Cosa inserire nell'ingresso della rete neurale? Le vostre idee... - pagina 30
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Una rete normale selezionerà da sola i dati necessari e quelli non necessari.
La cosa principale è cosa insegnare!
L'apprendimento con un insegnante non è adatto a questo scopo. Le reti con propagazione dell'errore all'indietro sono semplicemente inutili.
C'è una comprensione del modo in cui il meccanismo dovrebbe essere addestrato? In pratica, esaminiamo i pesi, li adattiamo a un grafico, ma allo stesso tempo c'è un altro insieme di pesi, un insieme che non è solo adattato a questo grafico, ma "adattato" a quello successivo, e a quello successivo, e a quello successivo ancora, e così via.
E finisce per "rompersi" da qualche parte là fuori, molto più avanti. In questo caso, l'apprendimento viene presentato come la ricerca della differenza tra un insieme di set che non funzionano e quelli che funzionano.
Inoltre, la rete addestrata non ha bisogno di ulteriori "messe a punto": modifica già da sola il numero dei pesi. Quali altre idee ci sono su come appare l'apprendimento automatico e su come viene presentato?
Una rete normale selezionerà da sola i dati necessari e quelli non necessari.
La cosa principale è cosa insegnare!
L'apprendimento con un insegnante non è adatto a questo scopo. Le reti con propagazione dell'errore all'indietro sono semplicemente inutili.
La rete non selezionerà nulla: selezionerà le variabili che meglio si adattano al campione di addestramento.
Un numero elevato di variabili è un grave problema.
La rete non selezionerà nulla: selezionerà le variabili che meglio si adattano al campione di allenamento.
Unnumero elevato di variabili è il problema principale.
Per memorizzare il percorso - il migliore Per l'apprendimento (nella comprensione attuale) - il male maggiore.
formare due griglie: una solo per l'acquisto, l'altra per la vendita.
accendere entrambe :-)
Poi aggiungete una rete di risoluzione delle collisioni (o semplicemente un'algoritmo) in modo che non operino contemporaneamente in direzioni diverse.
Stavo pensando che si potrebbe scrivere il markup. Scrivere tutte le date in cui si verifica l'entrata e la chiusura. Se l'ottimizzatore imposta dei pesi che danno un segnale al di fuori di queste date, apriamo con il lotto massimo da perdere. Oppure non aprire affatto.
Si scopre che sarà un metodo con un maestro, ma da MT5 forze
La rete neurale può funzionare anche su un solo valore di una caratteristica, se si selezionano i parametri
ma abbiamo bisogno di condizioni graal (dts) con una diffusione quasi nulla. Penso che qualsiasi TS funzionerà in tali condizioni :)
Esiste un modo per descrivere la richiesta alla macchina di aprire una posizione quando lo ritiene opportuno? Come lo spiegheremmo: obblighiamo la rete neurale ad aprire posizioni da sola.... "se, allora". Specifichiamo quando aprire "se l'uscita della rete neurale è maggiore di 0,6", "se dei due neuroni di uscita, quello superiore ha il valore più alto".
"Se - allora, se - allora" e così via. E qui, in modo che non ci siano limiti di apertura, condizioni. Ci sono gli input, ci sono i pesi. All'interno della rete neurale si sta formando una sorta di poltiglia.
È possibile descrivere in qualche modo alla macchina, in base al suo lavoro con gli input e i pesi (da ricercare nell'ottimizzatore), di aprire le posizioni quando decide di farlo? Come si può prescrivere questa condizione? In modo che scelga quando aprire le posizioni.
UPD Aggiungere una seconda rete neurale.
Oppure diverse reti neurali.
O c'è un altro modo per descrivere un compito del genere?
UPD Aggiungere un blocco di esperienza.
Poi si scopre che è una specie di tabella q. E abbiamo bisogno che tutto sia all'interno della rete neurale.
... Come si imposta questa condizione? Per scegliere quando aprire....
Posso aiutarvi: date segnali di acquisto e di vendita allo stesso tempo, e il neurone deciderà dove andare. Non ringraziatemi...
Per la prima volta sono riuscito a ottenere un set nella parte superiore da un lavoratore. Inoltre, un lavoratore per ben 3 anni in avanti.
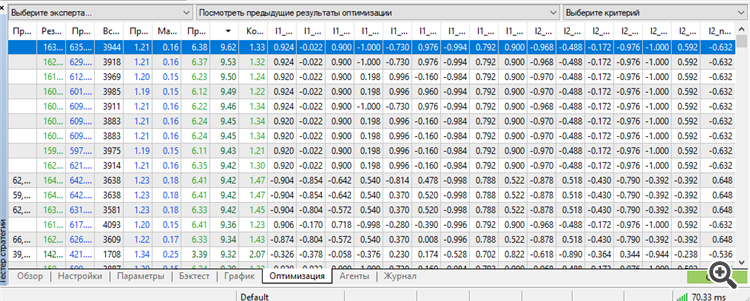
Formazione per 9 anni dal 2012 al 2021
Avanti 2021
Avanti 2022
Avanti 2023
Tutti i 3 anni di forward 2021-2023.12.13.
È vero, abbiamo dovuto utilizzare tutto il potenziale di MT5: il numero massimo di pesi-parametro ottimizzabili.
Se fosse possibile ottimizzare più parametri, sarebbe più interessante conoscere i risultati. Mi lascia perplesso la scritta "64 bit troppo lunghi" o qualcosa del genere. Se l'algoritmo genetico permette di ottimizzare ancora di più, sarebbe interessante sapere come aggirare questa limitazione.
se si potessero ottimizzare più parametri
Poiché la MT5 è limitata nel numero di parametri ottimizzabili, sono passato a NeuroPro 1999, dall'articolo qui - Reti neurali facili e gratuite - Connettere NeuroPro e MetaTrader 5.
Ho aumentato l'architettura in quantità: in MT5 era 5-5-5-5, qui è 10-10-10, e l'allenamento è già reale (per essere più precisi - standard, grazie al metodo di propagazione degli errori e ad altre caratteristiche interne al programma.


L'autore del programma ci ha sputato sopra e non ha nemmeno intenzione di aggiornare la rarità - in base alle sue risposte alle mie domande, non ha alcun interesse a sviluppare NeoroPro, a introdurre il multithreading, i metodi moderni, ecc. Sorprendentemente, il programma può produrre risultati simili a MT5. Ma è facile rompere gli schemi: aggiungendo un altro neurone/un altro strato/riducendo la dimensione dei dati di un mese, tutto andrà a caso.
In altre parole, dobbiamo trovare una media aurea tra sovrallenamento e sottoallenamento. Inoltre, dopo l'allenamento il modello non funziona ancora. Abbiamo bisogno di una post-ottimizzazione dei parametri della MT5 - soglie di apertura per BUY e SELL. Qualcosa di simile è stato fatto a suo tempo da NeuroMachine dei creatori di MeGatrader.
Senza di essa, il grafico di equilibrio si muove a malapena verso l'alto nel periodo di apprendimento e si prosciuga nel periodo di previsione. Le condizioni sono cambiate: già 6 ingressi, EURUSD H1, ai prezzi di apertura, 10 anni di apprendimento dal 2012 al 2022.
In avanti - ultimi due anni 2022-2023-12-16
Grafico complessivo - si può vedere che la stabilità è simile, il carattere è identico, non sembra una fortuna.
Proverò altre coppie e aumenterò l'architettura per escludere completamente il fattore fortuna e confermare le prestazioni del metodo. Bene e soprattutto - dopo l'ottimizzazione - l'insieme di lavoro era in cima all'ordinamento in base al parametro "fattore di recupero". Se non lo farà in un secondo momento, non ci sarà alcuna conferma. Ancora una volta sarò bloccato nel caso, nella fortuna, nella fortuna.
Il metodo del punzecchiamento creativo mi ha portato a un'idea: uno strato di neuroni in senso classico è un ammasso di malessere.
Soprattutto il primo strato, che riceve i dati in ingresso.
Lo strato più importante. L'input è costituito da dati eterogenei. O omogenei, non importa. Ogni cifra, ogni numero è una rappresentazione di forma, contenuto, dipendenza - nell'originale.
È come una fonte, come un film, come una fotografia. E immaginate, una normale rete neurale prende ogni numero, ogni attributo - e stupidamente li somma, moltiplicati per il peso, in un mucchio di spazzatura, chiamato sommatore. È come sfocare una foto e cercare di ripristinare l'immagine: non funzionerà nulla. È così. La fonte è persa, cancellata. Non c'è più. Tutto il restauro si riduce a una sola cosa: un disegno aggiuntivo. È così che funzionano le moderne reti neurali per ripristinare le vecchie foto, o per migliorarle, ingrandirle: le disegnano e basta. È solo un lavoro creativo della rete neurale, non ha una fonte, attinge a ciò che aveva nel suo database di immagini una volta, qualcosa di simile, anche se del 99%, ma non la fonte.
E così, alimentiamo i prezzi, gli incrementi di prezzo, i prezzi trasformati, i dati degli indicatori, i numeri in cui è codificata una qualche figura, un qualche stato del grafico - e la rete neurale prende e cancella stupidamente l'unicità di ogni numero, gettando tutti i numeri in un unico pozzo e facendo una conclusione (output) sulla base di questa enorme spazzatura, in cui è impossibile capire cosa sia cosa. Un tale numero di adder d'ora in poi sarà identico a figure diverse, con numeri diversi. Cioè, abbiamo due figure - sono visualizzate in una diversa sequenza di numeri. I contenuti di queste figure sono diversi, ma il volume può essere lo stesso. Il volume è numerico. E poi nell'addizionatore questo heap-mala può significare sia una cifra che un'altra. Non sapremo mai quale esattamente - a questo punto abbiamo cancellato l'informazione unica.
L'abbiamo spalmata, buttata in una pentola, ora è una zuppa. E se l'input è spazzatura? Allora con il 1000% di probabilità il primo sommatore trasformerà quella spazzatura in spazzatura al quadrato. E con il 1000% di probabilità una rete neurale di questo tipo non individuerà mai nulla da questa spazzatura, non la troverà mai, non la estrarrà mai. Perché in questo caso non si limita a scavare nella spazzatura, ma la frantuma in un tritacarne chiamato "strati successivi".
Il mio approccio da profano mi dice che dobbiamo cambiare il modo in cui affrontiamo le architetture e il modo in cui trattiamo gli input. Come prova, i miei grafici qui sopra. Un ingresso, due ingressi, tre ingressi - un neurone, due neuroni, tre neuroni.
Ecco, la cosa successiva è la riqualificazione - memorizzare il percorso piuttosto che lavorare su nuovi dati. La seconda conferma è la riqualificazione stessa. Più neuroni, più strati, peggio è per i nuovi dati. In altre parole, con ogni nuovo strato, con ogni nuovo neurone, trasformiamo i dati originali in spazzatura al quadrato e alla rete neurale non resta che memorizzare il percorso.
Cosa che riesce perfettamente a fare durante il retraining. Un piccolo volo di fantasia.