Índice Hearst - página 22
Está perdiendo oportunidades comerciales:
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Registro
Entrada
Usted acepta la política del sitio web y las condiciones de uso
Si no tiene cuenta de usuario, regístrese
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
Me confunde su "Ni una sola viable" después de las palabras "... y en la literatura". Hay muchos enfoques diferentes en la literatura que dan resultados ligeramente diferentes entre sí, lo que no es sorprendente ya que todos son estimaciones. Sin embargo, también es cierto que cuanto mayor sea la muestra, más precisas deberían ser estas estimaciones y más "iguales" entre sí. Sólo estoy de acuerdo en que es difícil encontrar un algoritmo Hurst que funcione en los foros.
En cuanto a lo que hay que introducir en la entrada del algoritmo, al algoritmo le da igual. Alimenta el precio y obtendrás algo alrededor de uno. De hecho, para la esencia del algoritmo el precio tiene una fuerte memoria a largo plazo, porque se mantiene relativamente lejos de los valores originales. Los incrementos del precio de los piensos - se obtiene algo así como 0,5, que de nuevo está justificado, porque sus cambios relativos son grandes y casi aleatorios. Alimentar las tendencias y/o los ciclos: conseguir la persistencia. El ruido suele reducir el índice. Veo que la pregunta "¿es nuestro precio ruidoso o un precio justo de mercado?" no es objeto del algoritmo de Hearst, eso es otro ámbito.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
En general, cuanto más tiempo, mejor. Según el algoritmo del libro de Peters, es mejor la longitud que tiene el mayor número de divisores enteros.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Se distinguen dos modelos:
1. El proceso tiene un índice de Hurst "estable". Es decir, el índice es una constante y no cambia en el tiempo (durante toda la existencia del proceso). En este caso, su definición se toma como un mínimo -un segmento estadísticamente significativo-, es decir, un segmento que permite hacer una estimación segura de la distribución del proceso. O sin molestar - un segmento tan grande como sea posible.
2. El indicador es alguna función, posiblemente muy compleja, posiblemente aleatoria. En este caso, no hay criterios objetivos para seleccionar la longitud del PA. Estimar el índice para el caso general es imposible tanto en el dominio del tiempo como en el de la frecuencia, a no ser que seas un vidente.
Es importante destacar que el análisis de RS es uno de los métodos más burdos, su estimación siempre está sesgada y el tamaño de la muestra no ayudará en nada. Para obtener un cálculo correcto del índice de Hurst, utilice la estimación basada en wavelets (el algoritmo puede encontrarse en mathlab, por ejemplo).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Hearst para el precio es ~1, pero aquí ¿qué?
Lo único que puedo ayudar en este caso es señalar que no hay ningún análisis Hurst o R/S en el archivo _hurst_classik. El sentido de la propia denominación "R/S" es el de reescalar la fila. Pero el texto de _hurst_classik que tiene una pretensión de _RS_Analiz no contiene ningún remapeo, sino que, por ejemplo, toma trivialmente la diferencia entre los precios máximos y mínimos.
Además, el análisis R/S, para llegar a Hearst, calcula la pendiente de la curva y para ello necesita muchos puntos en el plano log(R/S) - log(n) en lugar de uno. En este milagro _RS_Analiz no hay tal cosa.
El punto principal de mi post era "identificar el modelo de BP", pero eso no te llamó la atención.
Si hablamos de modelos de clase ARFIMA o algo así, realmente no me interesa, porque estos modelos están creciendo "nakuya", cuyo propósito es recaudar dinero para los fondos de inversión. Esta "ciencia" se llama ciencia de gabinete porque se crea sólo para ajustar la base científica a un resultado deseado conocido, normalmente una predicción de precios.
Si hablamos de modelos de clase ARFIMA o algo así, realmente no me interesa, porque estos modelos son cada vez más "naqui", cuyo objetivo es recaudar dinero para los fondos de inversión. Esta "ciencia" se llama ciencia de gabinete porque se crea sólo para encajar un marco científico en un resultado deliberadamente deseado, normalmente una predicción de precios.
No hagamos estimaciones. Ahora estamos hablando de enfoques que utilizan el modelo BP y no lo utilizan en absoluto.¡¡¡AYUDA PARA CALCULAR EL INDICADOR HEARST!!!
*Pequeño comentario: como Peters
He leído todo el hilo de principio a fin: sí, no me esperaba que todo el mundo, desde respetados académicos hasta simples curiosos, tuvieran su propia opinión sobre lo que es Hirst, y cómo debe contarse e interpretarse. Lo más cercano al original fue Eric Nyman en su artículo y libro. Pero... nosotros (en Rusia, por así decirlo) todavía no tenemos una herramienta adecuada para generar gráficos, que se presentan en el libro de Peters.
Así pues, he intentado imitar al máximo la secuencia de pasos que Peters describió en su primer libro: "Caos y orden en el mundo del capital", para calcular las estadísticas R/S del S&P 500.
1. Tomamos los gráficos mensuales del S&P 500 desde el 01.01.1950 hasta el 01.07.1988.
2. Los cargamos en el programa de análisis técnico (yo uso WealthLab y C#, aquí y más adelante usaré el código WL/C#)
3. Convierta los precios en rendimientos utilizando la fórmula del libro de Peters: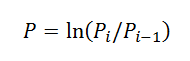
4. El propio Peters no menciona que, una vez calculados los rendimientos, se convierten de nuevo en una serie acumulada: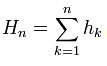 . Sin embargo, esto es obvio, en base a esos valores de propagación R/S que tiene, además la fuente también lo dice explícitamente, cito: "Para cada n natural compongamos los valores (véase la fórmula anterior) y calculemos las siguientes características numéricas de la subsecuencia resultante".
. Sin embargo, esto es obvio, en base a esos valores de propagación R/S que tiene, además la fuente también lo dice explícitamente, cito: "Para cada n natural compongamos los valores (véase la fórmula anterior) y calculemos las siguientes características numéricas de la subsecuencia resultante".
5. Dividimos la serie resultante en k períodos, siendo la longitud de cada período N de 6 a 231 meses u observaciones.
6. Aquí hay un punto importante. Si no se obtiene el número entero de períodos (quedan datos sin utilizar), se descartan. Sin embargo, si el resto es demasiado grande (por ejemplo, 462 / 232 = 233 y 230 en el resto) se obtiene un valor incorrecto. Tengo entendido que Peters utiliza desplazamientos, sin embargo, esta es una opción muy engorrosa en términos de programación y simplemente descarto el período si su residuo es mayor que 6. Dado que los períodos adyacentes tienen casi el mismo valor R/S, esta es la opción correcta.
7. R se calcula entonces mediante la fórmula:
8. R se divide por la desviación estándar (calculada por el indicador WL) y logarítmica: log10(R/S).
9. El periodo actual está logaritmado: log10(N);
10. La relación obtenida entre log10(R/S) y log10(N) se escribe en el archivo.
Si el optimizador pasa por N desde 6 (como Peters) hasta 231 (el número mínimo de experimentos es 2), entonces obtenemos una tabla de dos columnas en escala logarítmica doble: 1. período 2. valor de R/S.
Ahora comienza la parte más interesante. Si se traza esta tabla en Excel, saldrá lo siguiente:
El original se presenta a la derecha. Como puede ver, hay cierta similitud, pero no es lo mismo. En particular, la cifra inicial resulta estar ligeramente sobrestimada (0,33 frente a alrededor de 0,31) y, en segundo lugar, los valores finales empiezan a caer drásticamente de repente, lo que en principio no debería ser así. Según su gráfico, sólo el ángulo de la pendiente debería cambiar al final de la serie, lo que nos indica que el efecto de memoria es limitado.
Hasta ahora me he detenido en este punto. Todavía no he decidido aplicar las estadísticas U/V, dado que sólo hay un solapamiento parcial con el original.
La conversión de las puntuaciones R/S a Hearst también da resultados algo inflados. Si la figura de Hearst lo es: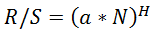 Entonces, utilizando la fórmula de Excel, obtenemos LOG(HERST(10;B1);C1*0,5), donde B1 es la puntuación R/S actual.
Entonces, utilizando la fórmula de Excel, obtenemos LOG(HERST(10;B1);C1*0,5), donde B1 es la puntuación R/S actual.
A continuación se muestra el código WL/C# que calcula las estadísticas R/S:
p.d. Es curioso, MQL4 no tiene palabras clave como overide y using, pero la sintaxis sigue resaltándolas:)¿Existe un cálculo del índice de Hurst en Matcad (necesito fórmulas en forma discreta)?
Hasta ahora sólo he encontrado esto
Se adjunta archivo con los enfoques del análisis de series temporales. De ahí saqué estas fórmulas.
Lo siento, por supuesto.
¿Es interesante? Mirando estas fórmulas no veo el sentido de aplicarlas al Forex.
Es más fácil elaborar una serie que describa el forex. Ya existe, la gente ha ganado premios Nobel por ello. Pero el resultado está muy promediado. Es necesario siempre estimar primero la media - el error, y luego tratar de eliminar los menos de la probabilidad en relación con los errores, y luego molestar a ella.
Lo siento, por supuesto.
Entonces, ¿es interesante? Mirando las fórmulas, no veo el sentido de aplicarlas al forex en absoluto.
Es más fácil lanzar una serie tú mismo que describa el forex. Ya existe, la gente se llevó un premio Nobel por ello. Pero el resultado es muy, muy promediado. Primero hay que estimar siempre la media - el error, y luego tratar de eliminar los puntos negativos de la probabilidad en relación con los errores, y luego molestarse con ella.
Lo siento. Pero para el futuro, acordemos no publicar reflexiones ociosas en este hilo. Algunos se interesan por la "fila de divisas", otros por las estadísticas de Hearst. Que cada uno tenga su propio hilo.
Estoy publicando una tabla de tipo CSV en escala logarítmica doble: estimación R/S al período.