Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe. - Seite 21
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Ich habe zwei weitere Jahre aus dieser Stichprobe herausgeschnitten, und der Prüfungsdurchschnitt ist bereits auf -485 gestiegen (er lag bei 1214), und die Zahl der Modelle, die die 3000-Punkte-Grenze überschritten haben, ist auf 884 gestiegen ( beim letzten Mal waren es 277).
Die Ergebnisse der Teststichprobe haben sich jedoch von einem Durchschnitt von 2115 auf 186 Punkte verschlechtert, d. h. deutlich. Woran liegt das - gibt es in der Zugstichprobe weniger ähnliche Beispiele wie in der Teststichprobe?
Die durchschnittliche Anzahl der Bäume ist von 10 auf 7 gesunken.
Der Nulldurchgang in der Grafik hat die Gleichgewichtsverteilung in die Mitte verschoben.
Worauf stützt sich die Aussage, dass das Ergebnis dem Test ähnlich sein sollte? Ich gehe davon aus, dass die Stichproben nicht homogen sind - es gibt keine vergleichbare Anzahl ähnlicher Beispiele in ihnen, und ich denke, dass sich die Wahrscheinlichkeitsverteilungen über die Quanten ein wenig unterscheiden.
Traine. Ich spreche von Daten, bei denen es gute Muster gibt. Wenn man 1000 Varianten der Multiplikationstabelle in das Training einspeist, werden auch neue Varianten, die nie mit der Trainee übereinstimmen (aber innerhalb der Grenzen der Trainee liegen), recht gut berechnet. Ein Baum wird die nächstgelegene Variante liefern, ein Zufallsforst wird den Durchschnitt der hundert nächstgelegenen Varianten bilden und höchstwahrscheinlich eine genauere Antwort als mit einem Baum geben.
Wenn Prädiktoren mit Regelmäßigkeit für den Markt gefunden werden können, dann wird OOS auch ähnlich wie eine Spur sein. Aber nicht so wie jetzt, wo mehr als die Hälfte der Modelle im Minus und ein Drittel im Plus ist. Alle erfolgreichen Modelle sind zufällig so geworden, durch zufällige Aussaat.
Das Saatgut sollte den Erfolg des Modells nur geringfügig beeinflussen und im Allgemeinen sollten alle Modelle erfolgreich sein. Nun stellt sich heraus, dass keine Muster gefunden werden (weder Übertraining noch Untertraining).
Sie dient nur zur Kontrolle des Trainingsstopps, d.h. wenn es keine Verbesserung im Test gibt, während auf train train trainiert wird, dann wird das Training gestoppt und die Bäume werden bis zu dem Punkt entfernt, an dem es die letzte Verbesserung im Testmodell gab.
Es ist dann klar, warum auch die Tests gut sind. Es ist im Wesentlichen eine Anpassung an den Test. Ich habe das für 1 Training eingestellt. Ich führe das Valving vorwärts durch, klebe alle OOCs zusammen und wähle dann die besten Modellhyperparameter (Tiefe, Anzahl der Bäume usw.) aus den vielen Varianten der geklebten OOCs. Ich gehe davon aus, dass die Prüfung in etwa so ausfallen wird wie die ausgewählte Verklebung aller OOS. In dieser Variante über 5 Jahre, habe ich Umschulung einmal pro Woche - das ist Hunderte von OOS Ausbildung und Chunks.
Offensichtlich habe ich nicht klar angegeben, welche Stichprobe ich verwendet habe - dies ist die sechste (letzte) Stichprobe aus dem hier beschriebenen Experiment, es gibt also nur 61 Prädiktoren.
primitive Strategien, insbesondere in flachen Marktgebieten.Nun, Sie haben diese 61 aus über 5000 ausgewählt. Meine Gesamtzahl ist geringer und die Anzahl der ausgewählten ist geringer. Und wenn man nach 3-4 ausgewählten Vorzeichen jeweils 1 hinzufügt, verschlechtert sich das Ergebnis beim OOS nur noch weiter.
Im Allgemeinen kann ich mehr Prädiktoren hinzufügen, weil sie jetzt nur mit 3 TFs verwendet werden, mit ein paar Ausnahmen - ich denke, dass ein paar tausend mehr hinzugefügt werden können, aber ob alle richtig im Training verwendet werden, ist zweifelhaft, da 10000 Varianten von Seed für 61 Prädiktoren eine solche Ausbreitung geben....
Und natürlich müssen Sie die Prädiktoren vorab überprüfen, was das Training beschleunigt.
Wenn sie alle ungefähr gleich sind, ist es unwahrscheinlich, dass etwas gefunden wird, das das Ergebnis ernsthaft verbessert. Sie können völlig neue Daten oder einzigartige Indikatoren ausprobieren.
Das Vorab-Screening ist ebenfalls eine langwierige Arbeit, das Hinzufügen eines Merkmals nach dem anderen dauert um ein Vielfaches länger, selbst bei bis zu 3 Merkmalen, und wenn es bis zu 10 sind, dauert es viele Tage. Aber es hat keinen Sinn, denn nach 3-4 Merkmalen gibt es normalerweise keine Verbesserung mehr. Gelegentlich gibt es sie aber, aber die Steigerung ist gering. Durchbrüche wurden dort nicht gefunden (in meinen Experimenten, kann jemand finden).
Es ist logisch, dass Ausreißer Ausreißer sind, ich denke nur, dass es sich dabei um Ineffizienzen handelt, die durch das Entfernen des weißen Rauschens erlernt werden sollten. In anderen Bereichen funktionieren oft einfache, primitive Strategien, insbesondere in flachen Marktbereichen.
Das untere Bild ist profitabel, aber in 5 Jahren gab es nur 2 Perioden im Jahr 2017 mit starkem Wachstum (anscheinend gab es einen starken vorhersehbaren Trend), das Modell machte das meiste Geld in diesen 2 Perioden. Und es wäre schön, ein gleichmäßiges Wachstum über die Zeit zu haben. Ich würde ein solches Modell nach einem Monat der Inaktivität abschalten.
Sie können natürlich einen EA erstellen - und auf weiße Schwäne warten. Aber ich würde aktives Handeln bevorzugen.
Schneiden Sie zwei weitere Jahre aus dieser Stichprobe heraus, und der Prüfungsdurchschnitt liegt bereits bei -485 (vorher - 1214), und die Zahl der Modelle, die die 3000-Punkte-Grenze überschreiten, liegt bei 884 ( vorher 277).
Die Ergebnisse der Stichprobe haben sich jedoch von einem Durchschnitt von 2115 auf 186 Punkte verschlechtert, d.h. deutlich. Woran liegt das - gibt es in der Zugstichprobe weniger ähnliche Beispiele wie in der Teststichprobe?
Die durchschnittliche Anzahl der Bäume sank von 10 auf 7.
Der Nulldurchgang in der Grafik hat die Gleichgewichtsverteilung in die Mitte verschoben.
Können Sie die Dateien aus dem ersten Beitrag posten, ich möchte auch eine Idee ausprobieren.
Traine. Ich spreche von Daten, bei denen es gute Muster gibt. Wenn Sie 1000 Varianten der Multiplikationstabelle zum Training vorlegen, werden auch neue Varianten, die nie mit dem Trainee übereinstimmen (aber innerhalb der Grenzen des Trainees liegen), gut berechnet. Ein Baum wird die nächstgelegene Variante liefern, ein Random Forest wird den Durchschnitt der hundert nächstgelegenen Varianten bilden und höchstwahrscheinlich eine genauere Antwort liefern als ein Baum.
Wenn Prädiktoren mit Regelmäßigkeit für den Markt gefunden werden können, dann wird OOS auch ähnlich wie eine Spur sein. Aber nicht so wie jetzt, wo mehr als die Hälfte der Modelle im Minus und ein Drittel im Plus sind. Alle erfolgreichen Modelle sind zufällig so geworden, aus einer zufälligen Saat.
Das Saatgut sollte den Erfolg des Modells nur geringfügig beeinflussen und im Allgemeinen sollten alle Modelle erfolgreich sein. Nun stellt sich heraus, dass keine Muster gefunden werden (weder Übertraining noch Untertraining).
Niemand bestreitet, dass mit guten Daten höchstwahrscheinlich alles perfekt funktionieren wird. Aber solche Daten bekommt man nicht, also muss man überlegen, was man aus dem, was man hat, herausholen kann.
Die Tatsache, dass es möglich ist, zufällig wirksame Modelle zu erhalten, die auch bei neuen Daten wirksam sind, veranlasst mich zu der Frage, wie man diese Zufälligkeit reduzieren kann, d. h., ob es irgendwelche regulären Metriken für Quantensegmente gibt, auf denen das Modell konsequent aufgebaut wurde. D.h. wir sprechen von zusätzlichen Metriken außer der Gier auf das Ziel. Wenn solche Abhängigkeiten festgestellt werden können, dann können auch Modelle mit einer höheren Erfolgswahrscheinlichkeit gebaut werden. Natürlich sollte dies bei verschiedenen Stichproben funktionieren.
Dann kann ich auch verstehen, warum die Tests gut sind. Es ist im Wesentlichen eine Anpassung an den Test. Ich habe aufgehört, das für 1 Studie zu tun. Ich mache Valving vorwärts, klebe alle OOCs zusammen und wähle dann die besten Modellhyperparameter (Tiefe, Anzahl der Bäume usw.) aus den vielen Varianten der geklebten OOCs. Ich gehe davon aus, dass die Prüfung in etwa so ausfallen wird wie die ausgewählte Verklebung aller OOS. In dieser Variante habe ich über 5 Jahre hinweg einmal pro Woche neu trainiert - das sind Hunderte von OOS-Trainings und Chunks.
Die Hauptsache ist, den letzten Prüfungsabschnitt nicht zu trennen.
Anpassung von Hyperparametern und Bewertung des Ergebnisses auf welcher Grundlage? Ich denke, es ist die gleiche Anpassung mit einem Element der Mittelwertbildung, wenn wir Ihrer Logik folgen.
Die Logik in CatBoost ist, dass, wenn es unmöglich ist, das Modell zu verbessern (durch Logloss), es keinen Sinn hat, weiter zu trainieren. In diesem Fall gibt es natürlich keine Garantie, dass das Modell gut ist.
Nun, diese 61 hast du aus 5000+ herausgesucht. Ich habe sowohl die Gesamtzahl als auch die Anzahl der ausgewählten Fälle. Und beim Hinzufügen von 1 zu einer Zeit, nach 3-4 ausgewählten, weitere Zugabe von Funktionen nur verschlechtert das Ergebnis auf OOS.
Nein, ich habe sie nicht ausgewählt - ich habe sie beim Training mit allen Prädiktoren aus dem Modell genommen.
Ich betrachte den Prädiktor im Allgemeinen als eine Menge von Quantensegmenten. Und aus diesem Grund wähle ich Quantensegmente, im Allgemeinen kann ich sogar alle Prädiktoren in binäre zerlegen - das Ergebnis ist etwas schlechter, aber vergleichbar. Vielleicht ist für binär entladene Prädiktoren eine spezielle Trainingsmethode erforderlich.
Wenn sie alle in etwa gleich sind, ist es unwahrscheinlich, dass bereits etwas gefunden werden kann, das das Ergebnis ernsthaft verbessert. Sie können es mit völlig neuen Daten oder einzigartigen Indikatoren versuchen.
Was meinen Sie mit "ungefähr gleich", ich nehme an, Sie sprechen von Metriken oder was? Natürlich können Sie andere Daten ausprobieren, z. B. ein anderes Tool.
Pre-Screening ist auch eine langwierige Arbeit, wenn man eins nach dem anderen hinzufügt, dauert es um ein Vielfaches länger, sogar bis zu 3 Features, und wenn es bis zu 10 sind, dauert es viele Tage. aber es hat keinen Sinn, nach 3-4 Features gibt es normalerweise keine Verbesserung. Gelegentlich gibt es aber eine, aber die Steigerung ist gering. Durchbrüche wurden dort nicht gefunden (in meinen Experimenten, kann jemand finden).
Die Variante, von der Sie sprechen, ist ein langwieriges Spiel, deshalb spiele ich es nicht (nun, ich habe keine vollständige Automatisierung). Aber ich stimme nicht zu, dass es keinen Effekt gibt - ich habe Dropouts in Gruppen durchgeführt, mit der Reduzierung von Gruppen - das Ergebnis war positiv. Aber ich schreibe diese Aktionen immer noch der Anpassung oder dem Zufall zu - es gibt keine Rechtfertigung für die Wahl der Prädiktoren.
Die untere Zahl ist profitabel, aber in 5 Jahren gab es nur 2 Perioden im Jahr 2017 mit starkem Wachstum (anscheinend gab es einen starken vorhersagbaren Trend), das Modell machte das meiste Geld auf diese 2 Perioden. Und es wäre schön, ein gleichmäßiges Wachstum über die Zeit zu haben. Ich würde ein solches Modell nach einem Monat der Inaktivität abschalten.
Natürlich kann man einen Expert Advisor erstellen, der auf weiße Schwäne wartet. Aber ich würde aktives Handeln bevorzugen.
Das ist, warum ich bin für die Verwendung von Sätzen von Modellen, wie ich verstehe, dass jeder seine eigene nicht häufige Muster fangen kann.
Nun, im Allgemeinen ist es das Ziel, dass der Fehler bei Trainee und Test ungefähr gleich groß ist. Hier bewegt sich Ihre Prüfung in Richtung der Ausbildung und des Tests, d.h. nach oben, und sie in Richtung des Tests, d.h. nach unten. Übertraining geht nach unten.
Und nach welchen Maßstäben sind sie ähnlich?
Nehmen wir z.B. die Metrik Precision, subtrahieren wir diesen Indikator auf der Teststichprobe von Train, - wir erhalten Delta (y-Achse), und mit x betrachten wir den Gewinn auf der Prüfungsstichprobe.
Es gibt keine besondere Abhängigkeit, oder was?
Nachfolgend finden Sie zwei Metriken für jede Stichprobe - die Daten werden entnommen, wenn dem Modell neue Bäume hinzugefügt werden.
Hier sind die Merkmale dieses Modells
Und hier sind die Kennzahlen eines anderen Modells, mit Verlusten bei zwei Stichproben
Hier sind die Merkmale des Modells
Es ist unpraktisch, im Forum zu antworten, indem man mehrmals auf "Antworten" klickt. Unten sind meine Antworten farblich hervorgehoben.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Habe vor langer Zeit beobachtet, wie Quanten aufgebaut sind, Grundvarianten. Zuerst wird die Spalte sortiert.
1) nach Bereich, gleichmäßiger Schritt (z.B. von 0 bis 1 mit Werteschritt genau durch 0,1, insgesamt 10 Quanten 0,1, 0,2, 0,3 ... 0,9)
2) Perzentil - d.h. nach der Anzahl der Beispiele. Wenn wir durch 10 Quanten teilen, dann setzen wir in jedes Quantum 10% der Anzahl aller Zeilen, wenn es viele Doppelgänger gibt, dann werden einige Quanten mehr als 10% sein, weil die Doppelgänger nicht in andere Quanten fallen sollten, zum Beispiel, wenn die Doppelgänger 30% der Probe sind, dann werden sie alle in dieses Quantum fallen. Je nach Anzahl der Stichproben in jedem Quantum könnte die Verteilung 0,001, 0,12, 0,45, 0,51, 0,74, .... sein. 0,98.
3) Es gibt eine Kombination aus beiden Typen
Die Konstruktion von Quanten ist also nicht besonders clever. Ich habe diese beiden Quantisierungsmethoden für mich selbst gemacht. Und wie immer habe ich etwas so gemacht, wie ich es für besser halte. Vielleicht habe ich einen Fehler gemacht. Und ich mache normalerweise Berechnungen ohne Quantisierung, aber mit Float-Daten.
Wenn man alle Prädiktoren binär macht, dann gibt es nur 2 Quanten, eine hat alle 0's und die andere hat alle 1's.
Sie passen Hyperparameter an und werten das Ergebnis wie aus? Ich denke, es ist die gleiche Anpassung mit einem Mittelungselement, wenn man Ihrer Logik folgt.
> Ich schaue mir Balance-Charts und Drawdowns an. Ich habe die Auswahl noch nicht automatisieren können. Ja, die Anpassung dient der besseren OOS-Verklebung. Aber nicht das Modell selbst (d. h. nicht die Kurve), sondern die Auswahl der besten Hyperparameter des Modells.
Was meinen Sie mit "ungefähr gleich", ich nehme an, Sie sprechen von irgendwelchen Metriken oder was? Natürlich können Sie auch andere Daten ausprobieren, zum Beispiel mit einem anderen Tool.
> Alle von ihnen sind auf Preise und Mashups gemacht.
Zu einer alten Frage.
Worauf stützt sich die Aussage, dass das Ergebnis dem Zug ähnlich sein sollte? Ich gehe davon aus, dass die Stichproben nicht homogen sind - es gibt keine vergleichbare Anzahl ähnlicher Beispiele, und ich denke, dass die Wahrscheinlichkeitsverteilungen der Quanten leicht unterschiedlich sind.
> Beispiele hier https://www.mql5.com/ru/articles/3473
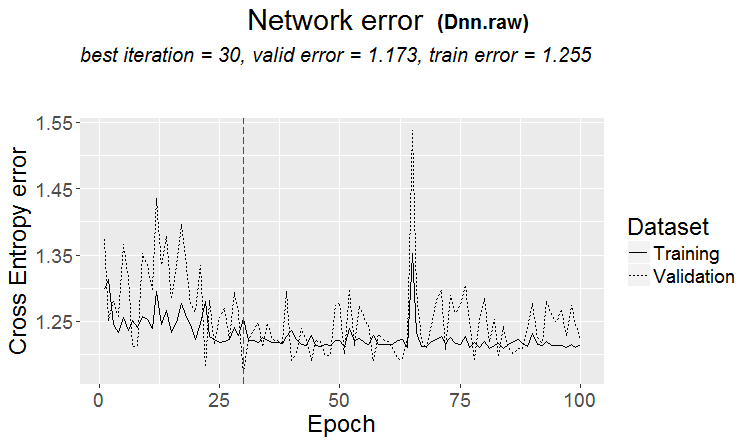
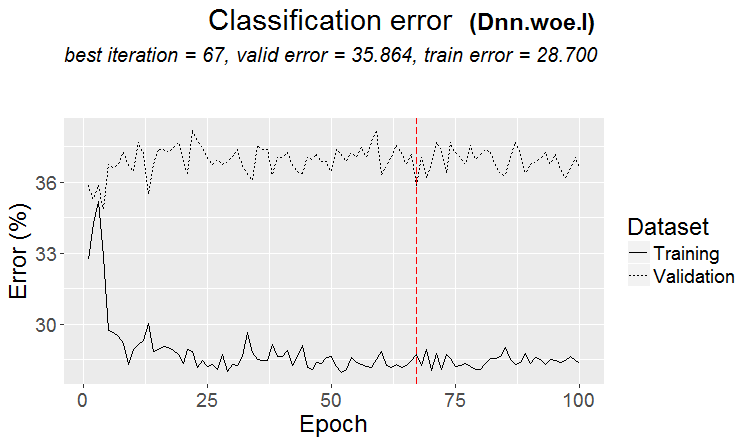
Eine gute Variante ist, wenn ein Muster gefunden wird: Ternär und Test haben fast den gleichen Fehler
Auf den Märkten passiert häufiger so etwas: ein guter Test, aber nach einem Trainingsschritt (in der Abbildung nach dem 3. Schritt) beginnt das Retraining und der Testfehler beginnt zu wachsen. Die Bilder beziehen sich auf neuronale Netze, aber so etwas gibt es auch bei Forests und Boosts, wenn das Modell übertrainiert wird.
Nach welcher Metrik sind sie ähnlich?
Aber das bedeutet nicht, dass Ihre Metriken schlecht sind.
Es gibt also nichts superschlaues in der Quantenkonstruktion. Ich habe diese beiden Quantisierungsmethoden für mich gemacht. Und wie immer habe ich etwas so gemacht, wie ich es für besser halte. Vielleicht habe ich einen Fehler gemacht. Und ich mache normalerweise Berechnungen ohne Quantisierung, sondern mit Float-Daten.
Natürlich gibt es verschiedene Methoden, ich verwende jetzt etwa 900 Quantentabellen.
Der springende Punkt ist nicht die Methode, sondern die Wahl des Bereichs des Prädiktors, in dem der Durchschnittswert des binären Ziels höher ist als in der Stichprobe (jetzt setze ich ein Minimum von 5% plus Kriterien für die Anzahl der Beispiele - ebenfalls ein Minimum von 5%), was auf nützliche Informationen im Prädiktor hinweist. Wenn es keine solche Information gibt, kann man hoffen, dass sie in einigen Splits auftaucht, aber ich halte das für weniger wahrscheinlich.
In der Tat kommt es vor, dass es 1-2 solcher Plots gibt, selten sind es wirklich viele. Und hier kann man entweder nur diese Plots nehmen, oder nur Prädiktoren mit solchen Plots, wobei man die beste Quantentabelle wählt.
Ich persönlich habe gesehen, dass die Prädiktoren, zumindest meine, keine fließenden Übergänge der Wahrscheinlichkeiten haben, sondern es passiert diskontinuierlich und wechselt in die entgegengesetzte Abweichung, d.h. es war +5 und wurde sofort zu -5. Ich denke sogar, dass das Modell leichter zu trainieren ist, wenn diese Wahrscheinlichkeiten geordnet sind, da sie auf Bereiche trainiert werden. Aus diesem Grund ist es sinnvoll, uninformative Bereiche auszuschließen und die widersprüchlichen Bereiche zu trennen.
Wenn man alle Prädiktoren binär macht, gibt es nur 2 Quanten, eine mit allen 0's und eine mit allen 1's.
Eigentlich gibt es dann nur ein - 0,5 :) Aber auf diese Weise kann man den Prädiktor in nützliche Bereiche zerlegen (die potentiell nützliche Informationen enthalten).
> Betrachtung von Balance-Charts und Drawdowns. Das Automatisieren der Auswahl hat noch nicht geklappt. Ja, Fitting - für die beste OOS-Klebung. Aber nicht das Modell selbst (d.h. nicht die Kurve), sondern die Auswahl der besten Hyperparameter des Modells.
Nun, das ist verständlich, aber nicht kanonisch - Modellmetriken sind auch wichtig, denke ich.
> Alles was mit Preisen und Mashups gemacht wird.
In der Theorie ja, und das, wenn man neuronale Netze verwendet, aber in der Tat - nein - zu komplexe Abhängigkeiten sollten mit verschiedenen Berechnungen gesucht werden, für diese einfach nicht die Rechenleistung der normalen Benutzer haben.
Zu einer alten Frage.
> Beispiele hier https://www.mql5.com/ru/articles/3473
Eine gute Variante ist, wenn ein Muster gefunden wird: ternär und Test haben fast den gleichen Fehler
Auf den Märkten passiert häufiger so etwas wie das: ein guter Test, aber nach einem Trainingsschritt (in der Abbildung nach dem 3.) beginnt das Umlernen und der Testfehler beginnt zu wachsen. Die Bilder beziehen sich auf neuronale Netze, aber so etwas gibt es auch bei Forests und Boosts, wenn das Modell übertrainiert wird.
Die Regelmäßigkeit wird immer gefunden - das ist das Prinzip - die Frage ist, ob diese Regelmäßigkeit weiterhin auftritt oder nicht.
Ich weiß nicht, welche Art von Stichprobe Sie hatten. Ich habe Fälle erlebt, in denen der Test schneller lernt als der Zug, aber häufiger ist es umgekehrt, und es besteht ein deutlicher Unterschied zwischen den beiden. Unter idealen Bedingungen ist der Unterschied natürlich gering.
Ich kann mit Sicherheit sagen, dass die Modelle untertrainiert sind, weil die Stichproben nicht sehr ähnlich sind und das Training aufhört, wenn keine Verbesserung eintritt.
Eines Tages werde ich Ihnen zeigen, wie die neu trainierte Stichprobe grafisch aussieht - sie besteht aus zwei Ausbuchtungen, die durch Ecken getrennt sind....
Halbieren Sie die Ausbildungsprobe weiter.
Es gibt nur 306 Modelle, der durchschnittliche Gewinn bei der Prüfung beträgt -2791 Punkte.
Aber ich habe dieses Modell
Mit diesen Eigenschaften
Die Mat-Erwartung ist sicherlich gesunken, aber der Rückruf ist doppelt so hoch - deshalb und wegen einer solchen Grafik mit einer großen Anzahl von Geschäften.
Solche Prädiktoren wurden verwendet:
Und davon gibt es 9 weniger als in der Stichprobe - ich werde versuchen, nur diese zu nehmen und auf der gesamten Stichprobe (auf allen Zuglinien) zu trainieren.
Splits werden nur bis zum Quantum gemacht. Alles innerhalb des Quants wird als gleichwertig betrachtet und nicht weiter aufgeteilt. Ich verstehe nicht, warum Sie etwas in Quantum suchen, sein Hauptzweck ist es, Berechnungen zu beschleunigen (der sekundäre Zweck ist es, das Modell zu laden/verallgemeinern, so dass es keine weitere Aufteilung gibt, aber Sie können einfach die Tiefe der Float-Daten begrenzen) Ich benutze es nicht, ich mache nur Modelle auf Float-Daten. Ich habe die Quantisierung für 65000 Teile durchgeführt - das Ergebnis ist absolut dasselbe wie das Modell ohne Quantisierung.
Mir persönlich ist aufgefallen, dass die Prädiktoren, zumindest meine, keine fließenden Übergänge der Wahrscheinlichkeit haben, sondern dass dies abrupt geschieht und in die entgegengesetzte Abweichung übergeht, d. h. es war +5 und wurde sofort zu -5.
Außerdem ist mir etwas Ähnliches aufgefallen. Erhöht man die Tiefe um 1, ändert sich die Rentabilität drastisch, manchmal in +, manchmal in -.
In der Tat, es wird eine - 0,5 :) Aber auf diese Weise wird es möglich sein, den Prädiktor in nützliche (potenziell nützliche Informationen enthaltende) Bereiche zu unterteilen.
Es wird einen Split geben, der die Daten in 2 Bereiche aufteilt - einer hat alle 0's, der andere alle 1's. Ich weiß nicht, was als Quanta bezeichnet wird. Ich denke, dass Quanta die Anzahl der Sektoren ist, die man nach der Quantisierung erhält. Vielleicht ist es auch die Anzahl der Splits, die Sie meinen.