Discussion of article "Applying Monte Carlo method in reinforcement learning"
I would like to contribute to the observations:
Benefits of this version:
*************************************
1. Unlike previous versions, this version does not trade all the time. It trades selectively when the signal is good. This is a huge advantage to meet your needs. Otherwise, it's a good thing.))) ..
2. It can be optimised quickly and easily.
3. The size of the trainer model is small, so we can train big data
The disadvantages of this version:
*******************************************
1. Many times it takes a lot of time for future passes and hence we have to manually stop the optimisation process.
2. For some reasons it is not so easy to run the tests. I have to restart my MT5 terminal and still sometimes it doesn't work.
My suggestions for improvement:
*************************************
1. Try to use at least 4 to 5 input functions for training such as open, close, high, low.
2.Try to use "MathMoments ()" functions properly when getting optimised in getting trading signals:
h ttps:// www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3. Try to implement an iterative training course on a daily or weekly basis.
This is a randomised result.
4. Try multiple time periods.
I need to do this. how can we do it better :))))

- www.mql5.com
The Monte Carlo method is certainly an effective method for studying random processes. However, the application of this method (as well as any other) should take into account the nature of the process (for us it is financial markets).
The problem of modern analytics is that so far, neither traditional TA nor other methods have been able to reveal the elementary structure of market price movements (like an atom in physics), and the available structures (TA patterns, Elliott waves and others) are not elementary, as they are not continuous for analysis (they appear ambiguously or rarely). Therefore, the use of modern methods is almost a blind search for the so-called "best model" by brute force method (in this case by Monte Carlo method).
But this is a problem for the analytics industry as a whole. And the author, within the framework of the method, showed original solutions - thanks for the work!
Respect to the author, for another interesting article, for an open and constructive approach to the MO, despite the secret, mouse fiddling of other participants of the topic and the administration's zugunder:)
Specifically on the subject - I don't quite understand the point of Monte Carlo shooting to find targets, because they are almost unambiguously deterministic and can be found an order of magnitude faster, according to the vertices of the zigzag or the values of the same returns.
IMHO, it would be more rational to apply this method to a much more uncertain and multidimensional problem, such as the selection and ranking of predictors. Ideally, when solving this problem, predictors should be evaluated in a complex, and the search and alternate training on each separately described in the article looks like a system of equations with one unknown.
Respect to the author, for another interesting article, for an open and constructive approach to the MO, despite the secret, mouse fiddling of other participants of the topic and the administration's zugunder:)
Specifically on the subject - I don't quite understand the point of Monte Carlo shooting to find targets, because they are almost unambiguously deterministic and can be found an order of magnitude faster, in accordance with the vertices of the zigzag or the values of the same returns.
IMHO, it would be more rational to apply this method to a much more uncertain and multidimensional problem, such as the selection and ranking of predictors. Ideally, when solving this problem, predictors should be evaluated in a complex, and the search and alternate training on each separately described in the article looks like making up systems of equations with one unknown.
Respect to the author, for another interesting article, for an open and constructive approach to the MO, despite the secret, mouse fiddling of other participants of the topic and the administration's zugunder:)
Specifically on the subject - I don't quite understand the point of Monte Carlo shooting to find targets, because they are almost unambiguously deterministic and can be found an order of magnitude faster, in accordance with the vertices of the zigzag or the values of the same returns.
IMHO, it would be more rational to apply this method to a much more uncertain and multidimensional problem, such as the selection and ranking of predictors. Ideally, when solving this problem, predictors should be evaluated in a complex, and the search and alternate training on each separately described in the article looks like making up systems of equations with one unknown.
As for "unambiguously deterministic" - this is incorrect, because TA figures and "returns" are very ambiguous and unreliable things to analyse.
Therefore, the author does not use them, but experiments with the Monte Carlo method.
Hi Maxim.
One question.
"shift_probab" and "regularisation" The values used are for optimisation only and NOT in the course of live trading. Am I right?
Or is it necessary to set the optimised shift_probab and regularisation values on the chart after each optimisation is completed for live trading?
Thanks.
Hi, through Monte Carlo there is a random enumeration of targets, according to all the canons of RL. That is, there are many strategies (steps), the agent searches for the optimal one, through the minimum error on the oos. The construction of new features is also implemented in one of the libraries via MSUA (see codobase). This paper implements just a brute force search of existing fiches, without constructing new ones. See Recursive elimination method. That is, both fiches and targets are recursively eliminated. Later I can suggest other variants, there are actually a lot of them. But comparative tests take a lot of time.
Hi, of course, random selection of actions is the canons of RL, moreover, it may be necessary because different actions of the agent may change the environment, which generates a number of variants tending to infinity, and of course Monte Carlo may well be applied to optimise the sequence of such actions.
But in our case, the environment - market quotes do not depend on the agent's actions, especially in the considered implementation, where historical, known in advance data are used, and therefore the choice of the sequence of actions (trades) of the agent can be made without stochastic methods.
P.S. for example, it is possible to find the target sequence of trades with the maximum possible profit by quotations https://www.mql5.com/en/code/9234.

- www.mql5.com
Hi Maxim.
One question.
"shift_probab" and "regularisation" The values used are for optimisation only and NOT in the course of live trading. Am I right?
Or is it necessary to set the optimised shift_probab and regularisation values on the chart after each optimisation is completed for live trading?
Thanks.
Hi, of course, random selection of actions is the canons of RL, moreover, it may be necessary because different actions of the agent may change the environment, which generates a number of options tending to infinity, and of course Monte Carlo may well be applied to optimise the sequence of such actions.
But in our case, the environment - market quotes do not depend on the agent's actions, especially in the considered implementation, where historical, known in advance data are used, and therefore the choice of the sequence of actions (trades) of the agent can be made without stochastic methods.
P.S. for example, it is possible to find the target sequence of trades with the maximum possible profit by quotations https://www.mql5.com/en/code/9234.
About being "unambiguously deterministic" is wrong, as TA figures and "returns" are very ambiguous and unreliable things to analyse.
Therefore, the author does not use them, but experiments with the Monte Carlo method.
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Applying Monte Carlo method in reinforcement learning has been published:
In the article, we will apply Reinforcement learning to develop self-learning Expert Advisors. In the previous article, we considered the Random Decision Forest algorithm and wrote a simple self-learning EA based on Reinforcement learning. The main advantages of such an approach (trading algorithm development simplicity and high "training" speed) were outlined. Reinforcement learning (RL) is easily incorporated into any trading EA and speeds up its optimization.
After stopping the optimization, simply enable the single test mode (since the best model is written to the file and only that model is to be uploaded):
Let's scroll the history for two months back and see how the model works for the full four months:
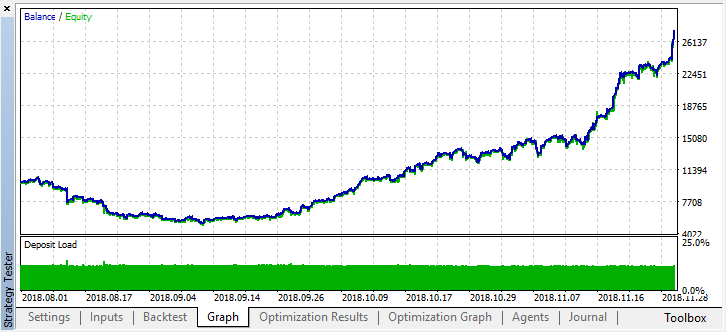
We can see that the resulting model lasted another month (almost the entire September), while breaking down in August.Author: Maxim Dmitrievsky