりました。
また、こんなことにも気づいた。深さを1増やすと収益性が劇的に変化し、あるときは+に、あるときは-になる。
実際、-0.5が1回ある。)しかし、こうすることで、プレディクターを有用な(潜在的に有用な情報を含む)範囲に分割することが可能になります。
データを2つのセクタに分割する1つの分割があり、一方はすべて0で、もう一方はすべて1です。クオンタと呼ばれるものが何なのか分かりませんが、クオンタは定量化後に得られるセクタの数だと思います。もしかしたら、あなたのおっしゃるように分割の数かもしれません。