Diskussion zum Artikel "Propensity Score in der Kausalinferenz"
https://www.mql5.com/de/code/48482
Ein Archiv der Modelle aus dem Artikel (mit Ausnahme des allerersten in der Liste), zum schnellen Nachschlagen ohne Installation von Python.

- www.mql5.com
Hallo, ich habe Ihre Methode verwendet: propensity_matching_naive.py in den Parametern habe ich das Training von 25 Modellen eingestellt. Nach dem Training erschien im Python-Verzeichnis der Ordner :
catboost_info .
Was habe ich versucht zu tun? Geladen AUDCAD h1 Zitate, dann mit der Datei :
propensity_matching_naive.py aus Ihrer Veröffentlichung : https://www.mql5.com/de/articles/14360.
Ich verstehe nicht, was ich als nächstes tun soll, was ich weiter im ONNX-Format speichern soll, oder funktioniert diese Methode nur als Test zur Qualitätsbewertung? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
Ich benutze pythom zum ersten Mal in meinem Leben, installiert ohne Probleme, Bibliotheken sind auch nicht schwer. Ich habe Ihre Veröffentlichungen gelesen, seriöser Ansatz, aber vielleicht nicht die einfachste Methode der Berechnung, ich kann mich irren, alles ist relativ.
Ich habe Bildschirme beigefügt, was ich in meiner Ausbildung bekam.
 в причинно-следственном выводе")
- www.mql5.com
{kind=link}
{kind=link}
Hallo, ich habe Ihre Methode verwendet: propensity_matching_naive.py in den Parametern habe ich das Training von 25 Modellen eingestellt. Nach dem Training erschien in der Python-Verzeichnis Ordner :
catboost_info .
Was habe ich versucht zu tun? Geladen AUDCAD h1 Anführungszeichen, dann mit der Datei :
propensity_matching_naive.py aus Ihrer Veröffentlichung : https://www.mql5.com/de/articles/14360.
Ich verstehe nicht, was ich als nächstes tun soll, was ich weiter im ONNX-Format speichern soll, oder funktioniert diese Methode nur als Test zur Qualitätsbewertung? :
catmodel propensity matching naive.onnx
catmodel_m propensity matching naive.onnx
Ich benutze pythom zum ersten Mal in meinem Leben, habe es ohne Probleme installiert, die Bibliotheken sind auch nicht schwierig. Ich habe Ihre Veröffentlichungen gelesen, seriöser Ansatz, aber vielleicht nicht die einfachste Methode der Berechnung, ich kann mich irren, alles ist relativ.
Ich habe Bildschirme beigefügt, was ich in meiner Ausbildung bekam.
Gut. in früheren Artikeln beschrieben 2 Möglichkeiten zu exportieren.
1. die frühere, Exportieren des Modells in nativen MQL-Code
2. Export in das onnx-Format in späteren Artikeln.
Ich kann mich nicht erinnern, ob es in den Python-Dateien zu diesem Artikel eine Exportfunktion für das Modell gibt. "export_model_to_ONNX()", Wenn nicht, können Sie von den früheren nehmen.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
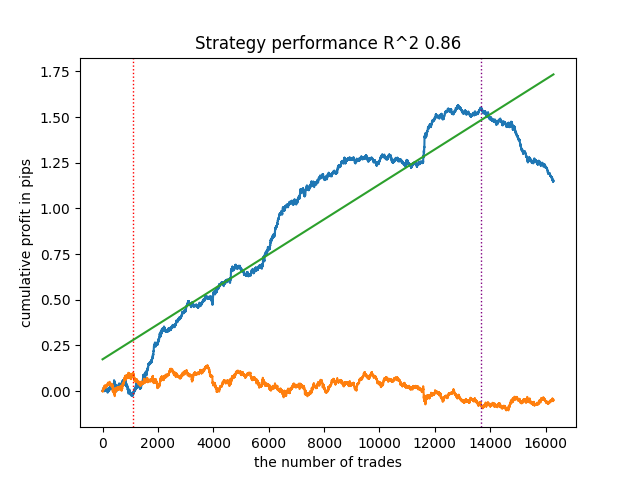
Neuer Artikel Propensity Score in der Kausalinferenz :
Der Artikel befasst sich mit dem Thema Abgleich von Kausalschlüssen. Der Abgleich wird für den Vergleich sich ähnlichen Beobachtungen in einem Datensatz. Dies ist notwendig, um kausale Wirkungen korrekt zu bestimmen und Verzerrungen zu beseitigen. Der Autor erklärt, wie dies beim Aufbau von Handelssystemen auf der Grundlage des maschinellen Lernens hilft, die bei neuen Daten, auf denen sie nicht trainiert wurden, stabiler werden. Der Propensity Score (Tendenzbewertung) spielt eine zentrale Rolle und wird häufig bei Kausalschlüssen verwendet.
In diesem Artikel werde ich das Thema Abgleichen (matching) behandeln, das im vorherigen Artikel kurz angesprochen wurde, bzw. eine seiner Varianten, dem Propensity Score matching.
Dies ist wichtig, weil wir einen bestimmten Satz von gekennzeichneten Daten haben, der heterogen ist. Im Devisenhandel beispielsweise kann jedes einzelne Trainingsbeispiel zu einem Bereich mit hoher oder niedriger Volatilität gehören. Außerdem kann es sein, dass einige Beispiele häufiger in der Stichprobe vorkommen, während andere weniger häufig vorkommen. Bei dem Versuch, den durchschnittlichen kausalen Effekt (ATE) in einer solchen Stichprobe zu bestimmen, werden wir unweigerlich auf verzerrte Schätzungen stoßen, wenn wir davon ausgehen, dass alle Beispiele in der Stichprobe die gleiche Tendenz haben, eine Behandlung durchzuführen. Bei dem Versuch, einen konditionalen durchschnittlichen Behandlungseffekt (CATE) zu ermitteln, können wir auf ein Problem stoßen, das als „Fluch der Dimensionen“ bezeichnet wird.
Matching ist eine Familie von Methoden zur Schätzung kausaler Effekte durch den Abgleich ähnlicher Beobachtungen (oder Einheiten) in Behandlungs- und Kontrollgruppen. Der Zweck des Abgleichens besteht darin, Vergleiche zwischen ähnlichen Einheiten anzustellen, um eine möglichst genaue Schätzung der wahren kausalen Wirkung zu erhalten.
Autor: Maxim Dmitrievsky