"New Neural" is an Open Source neural network engine project for the MetaTrader 5 platform. - page 56
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Yes, that's exactly what I wanted to know.
to mql5
SZY the main concern now is whether the data will need to be copied into special processor arrays or will it be supported to pass an array as a parameter in a normal function. This question may fundamentally change the entire project.
ZZZY can you answer in your plans to just give OpenCL API or are you planning to wrap it in your own wrappers?
Judging by:
mql5:
In fact, you will be able to use OpenCL.dll library functions directly without having to plug in any third party DLLs.
OpenCL.dll functions will be available as if they were native MQL5 functions, while the compiler will redirect the calls itself.
From this it can be concluded that the OpenCL.dll functions can be laid down already now (pacifier calls).
Renat and mql5, did I understand the "environment" correctly?
Judging by:
OpenCL.dll functions can be used as if they were native MQL5 functions, while the compiler itself will redirect the calls.
From this it can be concluded that OpenCL.dll functions can be laid down already now (pacifier calls).
Renat and mql5, did I understand the "situation" correctly?
So far, I have the following scheme of the project:
Objects are rectangles, methods are ellipses.processing methods are divided into 4 categories:
These four methods describe the entire processing across all layers, the methods are imported into the processing through method objects, which are inherited from the base class and overloaded as needed depending on the type of neuron.
Nikolai, you know the popular phrase -- premature optimization is the root of all evil.
Forget about OpenCL for now. You will have to do something decent without it. You will always have time to transpose it, especially if it is not yet available.
Nicholas, you know such a catch phrase - premature optimization is the root of all evils.
Forget about OpenCL for now; you could do something decent without it. You can always switch it around. Besides, there's no way to do it out of the box yet.
Yes, it is a popular phrase and I almost agreed with it last time, but after analyzing it I realized that I could not just plan it and then redo it for GPU, it has very specific needs.
if we plan to do without GPU, it would be logical to make a Neuron object, which would be responsible for both operations inside neuron and assigning calculation data into required memory cells, by inheriting class from common ancestor we could easily connect the required neuron type and so on,
But a little brainstorming, immediately realized that this approach completely destroy GPU calculations, the unborn child is already doomed to crawl.
But I suspect that my post above has got you confused. By "parallel computing method" there I mean a quite specific operation of multiplying inputs with weights in*wg, by successive calculations method I mean sum+=a[i] and so on.
Just for better subsequent compatibility with GPU, I propose to derive operations from neurons and combine them in one move in the object layer, and neurons will only supply information from where to take where to put.
Lecture 1 here https://www.mql5.com/ru/forum/4956/page23
Lecture 2 here https://www.mql5.com/ru/forum/4956/page34
Lecture 3 here https://www.mql5.com/ru/forum/4956/page36
Lecture 4 here https://www.mql5.com/ru/forum/4956/page46
Lecture 5 (last). Sparse Coding
This topic is the most interesting. I will write this lecture gradually. So, don't forget to check this post from time to time.
In general our task is to present price quote (vector x) on last N bars as a linear decomposition into basis functions (series of matrix A):
where s are the coefficients of our linear transformation that we want to find and use as inputs to the next layer of the neural network (e.g. SVM). In most cases we know the basis functions A , i.e. we choose them in advance. They can be sines and cosines of different frequencies (we get the Fourier transform), Gabor functions, Hammotons, wavelets, curlets, polynomials or any other functions. If we know these functions beforehand, sparse coding reduces to finding a vector of coefficients s such that a large number of these coefficients are equal to zero (sparse vector). The idea here is that most information signals have a structure that is described by a smaller number of basis functions than the number of signal samples. These basis functions included in the sparse description of signal are its necessary features which can be used for signal classification.
The problem of finding the discharged linear transformation of the original information is called Compressed Sensing (http://ru.wikipedia.org/wiki/Compressive_sensing). In general, the problem is formulated this way:
minimize L0 norm of s, subject to As = x
where L0 norm equals to the number of non-zero values of vector s. The most common method for solving this problem is replacement of L0 norm by L1 norm which is the basis of the basis pursuit method(https://en.wikipedia.org/wiki/Basis_pursuit):
minimize L1 norm of s, subject to As = x
where L1 norm is calculated as |s_1|+|s_2|+...+|s_L|. This problem reduces to linear optimization
Another popular method for finding the sparse vector s is matching pursuit(https://en.wikipedia.org/wiki/Matching_pursuit). The essence of this method is to find the first basis function a_i from a given matrix A such that it fits into the input vector x with the largest coefficient s_i in comparison with other basis functions.After subtracting a_i*s_i from the input vector, we add the next basis function to the resulting residue, and so on, until we reach the given error. An example of the matching pursuit method is the following indicator, which inscribes one sinusoid after another in the input vector with the smallest residual: https://www.mql5.com/ru/code/130.
If the basis functionsA(dictionary) are not known to us beforehand, we need to find them from the input datax using methods called dictionary learning. This is the most complicated (and for me the most interesting) part of the sparse coding method. In my previous lecture I showed how these functions can be found, for example, by Oji's rule, which makes these functions principal vectors of input quotes. Unfortunately, this kind of basis functions does not lead to disjoint description of input data (i.e. vector s is nonsparse).
The existing methods of dictionary learning leading to disjoint linear transformations are divided into
Probabilistic methods for finding basis functions are reduced to maximize maximum likelihood:
maximize P(x|A) over A.
Usually the assumption is made that the approximation error has a Gaussian distribution, which leads us to solve the following optimization problem:
(1)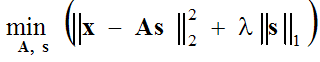 ,
,
which is solved in two steps: (1-sparse coding step) with basis functions A fixed, the expression in parentheses is minimized with respect to vector s, and (2-dictionary update step) the found vectors is fixed and the expression in parentheses is minimized with respect to basis functions A using gradient descent method:
(2)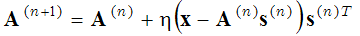
where (n+1) and (n) in the superscript denote iteration numbers. These two steps (sparse coding step and dictionary learning step) are repeated until a local minimum is reached. This probabilistic method of finding basis functions is used in e.g.
Olshausen, B. A., & Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Learning overcomplete representations. Neural Comput., 12(2), 337-365.
The Method of Optimal Directions (MOD) uses the same two optimization steps (sparse coding step and dictionary learning step), but in the second optimization step (dictionary update step) the basis functions are calculated by equating the derivative of the expression in brackets (1) with respect to A to zero:
where we get
(3)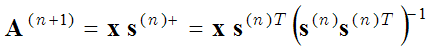 ,
,
where s+ is the pseudo-inverse matrix. This is a more accurate calculation of the basis matrix than the gradient descent method (2). The MOD method is described in more detail here:
K. Engan, S.O. Aase, and J.H. Hakon-Husoy. Method of optimal directions for frame design. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, pp. 2443-2446, 1999.
Calculating pseudo-inverse matrices is laborious. The k-SVD method avoids calculating them. I haven't figured it out yet myself. You can read about it here:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Processing, 54(11), November 2006.
I have not yet understood the clustering and on-line methods of finding the dictionary, either. I refer those interested to the following review:
R. Rubinstein, A. M. Bruckstein, and M. Elad, "Dictionaries for sparse representation modeling," Proc. of IEEE , 98(6), pp. 1045-1057, June 2010.
Here are some interesting video lectures on this topic:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
That's all for now. I will expand on this topic in future posts as I am able, as well as interest from visitors to this forum.
Nikolai, you know a popular phrase -- premature optimization is the root of all evils.
It's such a common phrase for developers to cover up their uselessness, that you can get a slap on the wrist for every time you use it.
The phrase is fundamentally harmful and absolutely wrong, if we are talking about development of quality software with long life cycle and direct orientation on rapidity and high loads.
I've checked it many times in my many years of project management practice.
This is such a common phrase to cover up the developers' fuck-ups that you can get a slap on the wrist for every time you use it.
So you have to take into account some features that will appear who knows when with who knows what interface in advance because it gives you a performance boost?
I've tested this many times in my years of project management practice.
I use my experience every day in our developments and try to run a system of public projects in MQL5. At the first stage my participation is expressed through managing the process of building the infrastructure of repositories and projects. Then there will be coordination and financing of interesting works.