L'Apprentissage Automatique dans le trading : théorie, modèles, pratique et trading algo - page 1258
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
beaucoup de formules ((
Eh bien ) il y a un lien vers le paquet R. Je n'utilise pas R moi-même, je comprends les formules.
si vous utilisez R, essayez-le )
Eh bien ) il y a un lien vers le paquet R. Je n'utilise pas R moi-même, je comprends les formules.
Si vous utilisez R, essayez-le)
L'article de ce matin est toujours ouvert : https://towardsdatascience.com/bayesian-additive-regression-trees-paper-summary-9da19708fa71.
Le fait le plus décevant est que je n'ai pas pu trouver une implémentation Python de cet algorithme. Les auteurs ont créé un package R(BayesTrees) qui présentait quelques problèmes évidents - principalement l'absence de fonction "predict" - et une autre implémentation, plus largement utilisée, appelée bartMachine, a été créée.
Si vous avez l'expérience de la mise en œuvre de cette technique ou connaissez une bibliothèque Python, veuillez laisser un lien dans les commentaires !
Donc le premier paquet est inutile car il ne peut pas prédire.
Le deuxième lien présente à nouveau des formules.
Voici un arbre ordinaire facile à comprendre. Tout est simple et logique. Et sans formules.
Peut-être que je ne suis pas encore arrivé aux libéraux. Les arbres ne sont qu'un cas particulier d'un vaste sujet bayésien. Vous trouverez de nombreux exemples de livres et de vidéos ici.
J'ai utilisé l'optimisation bayésienne des hyperparamètres de NS selon les articles de Vladimir. Cela fonctionne bien.Comme quoi les arbres... il y a des réseaux neuronaux bayésiens
De façon inattendue !
Les NS travaillent avec les opérations mathématiques + et * et peuvent construire n'importe quel indicateur à l'intérieur de lui-même, de la MA aux filtres numériques.
Mais les arbres sont divisés en parties droite et gauche par de simples if(x<v){branche gauche}suite{branche droite}.
Ou est-ce aussi if(x<v){branche gauche}seulement{branche droite} ?
Mais s'il y a beaucoup de variables à optimiser, c'est oooo long.
De façon inattendue !
Les NS travaillent avec les opérations mathématiques + et * et peuvent construire n'importe quel indicateur à l'intérieur - de la MA aux filtres numériques.
Les arbres sont divisés en parties droite et gauche par de simples if(x<v){branche gauche}suite{branche droite}.
Ou est-ce que baisian NS est aussi if(x<v){branche gauche}seulement{branche droite} ?
c'est lent, c'est pourquoi j'en retire quelques connaissances utiles jusqu'à présent, ça permet de comprendre certaines choses
Non, dans la NS bayésienne, les pondérations sont simplement optimisées en échantillonnant les pondérations à partir des distributions, et la sortie est également une distribution qui contient un tas de choix, mais qui a une moyenne, une variance, etc. En d'autres termes, il capture en quelque sorte un grand nombre de variantes qui ne se trouvent pas réellement dans l'ensemble de données d'apprentissage, mais qui sont, a priori, supposées. Plus le nombre d'échantillons introduits dans ce type de SN est important, plus il converge vers un modèle régulier, c'est-à-dire que les approches bayésiennes sont initialement destinées à des ensembles de données pas très grands. Voilà ce que je sais pour l'instant.
C'est-à-dire que ces NS n'ont pas besoin de très grands ensembles de données, les résultats convergeront vers les résultats conventionnels. Mais après l'entraînement, la sortie ne sera pas une estimation ponctuelle, mais une distribution de probabilité pour chaque échantillon.
c'est, oui, lent, donc tirer de là des connaissances utiles jusqu'à présent, donne une compréhension de certaines choses
Non, dans la NS bayésienne, les pondérations sont simplement optimisées en échantillonnant les pondérations à partir des distributions, et la sortie est également une distribution qui contient un tas de choix, mais qui a une moyenne, une variance, etc. En d'autres termes, il capture en quelque sorte un grand nombre de variantes qui ne se trouvent pas réellement dans l'ensemble de données d'apprentissage, mais qui sont, a priori, supposées. Plus on introduit d'échantillons dans ce type de SN, plus il converge vers un modèle régulier, c'est-à-dire que les approches bayésiennes sont initialement destinées à des ensembles de données pas très grands. Voilà ce que je sais pour l'instant.
C'est-à-dire que ces NS n'ont pas besoin de très grands ensembles de données, les résultats convergeront vers les résultats conventionnels. Mais le résultat après la formation ne sera pas une estimation ponctuelle, mais une distribution de probabilité pour chaque échantillon.
Tu cours partout comme si tu étais en vitesse, une chose à la fois, une autre chose à la fois... et ça ne sert à rien.
Vous semblez avoir beaucoup de temps libre, comme certains messieurs, vous devez travailler, travailler dur, et vous efforcer de faire évoluer votre carrière, au lieu de vous précipiter des réseaux neuronaux aux bases.
Croyez-moi, personne dans les maisons de courtage normales ne vous donnera de l'argent pour du verbiage ou des articles scientifiques, seulement des capitaux propres confirmés par les courtiers de premier ordre du monde.Je ne me précipite pas, mais j'étudie systématiquement du simple au complexe.
Si vous n'avez pas d'emploi, je peux vous proposer, par exemple, de réécrire quelque chose en mql.
Je travaille pour le propriétaire comme tout le monde, c'est étrange que tu ne travailles pas, tu es toi-même un propriétaire, un héritier, un golden boy, un homme normal s'il perd son travail en 3 mois dans la rue, il est mort en 6 mois.
S'il n'y a rien du tout sur le MO dans le commerce, alors allez vous promener, on croirait que les pauvres sont les seuls mendiants ici).
Je les ai tous montrés en IR, honnêtement, pas de secrets d'enfants, comme tous les canards boiteux ici, l'erreur dans le test est de 10-15%, mais le marché change constamment, le commerce ne va pas, le bavardage près de zéro
En bref, va-t'en, Vassia, les jérémiades ne m'intéressent pas.
Tout ce que vous faites c'est pleurnicher, pas de résultats, vous creusez des fourches dans l'eau et c'est tout, mais vous n'avez pas le courage d'admettre que vous perdez votre temps
Vous devriez rejoindre l'armée ou au moins travailler sur un chantier avec des hommes physiquement, vous amélioreriez votre caractère.c'est lent, c'est pourquoi j'en retire quelques connaissances utiles jusqu'à présent, ça permet de comprendre certaines choses
Non, dans la NS bayésienne, les pondérations sont simplement optimisées en échantillonnant les pondérations à partir des distributions, et la sortie est également une distribution qui contient un tas de choix, mais qui a une moyenne, une variance, etc. En d'autres termes, il capture en quelque sorte un grand nombre de variantes qui ne se trouvent pas réellement dans l'ensemble de données d'apprentissage, mais qui sont, a priori, supposées. Plus le nombre d'échantillons introduits dans ce type de SN est important, plus il converge vers un modèle régulier, c'est-à-dire que les approches bayésiennes sont initialement destinées à des ensembles de données pas très grands. Voilà ce que je sais pour l'instant.
C'est-à-dire que ce type de NS n'a pas besoin de très grands ensembles de données, les résultats convergeront vers les résultats conventionnels.
Voici un extrait de https://www.mql5.com/ru/forum/226219 commentaires sur l'article de Vladimir sur l'optimisation bayésienne, comment il trace la courbe sur plusieurs points. Mais ils n'ont pas non plus besoin de NS/forêts - vous pouvez simplement chercher la réponse sur cette courbe.
Autre problème : si un optimiseur n'apprend pas, il enseignera à NS des bêtises incompréhensibles.
 échantillon enseigné
échantillon enseigné 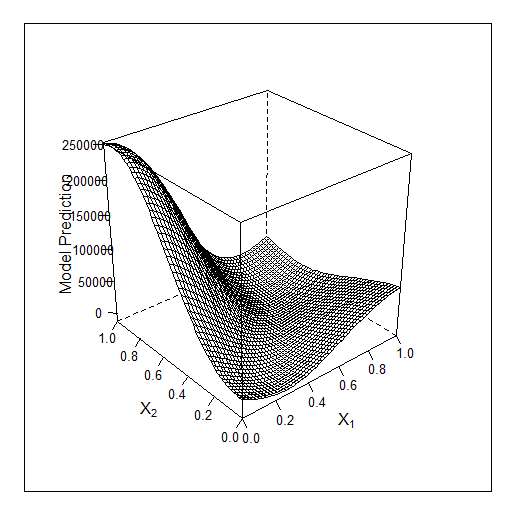
Ici pour 3 caractéristiques le travail de Bayes
Ce sont les abrutis dans le fil de discussion qui le rendent pas drôle du tout.
qui se plaignent à eux-mêmes.
Qu'est-ce qu'il y a à dire ? Vous ne faites que collecter des liens et différents résumés scientifiques pour impressionner les nouveaux venus, SanSanych a tout écrit dans son article, il n'y a pas grand chose à ajouter, maintenant il y a différents vendeurs et rédacteurs d'articles qui ont tout étalé avec leurs fourches de honte et de dégoût. Ils se disent "mathématiciens", ils se disent "quantiques" ......
Les mathématiques veulent essayer de lire cettehttp://www.kurims.kyoto-u.ac.jp/~motizuki/Inter-universal%20Teichmuller%20Theory%20I.pdf
Et vous ne comprendrez pas que vous n'êtes pas un mathématicien mais un flocon.