記事についてのディスカッション - ページ 3 12345678 新しいコメント Aleksey Vyazmikin 2020.11.11 11:08 #21 Andrey Dibrov: 同じ実験を繰り返し、トレーニングサンプルにもう1、2ヶ月の履歴を追加し、2つのテストを比較してみてください。ニューラルネットワークが安定したままかどうか、最近の値動きがこのモデルにどのような影響を与えるか...。 これはニューラル・ネットワークではなく、グラディエント・ブースティング であり、パターンを見つけるための全く異なるアプローチである。 短いサンプルではデータが少ないと確信しているが、読者の好奇心を満たすために今サンプルをトレーニングしている: 1.木の本数を変えた1年間のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない) 2.樹木の数を変えた3年目のウィンドウ - 結果を比較してみましょう。(対照サンプルは使用しない) 3.毎月新しいデータが追加され、木の本数が異なる1年間のウィンドウ - 結果を比較してみましょう。(コントロール・サンプルは使用しない) 計算処理が完了するまで待つ必要があります - 多くのモデルが構築されています。 Valeriy Yastremskiy 2020.11.11 11:25 #22 Aleksey Vyazmikin:抽象論から数字に移ろう。小窓の効果はどの程度か?重要なのは、あなたは市況に飛びつくことを提案しているが、私はさまざまな市況に関する知識を使うことを提案しているということだ。歴史に裏打ちされた知識が多ければ多いほど、その上に構築されたパターンの変化は遅くなる。 それから、小さなサンプルでどのようにハイパーパラメーターを定義するのか。私はどこでも同じだと考えている。 その幅は、少なくとも安定した状態の幅と同じでなければなりません。私はそれを提案しているわけではない。学習は安定した状態において生産的であるという規定から考えた。つまり、安定したBP状態での学習結果は、同じ量のデータでの学習結果よりも良くなるが、BP状態は異なる安定状態のいくつかのセグメントで構成される。 Aleksey Vyazmikin 2020.11.11 11:33 #23 Valeriy Yastremskiy:その幅は、少なくともあなたが利益を上げられる安定した状態の幅と同じくらいでなければならない。私はこれを提案しているわけではない。条文から考えられるのは、学習は安定した状態で効率的に行われるということだ。つまり、安定したBP状態での学習結果は、同じ量のデータで学習するよりも良いが、BP状態は異なる安定した状態のいくつかのセグメントから構成される。 したがって、新しい市場状態を検出できて初めて最適な幅を見つけることができる。 なぜなら、データ収集は特定の市場状態に基づいており、状態間のバーの数は異なるからです。 Andrey Dibrov 2020.11.11 13:22 #24 Aleksey Vyazmikin:注意してほしいのは、これはニューラルネットワークではなく、勾配ブースティング(gradient bousting)という、パターンを見つけるためのまったく異なるアプローチだということだ。短いサンプルではデータが少ないと確信しているが、読者の好奇心を満たすために今サンプルをトレーニングしている:1.木の本数を変えた1年間のウィンドウ - 結果を比較してみよう。(結果を比較してみよう。)2.樹木の数を変えた3年目のウィンドウ-結果を比較してみよう。(対照サンプルは使用しない)3.毎月新しいデータが追加され、木の本数が異なる1年間のウィンドウ - 結果を比較する。(コントロール・サンプルは使用しない)計算プロセスが完了するまで待つ必要がある。 その通りだ。私にとって興味深い問題は、ニューラルネットワークを訓練するためにデータをサンプリングするパターンを探すために、グラディエント・ブースティングが 使えるかどうかということだ。これは、さまざまな市場パターンで訓練されたニューラルネットワークを使ってヘッジ取引をするための解決策を見つけるという問題だ... Aleksey Vyazmikin 2020.11.11 13:44 #25 Andrey Dibrov:その通りだ。私にとって興味深い疑問は、ニューラルネットワークを訓練するためにデータをサンプリングするパターンを探すために、グラディエントブースティングを使えるかどうかということだ。これは、さまざまな市場パターンで訓練されたニューラルネットワークを使ってヘッジ取引をするための解決策を見つけるという問題だ...サンプルでニューラルネットワークの実験をすることなく、どうやってこの問題に対する答えを得るつもりですか?例えば、"外の何か "からの終値のパーセンテージなどです。チャート上で、バイアスが行(サンプルの各行N行)にわたって変化しているのがわかります。サンプルの1/10を取ると、インジケータが横に動いたときに十分な情報が得られません(例えば、上のTFのグローバルトレンドに依存します)。 ちなみに、図は SatBoost グリッドの形でデータがどのように分割(定量化)されているかを示しています。 Aleksey Vyazmikin 2020.11.11 16:12 #26 今のところ、最初のバージョンはできている: 1.木の本数が異なる年のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない) 400本では不十分であり、1600本では過剰である。 曲線のダイナミクスは似ています。 Valeriy Yastremskiy 2020.11.11 16:28 #27 Aleksey Vyazmikin:第一稿はとりあえずできた:1.木の本数が異なる年のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない) 400本では不十分であり、1600本では過剰である。曲線のダイナミクスは似ています。 200本では十分な情報が得られず、1600本では情報が失われるか、重要な情報が特定できない。 Aleksey Vyazmikin 2020.11.11 19:47 #28 Valeriy Yastremskiy:200は情報が欠けており、1600は情報が失われているか、重要な情報が特定されていない。 トレーニングのための情報は安定して同じですが、条件を記憶するためのメモリサイズは異なります。私は、最初の10本の木の類似性がモデルの動作の基本的な論理を決定し、それ以上はその改良があるだけだと考えている。 Aleksey Vyazmikin 2020.11.11 21:21 #29 2.木の本数を変えた3年目のウィンドウ-結果を比較する。(対照サンプルは使用していない) 繰り返しになるが、800回の反復が最適であることがわかる。混乱しているのは、2020年3月に強い失敗があることです。これは、モデルを超えた危機の影響なのか、それともサンプリング・エラーなのか分かりませんが、私はグルーイングで学習を行ったので、新しい先物契約への移行によるギャップがあるのかもしれません。ポジティブな面では、学習は12ヶ月の場合よりも明らかに優れている(最後のチャートでこの期間を参照!)。 3. 毎月新しいデータを追加し、ツリーの数を変えて1年間のウィンドウを表示します。(コントロール・サンプルは使用しない) この図から、400回の反復によるモデルの成長の方が速いか、一直線であることがわかりますが、サンプル・サイズが大きくなるにつれて傾向が変わり、800回の反復によるモデルの方が誤差が少なく、月次クローズも良好で、引き離され始めました。どうやら、モデルサイズを動的に大きくする必要があるようです。 この研究から、論文で概説された方法と得られた結果は偶然の産物ではないと結論づけることができる。 たしかに、価格行動に大きな変化があり、古い行動が繰り返されるわけではなく、それに応じて、大きな期間にわたってサンプリングすると、新しいデータで儲けることができなくなることには同意します。モデル上の価格行動のばらつきを特定することは今後の研究課題ですが、私は多少古いとはいえ、できるだけ多くの価格情報を使うことを好みます。 Aleksey Vyazmikin 2020.11.11 23:15 #30 下図はリコールに関する情報であり、青色のヒストグラムはサンプル蓄積を行ったモデル、赤色のヒストグラムは12ヶ月の固定ウィンドウを使用したモデルである。 12ヶ月のモデルは現在の市場状況に適応しようとし、ボラティリティの低い多くの期間においてより多くのリコールがあったのに対し、2020年に明示的に蓄積したモデルは2014年から2016年のボラティリティ上昇の経験を利用し、2020年の危機の間の強い動きを認識することができたことがわかります。 12345678 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
同じ実験を繰り返し、トレーニングサンプルにもう1、2ヶ月の履歴を追加し、2つのテストを比較してみてください。ニューラルネットワークが安定したままかどうか、最近の値動きがこのモデルにどのような影響を与えるか...。
これはニューラル・ネットワークではなく、グラディエント・ブースティング であり、パターンを見つけるための全く異なるアプローチである。
短いサンプルではデータが少ないと確信しているが、読者の好奇心を満たすために今サンプルをトレーニングしている:
1.木の本数を変えた1年間のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない)
2.樹木の数を変えた3年目のウィンドウ - 結果を比較してみましょう。(対照サンプルは使用しない)
3.毎月新しいデータが追加され、木の本数が異なる1年間のウィンドウ - 結果を比較してみましょう。(コントロール・サンプルは使用しない)
計算処理が完了するまで待つ必要があります - 多くのモデルが構築されています。
抽象論から数字に移ろう。小窓の効果はどの程度か?
重要なのは、あなたは市況に飛びつくことを提案しているが、私はさまざまな市況に関する知識を使うことを提案しているということだ。歴史に裏打ちされた知識が多ければ多いほど、その上に構築されたパターンの変化は遅くなる。
それから、小さなサンプルでどのようにハイパーパラメーターを定義するのか。私はどこでも同じだと考えている。その幅は、少なくとも安定した状態の幅と同じでなければなりません。私はそれを提案しているわけではない。学習は安定した状態において生産的であるという規定から考えた。つまり、安定したBP状態での学習結果は、同じ量のデータでの学習結果よりも良くなるが、BP状態は異なる安定状態のいくつかのセグメントで構成される。
その幅は、少なくともあなたが利益を上げられる安定した状態の幅と同じくらいでなければならない。私はこれを提案しているわけではない。条文から考えられるのは、学習は安定した状態で効率的に行われるということだ。つまり、安定したBP状態での学習結果は、同じ量のデータで学習するよりも良いが、BP状態は異なる安定した状態のいくつかのセグメントから構成される。
したがって、新しい市場状態を検出できて初めて最適な幅を見つけることができる。
なぜなら、データ収集は特定の市場状態に基づいており、状態間のバーの数は異なるからです。
注意してほしいのは、これはニューラルネットワークではなく、勾配ブースティング(gradient bousting)という、パターンを見つけるためのまったく異なるアプローチだということだ。
短いサンプルではデータが少ないと確信しているが、読者の好奇心を満たすために今サンプルをトレーニングしている:
1.木の本数を変えた1年間のウィンドウ - 結果を比較してみよう。(結果を比較してみよう。)
2.樹木の数を変えた3年目のウィンドウ-結果を比較してみよう。(対照サンプルは使用しない)
3.毎月新しいデータが追加され、木の本数が異なる1年間のウィンドウ - 結果を比較する。(コントロール・サンプルは使用しない)
計算プロセスが完了するまで待つ必要がある。
その通りだ。私にとって興味深い問題は、ニューラルネットワークを訓練するためにデータをサンプリングするパターンを探すために、グラディエント・ブースティングが 使えるかどうかということだ。これは、さまざまな市場パターンで訓練されたニューラルネットワークを使ってヘッジ取引をするための解決策を見つけるという問題だ...
その通りだ。私にとって興味深い疑問は、ニューラルネットワークを訓練するためにデータをサンプリングするパターンを探すために、グラディエントブースティングを使えるかどうかということだ。これは、さまざまな市場パターンで訓練されたニューラルネットワークを使ってヘッジ取引をするための解決策を見つけるという問題だ...
サンプルでニューラルネットワークの実験をすることなく、どうやってこの問題に対する答えを得るつもりですか?
例えば、"外の何か "からの終値のパーセンテージなどです。チャート上で、バイアスが行(サンプルの各行N行)にわたって変化しているのがわかります。サンプルの1/10を取ると、インジケータが横に動いたときに十分な情報が得られません(例えば、上のTFのグローバルトレンドに依存します)。
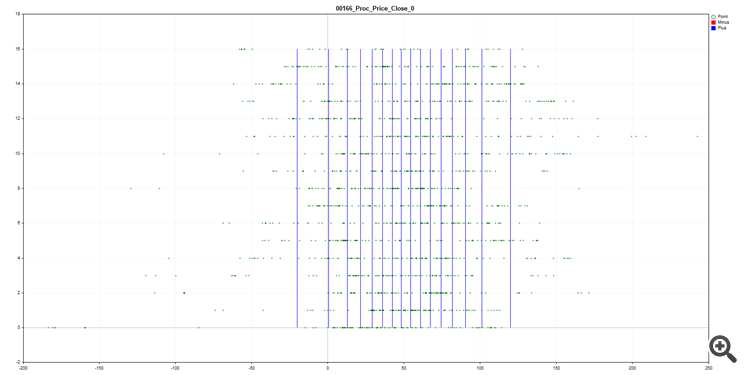
ちなみに、図は SatBoost グリッドの形でデータがどのように分割(定量化)されているかを示しています。今のところ、最初のバージョンはできている:
1.木の本数が異なる年のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない)
400本では不十分であり、1600本では過剰である。
曲線のダイナミクスは似ています。
第一稿はとりあえずできた:
1.木の本数が異なる年のウィンドウ - 結果を比較してみよう。(対照サンプルは使用しない)
400本では不十分であり、1600本では過剰である。
曲線のダイナミクスは似ています。
200本では十分な情報が得られず、1600本では情報が失われるか、重要な情報が特定できない。
200は情報が欠けており、1600は情報が失われているか、重要な情報が特定されていない。
トレーニングのための情報は安定して同じですが、条件を記憶するためのメモリサイズは異なります。私は、最初の10本の木の類似性がモデルの動作の基本的な論理を決定し、それ以上はその改良があるだけだと考えている。
2.木の本数を変えた3年目のウィンドウ-結果を比較する。(対照サンプルは使用していない)
繰り返しになるが、800回の反復が最適であることがわかる。混乱しているのは、2020年3月に強い失敗があることです。これは、モデルを超えた危機の影響なのか、それともサンプリング・エラーなのか分かりませんが、私はグルーイングで学習を行ったので、新しい先物契約への移行によるギャップがあるのかもしれません。ポジティブな面では、学習は12ヶ月の場合よりも明らかに優れている(最後のチャートでこの期間を参照!)。
3. 毎月新しいデータを追加し、ツリーの数を変えて1年間のウィンドウを表示します。(コントロール・サンプルは使用しない)
この図から、400回の反復によるモデルの成長の方が速いか、一直線であることがわかりますが、サンプル・サイズが大きくなるにつれて傾向が変わり、800回の反復によるモデルの方が誤差が少なく、月次クローズも良好で、引き離され始めました。どうやら、モデルサイズを動的に大きくする必要があるようです。
この研究から、論文で概説された方法と得られた結果は偶然の産物ではないと結論づけることができる。
たしかに、価格行動に大きな変化があり、古い行動が繰り返されるわけではなく、それに応じて、大きな期間にわたってサンプリングすると、新しいデータで儲けることができなくなることには同意します。モデル上の価格行動のばらつきを特定することは今後の研究課題ですが、私は多少古いとはいえ、できるだけ多くの価格情報を使うことを好みます。
下図はリコールに関する情報であり、青色のヒストグラムはサンプル蓄積を行ったモデル、赤色のヒストグラムは12ヶ月の固定ウィンドウを使用したモデルである。
12ヶ月のモデルは現在の市場状況に適応しようとし、ボラティリティの低い多くの期間においてより多くのリコールがあったのに対し、2020年に明示的に蓄積したモデルは2014年から2016年のボラティリティ上昇の経験を利用し、2020年の危機の間の強い動きを認識することができたことがわかります。