¿Qué alimentar a la entrada de la red neuronal? Tus ideas... - página 32
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
El grial que veo no es la suma, sino la división de números
UPD
Y la tarea de las neuronas no es obtener un conjunto de números, sino obtener un número como entrada. Multiplicarlo por un peso y alimentarlo a través de una función no lineal.
Es decir, hay un número (valor de entrada, o salida de la neurona), y este número es dividido por dos o más neuronas de la siguiente capa.
Deben ser independientes de las otras neuronas. Es un departamento que hace sus propias cosas. Luego, todos estos departamentos deben informar a un jefe: la neurona de salida. Elabora una inferencia basada en las salidas de todas las neuronas finales. Con sus propios pesos.
Así reducimos la distorsión de la información y aumentamos su lectura.
Ahora bien, esta idea parece incompleta. Por un lado, la idea de no distorsionar los datos de entrada parece sensata. Después de todo, al distorsionar con sumadores y pesos, es como si estuviéramos manipulando otros datos, sustituyéndolos por algo aleatorio en lugar de lo que muestra el gráfico.
Y esto tiene que expresarse de alguna manera. Por otro lado, la división de números es buena para algún conjunto de números combinados en un solo número.
Y esos números en su interior deben ser estáticos, de modo que puedan ser "extraídos" del número total, en lugar de inventar el suyo propio. La división ordinaria en la versión que imaginé es lo mismo que la multiplicación ordinaria de un número por otro. Es decir, la cantidad de división no cambia el resultado. Si el número de entrada es 7, no importa cómo se divida, todas las operaciones de división serán iguales a una sola multiplicación en la neurona de salida. Como resultado, el aumento de la ramificación no tiene sentido, ya que no hay movimiento desde los datos de entrada.
Así que debería haber al menos 2 entradas para relacionarlas entre sí. Así que voy a girar y girar la nueva arquitectura.
Abandoné laarquitectura y decidí jugar con una neur ona. 1neurona.
Como en el artículoRedes neuronales - de la teoría a la prácticaActivación tangente. Las entradas no son 3, como antes, sino 6. Y aquí llegué a una situación, por primera vez, en la que aumentar las entradas sólo mejoraba los resultados, no el sobreentrenamiento. Es decir, la imagen que vemos cuando decimos "más es mejor".
Pero se trata sólo de inputs, no hay arquitectura como tal, sólo una neurona. Optimización a lo largo de 9 años: 2012 a 2021.
EURUSD.¿Por qué exactamente este? A partir de 2021 empieza la tendencia de largo plazo contraria a 2020 y todos los sistemas que optimizan o entrenan sobre 2020 pierden inmediata y violentamente en 2021. Pero también están los 8 años anteriores para "ganar" experiencia.
Parece que el conjunto es un poco pésimo. El principio es pésimo, casi hasta la mitad. Pero si se mira desde el otro lado: sí, al principio no funciona, y luego empieza a funcionar. La pregunta que surge es: ¿cuánto durará este comercio y mejorará?
Y, si lo hace, ¿podrá repetir su éxito en otros pares de divisas? A 3 años vista: de 2021 a 2024.
En otros pares: GBPUSD
NZDUSD
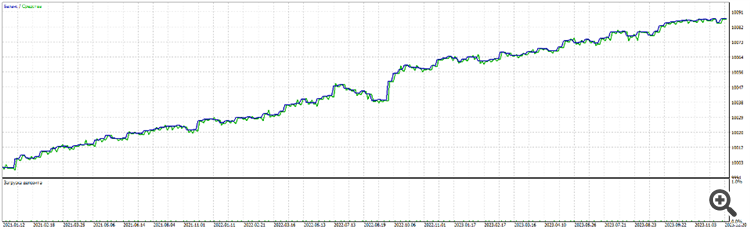
AUDUSD
Lo curioso de éste es que es de 1 neurona. De nuevo rinde mejor que 2 , 3, 10 neuronas.
Que 2, 3, 5 capas. El problema, como siempre, es el mismo de siempre - el conjunto estaba en algún lugar de las líneas 50. Un segundo problema se ha añadido a la misma - las cotizaciones de metaquotes.
MQL tiene cotizaciones leales a los traders, o no tienen comisión o spread, o ambos, pero tales resultados son mucho más difíciles de repetir en el mismo ISMarket, estúpidamente convierte todos los conjuntos en no rentables y aquellos con operaciones más largas se mantienen a flote. Supongamos que un conjunto está en la parte superior de la lista del optimizador. Supongamos que todos los corredores tienen las mismas cotizaciones como metacotizaciones. El resultado muestra que, sea cual sea la arquitectura, lo principal es"¿Qué alimentar a la entrada de la red neuronal?".
El número debe compararse con una matriz ordenada de los mismos números. Por ejemplo, se toman las últimas 30 ondas, se alinean por magnitud de movimiento y se compara el tamaño de la última onda con esta matriz. ¿En qué decil se encuentra? ¿Qué ocurre? Ahora hay una escala universal para cualquier gráfico.
Sí, tengo un indicador sobre esta base. Pronto voy a tratar de ponerlo en neuronka también.
Sí, tengo un pavo sobre esta base. Pronto intentaré ponerlo también en neuronka.
Se pueden conseguir gráficos tan bonitos sin neuronka.
En primer lugar, todo esto debe hacerse en ticks reales (si no es así), y en segundo lugar, mira el crecimiento. Durante 3 años no pude ganar ni el 10%.
Y también debe mirar el tamaño de la reducción máxima.
...y segundo, mira las ganancias. En 3 años no pude ganar ni el 10%.
Y también tienes que mirar el drawdown máximo.
No importa. Estás muy lejos.
Estamos en la fase de "poner en marcha esta máquina". Y luego miramos ganancias y drawdowns.
Lo principal es que suba, no importa cuánto, mientras sea estable. Y luego lo nivelaremos.
En primer lugar, todo esto debe hacerse en ticks reales (si no es así).
No sé cómo hacerlo en ticks reales.
Para ser más preciso, no estoy técnicamente preparado. Ni idea, ni tesis, ni idea del algoritmo, y por lo tanto, de hecho, ni código para retorcerlo y girarlo en mis manos.
No importa. Has recorrido un largo camino.
Estamos en la fase de "poner en marcha esta máquina". Y luego ya veremos las subidas y bajadas.
Lo principal es que suba, no importa cuánto, mientras sea estable. Y luego lo nivelaremos.
No se usar ticks reales.
Para ser más preciso, no estoy técnicamente preparado. No tengo ni idea, ni tesis, ni idea del algoritmo, y por lo tanto, de hecho, ningún código para retorcerlo y girarlo en mis manos.
Si quieres probar en esto o estudiar redes neuronales, entonces sí, es otra cosa.
Pero yo añadiría que MO o NS o AI sólo se pueden utilizar en forex para optimizar una estrategia de trading.
Y si la estrategia es mala, no pueden mejorar tu estrategia. Tienes que hacerlo tu mismo.
Pero todo está ya disponible en MT5 tester. ¿Por qué no utiliza MT5 optimizador?
Si quieres probarlo o estudiar redes neuronales, entonces sí, es diferente.
Pero yo añadiría que MO o NS o AI sólo pueden utilizarse en forex para optimizar una estrategia de trading.
Y si la estrategia es mala, no pueden mejorar tu estrategia. Tienes que hacerlo tú mismo.
Pero todo está ya disponible en MT5 tester. ¿Por qué no utiliza MT5 optimizador?
Al contrario, escribí antes que utilizo tanto MT5 como NeuroPro. En este momento estoy exclusivamente en MT5 y el optimizador está sobreponderado. Sólo juego con entradas y arquitecturas.
Al contrario, ya he escrito antes que utilizo tanto MT5 como NeuroPro. En este momento me siento exclusivamente en MT5 y el optimizador está sobreponderando. Sólo juego con entradas y arquitecturas.
Si estás haciendo todo esto en modo "Every Tick", no te aconsejo que continúes.
Sabes muy bien que en este modo los valores tick se modelan (generan) según ciertas leyes.
Y cualquier Asesor Experto de clase media, a través de la optimización, será capaz de encontrar tales combinaciones de parámetros de entrada que usted puede obtener resultados poco realistas.
Y no tiene sentido perder el tiempo en ello.
Usted no dijo lo que es la reducción máxima por medio ?