Discusión sobre el artículo "Redes neuronales: así de sencillo (Parte 13): Normalización por lotes (Batch Normalization)"
En otro proyecto hice una comparación del cálculo rápido de errores y el clásico en un bucle para 20-50 líneas: (supongo que también tiene los mismos errores acumulados a 50 mil líneas, a millones de líneas aún más)
Primero comparé a ojo en 50 filas de datos. No hay errores en ellos.
Pero los errores se consideran como suma acumulativa. En cada cálculo podemos tener 1e-14 ... 1e-17 errores. Sumando estos errores muchas veces, - el error total puede superar 1e-5.
Hice una comparación más profunda. Tomé 50.000 filas y luego comparé los errores, si la diferencia es grande, los puse en la pantalla. Lo que obtuve (ver abajo).
Hay errores individuales acumulados por encima de 1e-4 (es decir, diferencias en el cuarto decimal).
Así que la velocidad es ciertamente bueno, pero si las cadenas no será de 50 mil, pero 500 millones? Me temo que los resultados serán absolutamente incomparables con el cálculo exacto en el bucle.
fast_error= 9.583545e+02 true_error= 9.582576e+02
fast_error= 9.204969e+02 true_error= 9.204000e+02
fast_error= 8.814563e+02 true_error= 8.813594e+02
fast_error= 8.411763e+02 true_error= 8.410794e+02
fast_error= 7.995969e+02 true_error= 7.995000e+02
fast_error= 7.566543e+02 true_error= 7.565574e+02
fast_error= 7.246969e+02 true_error= 7.246000e+02
fast_error= 6.916562e+02 true_error= 6.915593e+02
fast_error= 6.574762e+02 true_error= 6.573793e+02
fast_error= 6.220969e+02 true_error= 6.220000e+02
fast_error= 5.854540e+02 true_error= 5.853571e+02
fast_error= 5.588969e+02 true_error= 5.588000e+02
fast_error= 5.313562e+02 true_error= 5.312593e+02
fast_error= 5.027762e+02 true_error= 5.026792e+02026792e+02
fast_error= 4.730969e+02 true_error= 4.730000e+02
fast_error= 4.422538e+02 true_error= 4.421569e+02
fast_error= 4.205969e+02 true_error= 4.205000e+02
fast_error= 3.980561e+02 true_error= 3.979592e+02
fast_error= 3.745761e+02 true_error= 3.744792e+02
fast_error= 3.500969e+02 true_error= 3.500000e+02
fast_error= 3.245534e+02 true_error= 3.244565e+02
fast_error= 3.072969e+02 true_error= 3.072000e+02
fast_error= 2.892560e+02 true_error= 2.891591e+02
fast_error= 2.703760e+02 true_error= 2.702791e+02
fast_error= 2.505969e+02 true_error= 2.505000e+02
fast_error= 2.298530e+02 true_error= 2.297561e+02
fast_error= 2.164969e+02 true_error= 2.164000e+02
fast_error= 2.024559e+02 true_error= 2.023590e+02023590e+02
fast_error= 1.876759e+02 true_error= 1.875789e+02
fast_error= 1.720969e+02 true_error= 1.720000e+02
fast_error= 1.556525e+02 true_error= 1.555556e+02
fast_error= 1.456969e+02 true_error= 1.456000e+02
fast_error= 1.351557e+02 true_error= 1.350588e+02
fast_error= 1.239757e+02 true_error= 1.238788e+02
fast_error= 1.120969e+02 true_error= 1.120000e+02
fast_error= 9.945174e+01 true_error= 9.935484e+01
fast_error= 9.239691e+01 true_error= 9.230000e+01
fast_error= 8.485553e+01 true_error= 8.475862e+01
fast_error= 7.677548e+01 true_error= 7.667857e+01
fast_error= 6.809691e+01 true_error= 6.800000e+01
fast_error= 5.875075e+01 true_error= 5.865385e+01
fast_error= 5.409691e+01 true_error= 5.400000e+01400000e+01
fast_error= 4.905524e+01 true_error= 4.895833e+01
fast_error= 4.357517e+01 true_error= 4.347826e+01
fast_error= 3.759691e+01 true_error= 3.750000e+01
fast_error= 3.104929e+01 true_error= 3.095238e+01
fast_error= 2.829691e+01 true_error= 2.820000e+01
fast_error= 2.525480e+01 true_error= 2.515789e+01
fast_error= 2.187468e+01 true_error= 2.17777878e+01
fast_error= 1.809691e+01 true_error= 1.800000e+01
fast_error= 1.384691e+01 true_error= 1.375000e+01
fast_error= 1.249691e+01 true_error= 1.240000e+01
fast_error= 1.095405e+01 true_error= 1.085714e+01
fast_error= 9.173829e+00 true_error= 9.076923e+00
fast_error= 7.096906e+00 true_error= 7.000000e+00
fast_error= 4.642360e+00 true_error= 4.545455e+00
fast_error= 4.196906e+00 true_error= 4.100000e+00
fast_error= 3.652461e+00 true_error= 3.555556e+00
fast_error= 2.971906e+00 true_error= 2.875000e+00
fast_error= 2.096906e+00 true_error= 2.0000000000e+00
fast_error= 9.302390e-01 true_error= 8.33333333e-01
fast_error= 8.96909057e-01 true_error= 8.000000e-01
fast_error= 8.469057e-01 true_error= 7.500000e-01
fast_error= 7.635724e-01 true_error= 6.66666667e-01
fast_error= 5.969057e-01 true_error= 5.000000e-01
fast_error= 4.546077e+00 true_error= 4.545455e+00
fast_error= 4.100623e+00 true_error= 4.100000e+00
fast_error= 3.556178e+00 true_error= 3.555556e+00
fast_error= 2.875623e+00 true_error= 2.875000e+00
fast_error= 2.000623e+00 true_error= 2.000000e+00
fast_error= 8.339561e-01 true_error= 8.333333e-01
fast_error= 8.006228e-01 true_error= 8.000000e-01
fast_error= 7.506228e-01 true_error= 7.500000e-01
fast_error= 6.672894e-01 true_error= 6.66666667e-01
fast_error= 5.006228e-01 true_error= 5.000000e-01
¿Cuál es el problema?
Durante el entrenamiento el terminal se cuelga y da un error no siempre, es como una especie de poltergeist.
N 0 22:58:20.933 Core 1 2021.02.01 00:00:00 la cadena de programa es NULL o está vacía
MP 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
CD 0 22:58:20.933 Núcleo 1 2021.02.01 00:00:00 OnInit - 153 -> Error de lectura EURUSD_PERIOD_H1_ 20AttentionMLMH_d.nnw prev Net 5015
RD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 cadena de programa es NULL o vacío
QN 0 22:58:20.933 Core 1 2021.02.01 00:00:00 programa OpenCL crear falló. Error code=4003
IO 0 22:58:20.933 Core 1 final balance 10000.00 USD
LE 2 22:58:20.933 Core 1 2021.02.19 23:54:59 invalid pointer access in 'NeuroNet.mqh' (2271,16)
MS 2 22:58:20.933 Core 1 OnDeinit error crítico
NG 0 22:58:20.933 Core 1 EURUSD,H1: 863757 ticks, 360 barras generadas. Entorno sincronizado a las 0:00:00.018. Prueba superada en 0:00:00.256.
QD 0 22:58:20.933 Núcleo 1 EURUSD,H1: tiempo total desde inicio de sesión hasta fin de prueba 0:00:00.274 (incluyendo 0:00:00.018 para sincronización de datos históricos)
LQ 0 22:58:20.933 Núcleo 1 321 Mb de memoria utilizada, incluyendo 0.47 Mb de datos históricos, 64 Mb de datos de tick
JF 0 22:58:20.933 Núcleo 1 archivo de registro "C:\Users\Buruy\AppData\Roaming\MetaQuotes\Tester36A64B8C79A6163D85E6173B54096685\Agent-127.0.0.0.1-3000.0.0.0.1-3000\logs\20210410.log" escrito
PP 0 22:58:20.939 Core 1 conexión cerrada
¡¡¡Gracias de antemano por vuestra ayuda!!!
Dmitry hola! durante un par de meses observo una fuerte discrepancia entre la ejecución de OOS y el trabajo final en el mismo intervalo, pero ya un Asesor Experto. Todas las señales son unidad (descargo en un archivo para cada barra todas las señales y comparo) La red naturalmente tiene todos los mismos ajustes. Hay una sospecha de que el proceso de guardar y leer la formación no funciona correctamente. En el archivo NeuroNet.mph para cada red está configurada una forma individual de guardar la formación
bool CNeuronProof::Guardar(const int file_handle)
bool CNeuronBase::Guardar(int file_handle)
bool CNeuronConv::Guardar(const int asa_archivo)
bool CNeuronLSTM::Guardar(const int directorio_archivo)
bool CNeuronBaseOCL::Guardar(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
etc.
y se utiliza guardar
bool CNet::Guardar(cadena nombre_archivo,doble error,doble indefinido,doble previsión,datetime hora,bool común=true)
¿Puedes explicar la diferencia, y es posible comparar los datos guardados con el entrenamiento de la memoria después de una época?
Datos de señal de salida TempData y neuronas de salida ResultData en el momento del entrenamiento
y por separado en el momento de la prueba. He comparado ambos archivos en el programa WinMerge.
{kind=link}
Dmitry hola! durante un par de meses observo una fuerte discrepancia entre la ejecución de OOS y el trabajo final en el mismo intervalo, pero ya un Asesor Experto. Todas las señales son unidad (descargo en un archivo para cada barra todas las señales y comparo) La red naturalmente tiene todos los mismos ajustes. Hay una sospecha de que el proceso de guardar y leer la formación no funciona correctamente. En el archivo NeuroNet.mph para cada red está configurada una forma individual de guardar la formación
bool CNeuronProof::Guardar(const int file_handle)
bool CNeuronBase::Guardar(int file_handle)
bool CNeuronConv::Guardar(const int asa_archivo)
bool CNeuronLSTM::Guardar(const int directorio_archivo)
bool CNeuronBaseOCL::Guardar(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
etc.
y se utiliza guardar
bool CNet::Guardar(cadena nombre_archivo,doble error,doble indefinido,doble previsión,datetime hora,bool común=true)
¿Puedes explicar la diferencia, y es posible comparar los datos guardados con el entrenamiento de la memoria después de una época?
Datos de señal de salida TempData y neuronas de salida ResultData en el momento del entrenamiento
y por separado en el momento de la prueba. He comparado ambos archivos en el programa WinMerge.
Buenos días, Dmitry.
Veamos el método CNet::Save(...). Después de registrar las variables que caracterizan el estado de entrenamiento de la red, se llama al método Save del array de capas neuronales (CArrayLayer heredado de CArrayObj)
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return true; if(file_name==NULL) return false; //--- int handle=FileOpen(file_name,(common ? FILE_COMMON : 0)|FILE_BIN|FILE_WRITE); if(handle==INVALID_HANDLE) return false; //--- if(FileWriteDouble(handle,error)<=0 || FileWriteDouble(handle,undefine)<=0 || FileWriteDouble(handle,forecast)<=0 || FileWriteLong(handle,(long)time)<=0) { FileClose(handle); return false; } bool result=layers.Save(handle); FileFlush(handle); FileClose(handle); //--- return result; }
La clase CArrayLayer no tiene método Save, por lo que se llama al método de la clase padre CArrayObj::Save(const int file_handle). El cuerpo de este método contiene un bucle para enumerar todos los objetos anidados y llamar al método Save para cada objeto.
//+------------------------------------------------------------------+ //| Escribir array a fichero| //+------------------------------------------------------------------+ bool CArrayObj::Save(const int file_handle) { int i=0; //--- comprobar if(!CArray::Save(file_handle)) return(false); //--- escribe la longitud del array if(FileWriteInteger(file_handle,m_data_total,INT_VALUE)!=INT_VALUE) return(false); //--- escribir array for(i=0;i<m_data_total;i++) if(m_data[i].Save(file_handle)!=true) break; //--- resultado return(i==m_data_total); }
En otras palabras, aquí se utiliza el principio del muñeco anidado: llamamos al método Save para el objeto de nivel superior, y dentro del método se buscan todos los objetos anidados y se llama al método del mismo nombre para cada objeto.
La carga de datos desde un archivo se organiza de forma similar.
En cuanto a las diferentes evaluaciones durante el entrenamiento y el funcionamiento. No sé cómo está organizada tu red neuronal en el modo de funcionamiento, pero en el modo de entrenamiento los parámetros de la red neuronal cambian constantemente. En consecuencia, los mismos datos de entrada producirán resultados diferentes.
Saludos,
Dmitry.
P.D. Puedes comprobar la corrección de guardar y leer datos haciendo un pequeño programa de prueba, en el que puedas leer la red neuronal desde un archivo e inmediatamente guardarla en un nuevo archivo. Y luego compara los dos ficheros. Si notas alguna discrepancia, escríbeme y lo comprobaré.
Buenas tardes, Dmitry.
Veamos el método CNet::Save(...). Después de registrar las variables que caracterizan el estado de entrenamiento de la red, se llama al método Save del array de capas neuronales (CArrayLayer heredado de CArrayObj)
La clase CArrayLayer no tiene método Save, por lo que se llama al método de la clase padre CArrayObj::Save(const int file_handle). El cuerpo de este método contiene un bucle para enumerar todos los objetos anidados y llamar al método Save para cada objeto.
En otras palabras, aquí se utiliza el principio del muñeco anidado: llamamos al método Save para el objeto de nivel superior, y dentro del método se buscan todos los objetos anidados y se llama al método del mismo nombre para cada objeto.
La carga de datos desde un archivo se organiza de forma similar.
En cuanto a las diferentes evaluaciones durante el entrenamiento y el funcionamiento. No sé cómo está organizada tu red neuronal en el modo de funcionamiento, pero en el modo de entrenamiento los parámetros de la red neuronal cambian constantemente. En consecuencia, los mismos datos de entrada producirán resultados diferentes.
Saludos,
Dmitry.
P.D. Puedes comprobar la corrección de guardar y leer datos haciendo un pequeño programa de prueba, en el que puedas leer la red neuronal desde un archivo e inmediatamente guardarla en un nuevo archivo. Y luego compara los dos ficheros. Si notas alguna discrepancia, escríbeme y lo comprobaré.
Aceptado, intentaré comprobarlo de la siguiente manera. En la primera barra guardaré TempData (Señales) y OUTPUT Neuronas en el fichero. Primero sin cargar el archivo pero con entrenamiento, luego con carga de entrenamiento de la misma primera barra pero sin entrenamiento en el proceso. solo una barra en ambos casos y comparo. Escribiré de nuevo.
p/s/ ya que en el proceso de entrenamiento realmente aprende neuronka en cada barra, en el proceso del tester implemento el mismo proceso, pero con menos N barras.El impacto no deberia ser significativo. Pero estoy de acuerdo en que debería ser.
¡Estimado Dmitry!
En el proceso de largo trabajo con la ayuda de su biblioteca me las arreglé para crear un asesor de comercio con un buen resultado de 11% de reducción a casi el 100% de ganancia por 5 años EURUSD.
Alpari:
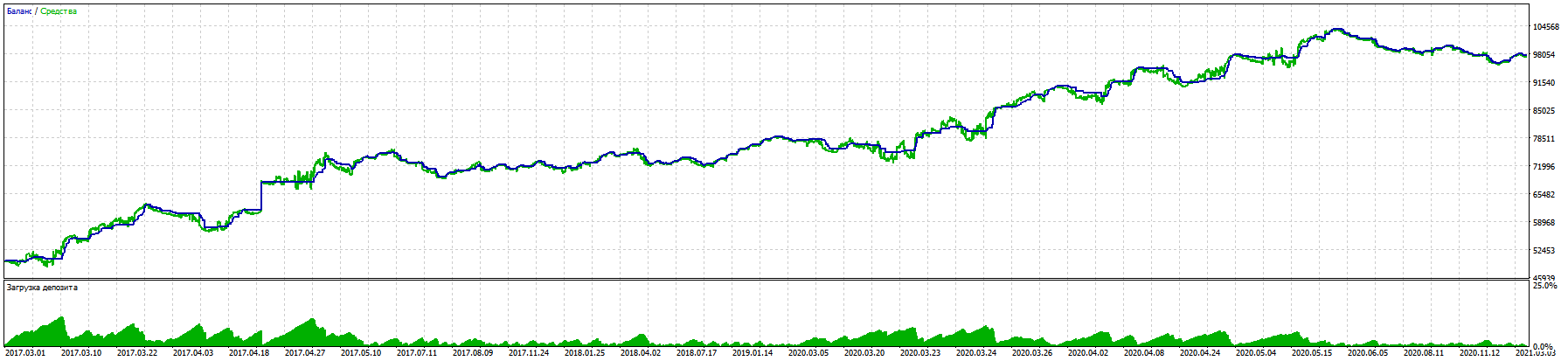
La prueba en una cuenta real sigue la misma lógica.
Es de destacar que incluso en los futuros BKS RURUSD da resultados aún mejores con las mismas entradas. (No he probado en otros pares todavía).
La victoria clave fue probar el comercio a ciegas (la formación sólo en los últimos períodos) y Stoploss obligatoria sin martingalas y otros trucos, excepto el derecho a abrir varias operaciones en cualquier dirección en función de la señal.
Por supuesto, tuve que estudiar y complementar mucho de los cursos de cinco semanas en las Universidades de WSE y Stanford, y un montón de artículos sobre redes neuronales, especialmente en la comprensión de qué enseñar, qué enseñar y cómo enseñar.
¡Muchas gracias!
Por favor, no se detengan y sigan desarrollando la biblioteca.
Lo que me gustaría pedirles es que piensen en
1. Todavía en la preservación de la formación. Es como ya he escrito no funciona. Usted tiene que aprender cada vez y "de golpe" sin apagar el comercio. Esto no es un problema, la formación es rápida, pero hay un segundo problema.
2. Al principio, has configurado la lógica Randomise para crear neuronas primarias. Esto da lugar a hasta tres versiones de entrenamiento. (Creo que el punto clave es que la neurona primaria es inicialmente positiva o negativa).
Sí, esto también se puede tratar, por así decirlo, forzando el reentrenamiento, desde cero, si no llegas a la métrica correcta.
Pero estoy seguro de que se puede empezar con un peso condicional de 0,01 en cada neurona. (Desafortunadamente el sobreentrenamiento se vuelve más pronunciado).
O todavía aprender a mantener la mejor copia de la educación, entonces es el punto 1.
¡Querido Dimitri!
En el proceso de trabajo a largo con la ayuda de su biblioteca me las arreglé para crear un asesor de comercio con un buen resultado de 11% drawdown a casi 100% de ganancia durante 5 años EURUSD.
Alpari:
La prueba en una cuenta real sigue la misma lógica.
Es de destacar que incluso en los futuros BKS RURUSD da aún mejores resultados con las mismas entradas. (No he probado en otros pares todavía).
La victoria clave fue probar el comercio a ciegas (la formación sólo en períodos anteriores) y Stoploss obligatoria sin martingalas y otros trucos, excepto por el derecho a abrir varias operaciones en cualquier dirección en función de la señal.
Por supuesto, tuve que estudiar y complementar un montón de cosas de los cursos de cinco semanas en las universidades de WSE y Stanford, y un montón de artículos sobre redes neuronales, especialmente en la comprensión de qué enseñar, qué enseñar y cómo enseñar.
Muchas gracias.
Por favor, no se detengan y continúen con el desarrollo de la biblioteca.
Lo que me gustaría pedirles que pensaran
1. Todavía en la preservación de la formación. Como ya he escrito, no funciona. Usted tiene que aprender cada vez y "de golpe" sin desconectar el comercio. Esto no es un problema, la formación es rápida, pero hay un segundo problema.
2. Al principio, se ha configurado la lógica Randomise para crear neuronas primarias. Esto da lugar a hasta tres versiones de entrenamiento. (Creo que el punto clave es que la neurona primaria es inicialmente positiva o negativa).
Sí, también puedes luchar contra esto, por así decirlo, forzar el reentrenamiento, desde cero, si no has alcanzado las métricas requeridas.
Pero seguro que puedes empezar con un peso condicional de 0,01 en cada neurona. (Desafortunadamente el sobreentrenamiento se hace más pronunciado)
O todavía aprender a mantener la mejor copia de la educación, entonces es el punto 1.
Gracias Dimitri por sus amables palabras. Iniciar todos los pesos con un valor constante es una mala práctica. En tal caso, durante el aprendizaje todas las neuronas trabajan sincrónicamente como una sola. Y toda la red neuronal degenera en una neurona en cada capa.
....
Lo que me gustaría pedirle que pensara
1. Seguir manteniendo la formación. Como ya he escrito, no funciona. Tienes que aprender cada vez y "de golpe" sin desconectar del trading. Esto no es un problema, la formación es rápida, pero hay un segundo problema.
2. Al principio, se ha configurado la lógica Randomise para crear neuronas primarias. Esto da lugar a hasta tres versiones de entrenamiento. (Creo que el punto clave es que la neurona primaria es inicialmente positiva o negativa).
Sí, se puede luchar contra esto también, por así decirlo, obligar a volver a entrenar, desde cero, si no se han alcanzado las métricas requeridas.
Pero seguro que puedes empezar con un peso condicional de 0,01 en cada neurona. (Por desgracia, el sobreentrenamiento se hace más pronunciada)
O todavía aprender a mantener la mejor copia de la educación, entonces es el punto 1.
Dimitri, he probado esto como el autor le aconsejó.
1. Entrenar varias épocas, después de cada época se guarda el archivo de red.
2. Borrar de la gráfica. Ejecutar de nuevo con el parámetro testSaveLoad activado - después de leer la red previamente entrenada, el Asesor Experto la escribe de nuevo, repite el ciclo lectura-escritura de nuevo y descarga, y obtenemos tres archivos, además de la red original con los prefijos _check y _check2.
3. Comparamos los tres archivos. Vamos a) a aprender programación mediante pruebas b) a buscar errores en nosotros mismos.

Gracias Alexei, no publiqué los resultados aquí.
El problema resultó ser otro.
El proceso de guardar/cargar funciona.
La solución la encontré en la línea de crear elementos de red neuronal usando Randomize.
bool CArrayCon::CreateElement(int index) { if(index<0 || index>=m_data_max) return false; //--- xor128; double weigh=(double)rnd_w/UINT_MAX-0.5; m_data[index]=new CConnection(weigh); if(!CheckPointer(m_data[index])!=POINTER_INVALID) return false; //--- return (true); }
La sustituí por una función de creación de neuronas más estable, y es importante crear un número igual de neuronas positivas y negativas, para que la red no se predisponga hacia las ventas o las compras.
double weigh=(double)MathMod(index,0)?sin(index):sin(-index);
Hice lo mismo con la función de crear pesos iniciales por si acaso.
double CNeuronBaseOCL::GenerateWeight(void) { xor128; double result=(double)rnd_w/UINT_MAX-0.5; //--- return result; } //+----
Ahora el backtest da el mismo resultado al probar la red entrenada después de cargar el fichero de entrenamiento.
Las entradas son unidad por segundo.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Redes neuronales: así de sencillo (Parte 13): Normalización por lotes (Batch Normalization):
En el artículo anterior, comenzamos a analizar varios métodos para mejorar la calidad del aprendizaje de la red neuronal. En este artículo, proponemos al lector continuar con este tema y analizar la normalización por lotes de los datos, un enfoque muy interesante.
En la práctica de uso de redes neuronales, se usan varios enfoques para la normalización de los datos, pero todos están orientados a mantener los datos de la muestra de entrenamiento y los datos de salida de las capas ocultas de la red neuronal en un intervalo dado y con ciertas características estadísticas de la muestra, como la varianza y la mediana. Esto es importante, porque las neuronas de la red usan transformaciones lineales que durante el entrenamiento desplazan la muestra hacia el antigradiente.
Vamos a analizar un perceptrón completamente conectado con 2 capas ocultas. Con la propagación hacia delante, cada capa genera algún conjunto de datos que sirve como una muestra de entrenamiento para la capa siguiente. El resultado de la capa de salida se compara con los datos de referencia y el gradiente de error de la capa de salida se distribuye en la propagación inversa a través de las capas ocultas hacia los datos iniciales. Tras recibir el gradiente de error en cada neurona, actualizaremos los coeficientes de peso, ajustando nuestra red neuronal para generar las muestras de la última propagación hacia delante. Aquí hay un conflicto: ajustamos la segunda capa oculta (H2 en la figura a continuación) para seleccionar los datos en la salida de la primera capa oculta (H1 en la figura), al tiempo que, modificando los parámetros de la primera capa oculta, cambiamos la matriz de datos. es decir, ajustamos la segunda capa oculta en función de la muestra de datos ya inexistente. Una situación similar sucede con la capa de salida, que ajustamos según la salida ya modificada de la segunda capa oculta. Y si además tenemos en cuenta la distorsión entre la primera y la segunda capas ocultas, las escalas de los errores aumentarán. Y cuanto más profunda sea la red neural, más intensamente se manifestará este efecto. Este fenómeno se llamaba desplazamiento interno de covarianza.
En las redes neuronales clásicas, el problema indicado se resolvía parcialmente disminuyendo el coeficiente de aprendizaje. Los pequeños cambios en los coeficientes de peso no modifican intensamente la distribución de la muestra en la salida de la capa neuronal. Pero este enfoque no resuelve el escalado del problema derivado del aumento en el número de capas de la red neuronal y reduce la velocidad de aprendizaje. Otro problema relacionado con un coeficiente de entrenamiento pequeño sería el atasco en el mínimo local; ya hemos hablado de ello en el artículo [6].
Autor: Dmitriy Gizlyk