Discussione sull’articolo "La stima kernel di densità della funzione di densità di probabilità"
All'autore. Risultati ancora migliori si ottengono se si stima non la densità della distribuzione, ma la funzione di distribuzione, cioè l'integrale della densità: in primo luogo, è più facile costruirla sui dati, e poiché è sempre non decrescente e limitata tra 0 e 1, la sensibilità alla scelta dell'algoritmo di smoothing, sia esso kernel, spline, regressione o altro, è molto più bassa. Anche i requisiti sulla quantità di dati disponibili sono ridotti, e di un ordine di grandezza.
Inoltre, la densità può essere facilmente ottenuta mediante differenziazione numerica, se necessario.
Se necessario, la densità può essere facilmente ottenuta mediante differenziazione numerica.
Forse. Non posso dire nulla al riguardo. Non ho nemmeno provato a valutare la pdf tramite la cdf . Molto probabilmente ha funzionato il pregiudizio che l'uso della differenziazione richiedesse un aumento significativo dell'accuratezza della stima della cdf. Inoltre, non mi sono imbattuto in alcuna pubblicazione che valutasse il metodo cdf->pdf o che lo confrontasse con altri metodi. Se potete condividere i link, ve ne sarei grato.
L'idea originaria era quella di non utilizzare alcuno strumento esterno, cioè si presumeva che tutto dovesse essere implementato solo da strumenti MQL5.
Questa è l'idea di tutti gli inventori di biciclette, senza eccezioni.
Guardate cosa hanno i pacchetti corrispondenti a questo proposito e confrontateli con quello che avete fornito: una quantità infinitesimale di ciò che è necessario quando si applicano la matematica e l'econometria nel trading.
Forse. Non posso dire nulla al riguardo. Non ho nemmeno provato a stimare il pdf tramite la cdf . Molto probabilmente, il pregiudizio che l'uso della differenziazione richieda un aumento significativo dell'accuratezza della stima di cdf ha funzionato. Inoltre, non mi sono imbattuto in alcuna pubblicazione che valutasse il metodo cdf->pdf o che lo confrontasse con altri metodi. Se condividete dei link, ve ne sarei grato.
Non posso fornire riferimenti perché non li ho. Riporto invece queste considerazioni.
Quando si valuta direttamente un pdf, bisogna dividere in anticipo il dominio della definizione in intervalli, e ci sono due problemi: primo, non sappiamo in quanti intervalli è meglio dividere il dominio, e secondo, non sappiamo che tipo di griglia(uniforme, ... ?) sarebbe meglio. E se per il secondo quesito si è ancora cercato in qualche modo di risolverlo, ad esempio utilizzando il partizionamento quantilico, per il primo, a mio avviso, non esistono metodi universali: tutti quelli a me noti hanno limitazioni che li rendono poco utili nei compiti di automazione, quando non ci si può permettere il metodo del poke.
La stima della cdf è priva di questi svantaggi. In questo caso, i gradini della funzione si trovano esattamente dove cadono i dati di input, e quindi il problema della scelta della griglia per l'interpolante scompare da solo. Una volta creata la griglia, non è difficile scegliere il numero di intervalli: conosciamo già il numero massimo di intervalli (e la loro posizione!!!), quindi, assottigliando, possiamo impostare qualsiasi precisione richiesta, e ogni volta su una griglia naturale che meglio si adatta alla struttura dei dati di input.
In pratica, ho utilizzato questa tecnica per cercare le modalità locali delle distribuzioni empiriche quando il numero di campioni di dati non supera i 100, e ho ottenuto risultati molto omogenei, e visivamente l'accuratezza della ricerca è definita come abbastanza qualitativa, almeno 2-4 modalità principali vengono trovate praticamente senza deviazioni. Ma utilizzo un algoritmo di smoothing diverso, non mi piacciono i kernel per diversi motivi.
Tutto perfettamente corretto. Ma come sembra a me, tranne che per un punto, al quale apparentemente non hai prestato attenzione.
Un'espressione ben nota per Kernel smoother è "Kernel smooth".
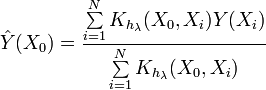
Un metodo basato su tale lisciatura per stimare la pdf potrebbe essere simile a questo (semplificato):
- Si suddivide la sequenza di input in intervalli (clustering, binning).
- Smussiamo l'istogramma risultante.
Se non si ama lo smoothing kernel, si può usare, ad esempio, la p-spline. (Probabilmente è meglio scegliere subito la p-spline).
Con questo approccio alla stima della pdf tutto ciò che avete detto risulta assolutamente corretto. Ma anche in questo caso questo metodo di stima per sequenze di grande lunghezza (>1000000) dà risultati eccellenti. Man mano che la lunghezza della sequenza in ingresso diminuisce, tutti i vantaggi di cui avete parlato iniziano a manifestarsi in modo sempre più marcato.
Vediamo ora l'espressione della stima della densità del kernel (KDE)
![]()
Questa espressione è diversa da quella fornita in precedenza. Come possiamo vedere, questa espressione determina direttamente il valore della funzione di densità di probabilità in un determinato punto. E ciò che è importante in questo caso è che non c'è partizione in intervalli. Vengono utilizzati direttamente i valori della sequenza di input.
Almeno, questo è il modo in cui vedo la situazione con KDE. L'algoritmo di stima del pdf fornito nell'articolo a prima vista si adatta bene a sequenze di 20-30 elementi. A volte si potrebbe voler ridurre il grado di lisciatura. Lo si può fare facilmente sostituendo nel codice
h=0.9*a/MathPow(N,0.2); // Regola empirica di Silvermancon
h=0.7*a/MathPow(N,0.2); // Regola empirica di Silverman
L'idea originaria era quella di non utilizzare alcuno strumento esterno, cioè si presumeva che tutto dovesse essere implementato solo da strumenti MQL5.
Questa è l'idea di tutti gli inventori di biciclette, senza eccezioni.
Guardate cosa hanno i pacchetti corrispondenti a questo proposito e confrontateli con quello che avete fornito - una quantità infinitesimale di ciò che è necessario quando si applica la matstatistica e l'econometria nel trading.
Caro Alex,
È facile per te ragionare dall'alto del tuo volo. Ma rifletti un attimo su quanto segue:
Questa risorsa si chiama"www.mql5.com - Automated Trading and Testing of Trading Strategies". Come puoi vedere, il sito si chiama mql5, non EViews e nemmeno MQ o MT5. Pertanto, è facile supporre che questo sito sia principalmente incentrato sulla divulgazione, il debug e lo sviluppo del linguaggio di programmazione MQL5. Ciò è confermato dalla presenza del servicedk e dalla collocazione di informazioni di riferimento sul MQL5 nel sito.
Se questo sito si chiamasse, ad esempio, "una raccolta di strategie di trading" e non appartenesse a MQ. In questo caso, ci si aspetterebbe che le pubblicazioni che descrivono soluzioni in Exel, R, EVievs, Gauss, Stata e così via appaiano su tale sito.
Se avessi pubblicato questo articolo sul sito di EViews, avrei potuto cercare di capire l'essenza del suo rimprovero. Ma io e lei non siamo su EViews in questo momento.
Questo sito è visitato da persone con background molto diversi. Si tratta di persone di età diverse, con diversi percorsi formativi e diverse specializzazioni. Credo che la maggior parte di loro abbia poca o nessuna esperienza con i pacchetti econometrici. Pensate che tutte queste persone dovrebbero essere bandite da questo sito, ad esempio lasciando che imparino prima EViews?
Dal momento che si è autopubblicato, dovrebbe conoscere la procedura di pubblicazione degli articoli su questo sito. È impossibile autopubblicare un articolo. È possibile solo inviare un articolo per essere preso in considerazione. L'amministrazione del sito stesso seleziona gli articoli adatti al suo concetto generale. In alcuni casi, l'amministrazione stessa ordina articoli su argomenti di suo interesse. Come ho già detto, l'amministrazione ha un concetto generale e statistiche sul numero di richieste per questa o quella pubblicazione. In questa situazione, credo che non sia corretto rivolgersi a me con affermazioni sull'argomento dell'articolo. Forse dovreste discutere di questi problemi con i rappresentanti di MQ?
Ci sono articoli pubblicati su questo sito che non mi interessano. Sottolineo, non si tratta di articoli brutti, ma semplicemente non interessanti per me. Di solito non li leggo e non scrivo commenti su di essi. Forse dovreste scegliere una linea di comportamento simile per voi stessi? Anche se non mi permetto di dare consigli, fate come vi sentite più a vostro agio.
Caro Alex,
È facile per te ragionare dall'alto del tuo volo. Ma rifletti un attimo su quanto segue:
Questa risorsa si chiama"www.mql5.com - Automated Trading and Testing of Trading Strategies". Come puoi vedere, il sito si chiama mql5, non EViews e nemmeno MQ o MT5. Pertanto, è facile supporre che questo sito sia principalmente incentrato sulla divulgazione, il debug e lo sviluppo del linguaggio di programmazione MQL5. Ciò è confermato dalla presenza del servicedk e dalla collocazione di informazioni di riferimento sul MQL5 nel sito.
Se questo sito si chiamasse, ad esempio, "una raccolta di strategie di trading" e non appartenesse a MQ. In questo caso, ci si aspetterebbe che le pubblicazioni che descrivono soluzioni in Exel, R, EVievs, Gauss, Stata e così via appaiano su tale sito.
Se avessi pubblicato questo articolo sul sito di EViews, avrei potuto cercare di capire l'essenza del suo rimprovero. Ma io e lei non siamo su EViews in questo momento.
Questo sito è visitato da persone con background molto diversi. Si tratta di persone di età diverse, con diversi percorsi formativi e diverse specializzazioni. Credo che la maggior parte di loro abbia poca o nessuna esperienza con i pacchetti econometrici. Pensate che tutte queste persone dovrebbero essere bandite da questo sito, ad esempio lasciando che imparino prima EViews?
Dal momento che si è autopubblicato, dovrebbe conoscere la procedura di pubblicazione degli articoli su questo sito. È impossibile autopubblicare un articolo. È possibile solo inviare un articolo per essere preso in considerazione. L'amministrazione del sito stesso seleziona gli articoli adatti al suo concetto generale. In alcuni casi, l'amministrazione stessa ordina articoli su argomenti di suo interesse. Come ho già detto, l'amministrazione ha un concetto generale e statistiche sul numero di richieste per questa o quella pubblicazione. In questa situazione, credo che non sia corretto rivolgersi a me con affermazioni sull'argomento dell'articolo. Forse dovreste discutere di questi problemi con i rappresentanti di MQ?
Ci sono articoli pubblicati su questo sito che non mi interessano. Sottolineo, non si tratta di articoli brutti, ma semplicemente non interessanti per me. Di solito non li leggo e non scrivo commenti su di essi. Forse dovreste scegliere una linea di comportamento simile per voi stessi? Anche se non mi permetto di dare consigli, fate come vi sentite più a vostro agio.
Non posso accettare la sua risposta, perché non è affatto in linea con l'essenza del mio post. Cercherò di spiegare il mio punto di vista.
1. Metaquotes non ha nulla a che fare con tutto questo - hanno fornito uno strumento molto decente e lo stanno facendo.
2. Non sono a conoscenza di alcuna restrizione sugli argomenti degli articoli. Naturalmente, nei limiti del trading. Questo sito ha una sezione "Statistiche", vale a dire che l'argomento del sito è molto più ampio di voi, in piena sintonia con i contenuti e le problematiche del trading. Non facciamo riferimento a Metaquotes e passiamo alla sostanza.
3. il mio post non riguarda COSA sviluppare, ma COME sviluppare. Per me questo è l'aspetto fondamentale in relazione al vostro articolo. Non stavo facendo una campagna a favore di EViews, di cui ho una scarsa opinione - è buono per scopi dimostrativi e di formazione, ma non credo che si possa fare trading su di esso. Il mio link è ai pacchetti per dimostrare l'ampiezza del problema.
4. Mi occupo di programmazione da molto tempo. 40 anni fa sono apparse le prime librerie di programmi e subito, 40 anni fa, hanno criticato i dilettanti che riscrivevano qualche programma da un pacchetto esistente. Lei non è il primo. Ma questo sito è pieno di dilettanti che amano costruire di nuovo una bicicletta - da qui la mia reazione ipertrofica.
5. La questione della valutazione nucleare è una questione masticata e masticata. E se prendeste la biblioteca di qualcun altro, avreste l'opportunità di elevarvi al di sopra delle difficoltà tecniche che avete risolto nel vostro articolo e magari di offrire una soluzione ai problemi sollevati dal praticante alsu, o di ricordare che la valutazione visiva delle distribuzioni gioca un ruolo molto importante nella loro valutazione formale, o di espandersi dal punto di vista funzionale, ecc. - in entrambi i casi sareste un gradino più in alto.
Non volevo esprimere nulla di offensivo nei suoi confronti. Il suo articolo e il suo sviluppo sono rispettati, ma non posso essere d'accordo con il focus metodologico della tecnica di implementazione delle sue idee.
Il mio post sul suo articolo è dettato dalla speranza che qualcuno integri sistematicamente il terminale Metaquot con mezzi statistici ed econometrici. Vi rimando a queste persone.
Estremamente interessante. Molto interessante.
Accettate richieste?
Non solo codice open source, ma anche codice orientato alla statistica è auspicabile. Si prega di prestare attenzione a R.
Estremamente interessante. Molto interessante.
Accettate richieste?
Non solo codice open source, ma anche codice orientato alla statistica è auspicabile. Si prega di prestare attenzione a R.
Le richieste sono accettate qui: https://www.mql5.com/ru/forum/6505. Scrivete quello che volete. :)
- www.mql5.com
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Il nuovo articolo La stima kernel di densità della funzione di densità di probabilità è stato pubblicato:
L'articolo tratta la creazione di un programma che consenta di stimare la densità kernel della funzione di densità di probabilità incognita. Il metodo di stima kernel di densità è stato scelto per eseguire l'attività. L'articolo contiene i codici sorgente dell'implementazione del software del metodo, esempi del suo utilizzo e illustrazioni.
La Fig.1 mostra i grafici di stima della densità per la sequenza avente la legge di distribuzione normale e vari valori dell'intervallo h.
Le stime vengono eseguite utilizzando la classe CDens descritta sopra. I grafici sono stati costruiti sotto forma di pagine HTML. Il metodo per costruire tali grafici sarà presentato alla fine dell'articolo. La creazione di grafici e diagrammi in formato HTML si trova in [9].
Fig.1. Stima della densità per vari valori dell'intervallo h
La Fig.1 mostra anche la vera curva di densità della distribuzione normale (distribuzione gaussiana) insieme a tre stime della densità. Si può facilmente vedere che il risultato più appropriato della stima è stato ottenuto con h=0.22 in quel caso. In altri due casi si osservano "oversmoothing" e "undersmoothing" definiti.
La figura 1 mostra chiaramente l'importanza della corretta selezione dell'intervallo h durante l'uso della stima kernel di densità. Nel caso in cui il valore di h sia stato scelto in modo errato, una stima sarà notevolmente spostata rispetto alla densità reale o notevolmente dispersa.
Autore: Victor