Gibt es ein Muster in diesem Chaos? Lassen Sie uns versuchen, es zu finden! Maschinelles Lernen am Beispiel einer bestimmten Stichprobe. - Seite 25
Sie verpassen Handelsmöglichkeiten:
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Registrierung
Einloggen
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wenn Sie kein Benutzerkonto haben, registrieren Sie sich
Bei TP=SL sind es etwa 50%. Bei TP = 2*SL werden es 33% sein, usw.
Der durchschnittliche Gewinn aus einem Handel ist immer sehr gering. Etwa 0,00005. Aber es wird für Spread, Slippage, Swap ausgegeben, die im Aufschlag des Lehrers nicht berücksichtigt werden (der Spread wird berücksichtigt, aber das Minimum pro Bar, das reale wird höher sein).
Und das mit TP=SL=0,00400. D.h. mit einem Risiko von 400 bekommen wir einen Gewinn von 5 pts, d.h. den Vorteil von 1%.
Ich würde gerne mindestens 10 pts von der Bewegung von 50 pts nehmen, aber da sind alle Optionen Pflaume.
Aber das ist alles mit meinen Chips und Zielen. Vielleicht gibt es bessere Optionen.
Diese Strategie gibt 43% der profitablen Trades auf EURUSD von 2008 bis 2023, mit TP/SL-Verhältnis von 61,8, und 39% der profitablen Trades sind genug für Breakeven. Ich habe die Zahlen noch nicht überprüft, vielleicht liege ich irgendwo falsch, und dies sind natürlich ideale Bedingungen. Allerdings gibt es hier eine Lernperspektive, was bedeutet, dass Sie einen höheren Prozentsatz auf Kosten von MO herausziehen können.
Was die Prädiktoren angeht, haben Sie meine Prädiktoren aus meinem Artikel übernommen? Sie sind oft in den Modellen zu finden, die ich unter anderem habe.
Hinzugefügt: Ja, ich habe nicht berücksichtigt, dass es gewinnbringende Trades gibt, die nicht mit TP geschlossen werden, und es wird natürlich weniger Gewinn geben.Diese Strategie gibt 43% der profitablen Trades auf EURUSD von 2008 bis 2023, mit TP/SL-Verhältnis von 61,8 unter idealen Bedingungen, und 39% der profitablen Trades sind genug für Breakeven. Ich habe die Zahlen noch nicht überprüft, ich kann mich irgendwo irren, und dies sind natürlich ideale Bedingungen. Allerdings gibt es eine Lernperspektive hier, was bedeutet, dass Sie einen höheren Prozentsatz auf Kosten der MO herausziehen können.
Was die Prädiktoren anbelangt, so haben Sie diese aus meinem Artikel übernommen? Sie finden sich häufig in den Modellen, die ich unter anderem habe.
Ich bin mir nicht ganz sicher, was Ihre Strategie ist. Es sieht so aus, als ob Sie einmal am Tag ein Signal zum Einstieg erhalten. Ich denke, es ist wenig sinnvoll, über die statistische Signifikanz der Ergebnisse zu sprechen.
Ich habe Ihre 5000+ Prädiktoren auf Ihren Datensatz trainiert. Sie liefern nicht mehr als die gleichen 5 Punkte, daher denke ich, dass sie nicht besser sind als meine einfachen Preisdeltas und Zigzags, die ebenfalls 5 Punkte liefern.
Ich werde vorerst andere Ideen prüfen. Wenn sie nichts bringen, werde ich Ihre Prädiktoren ausprobieren, um mein eigenes Modell zu erstellen.
Ich verstehe nicht wirklich, was Ihre Strategie ist. Es sieht aus wie ein Signal zu geben, einmal pro Tag.
Die Strategie ist wie folgt:
Bei der Eröffnung des Tages berechnen wir den erwarteten Grenzbereich der Preisbewegung, zu diesem Zweck können wir ATR(3) am Ende des letzten Tages verwenden, ich verwende eine etwas andere Formel. Wir verschieben diesen Bereich vom Beginn der Eröffnung des aktuellen Tages (Bar) - wir betrachten ihn als 100%.
Bei Erreichen eines signifikanten Niveaus oberhalb/unterhalb der Eröffnung (ich habe bei 23,6 gestoppt, da es sich nach meinen Beobachtungen bei verschiedenen Instrumenten oft als solches herausstellt), eröffnen wir eine Position mit TP auf dem nächsten signifikanten Niveau (ich verwende 61,8) und setzen SL auf den Eröffnungskurs des Tages.
Wenn wir beim Take Profit geschlossen haben, steigen wir wieder ein, wenn ein Signal erscheint.
Es ist besser, am Ende des Tages (23:45 Uhr) zu schließen, wenn die Take-outs nicht funktioniert haben, aber eigentlich warte ich auf TP/SL.
Der anfängliche Aufschlag funktioniert wie folgt - wenn wir im Gewinn geschlossen haben, setzen wir 1, wenn wir im Verlust geschlossen haben -1.
Bei der Aufteilung der Probe, habe ich das Ziel Offset von 300 Pips, so dass, wenn der Gewinn weniger als 300 Pips ist, ist es Null.
Ich denke, dies ist sehr wenig, um über die statistische Signifikanz der Ergebnisse zu sprechen.
Ich habe die Daten von 2008. Ja, es gibt nicht viele Daten, aber es hängt davon ab, wie Sie es betrachten, denn wenn man bedenkt, dass das Niveau von 23,6 ist nicht zufällig und seine Kreuzung ist signifikant für den Markt, dann wird es wie ähnliche Ereignisse, die miteinander verglichen werden können, im Gegensatz zu der Situation bei der Erzeugung von Einträgen auf jeder Bar - es gibt viele ähnliche Ereignisse, die nur erschwert Lernen.
Ich denke also, dass es sinnvoll ist, auf diese Weise zu trainieren, aber die Ereignisse, die die Entscheidung der Marktteilnehmer beeinflussen, sollten bei den verschiedenen Strategien unterschiedlich sein. Und, weitere Handelssätze von Modellen.
Ich habe Ihre 5000+ Prädiktoren auf Ihren Datensatz trainiert. Sie liefern nicht mehr als die gleichen 5 Punkte, daher denke ich, dass sie nicht besser sind als meine einfachen Preisdeltas und Zigzags, die ebenfalls 5 Punkte liefern.
Ich werde vorerst andere Ideen prüfen. Wenn sie nichts bringen, werde ich Ihre Prädiktoren ausprobieren, um mein eigenes Modell zu erstellen.
Sprechen Sie von der ersten oder der zweiten Stichprobe? Wenn es die erste Stichprobe ist, dann hatte ich eine Erwartungsmatrix von etwa 30 Punkten für gute Varianten.
Ich kann versuchen, Ihre Stichprobe auf CatBoost zu trainieren, wenn Sie sie hochladen, natürlich.
So sieht die Strategie aus:
Bei der Eröffnung des Tages berechnen wir den erwarteten Grenzbereich der Preisbewegung, zu diesem Zweck können wir ATR(3) am Ende des letzten Tages verwenden, ich verwende eine etwas andere Formel. Wir verschieben diesen Bereich vom Beginn der Eröffnung des aktuellen Tages (Bar) - wir betrachten es als 100%.
Wenn wir ein signifikantes Niveau oberhalb/unterhalb der Eröffnung erreichen (ich habe bei 23,6 gestoppt, da es sich nach meinen Beobachtungen bei verschiedenen Instrumenten oft als solches herausstellt), eröffnen wir eine Position mit TP auf dem nächsten signifikanten Niveau (ich verwende 61,8) und setzen SL auf den Eröffnungskurs des Tages.
Wenn wir beim Take Profit geschlossen haben, steigen wir wieder ein, wenn ein Signal erscheint.
Es ist besser, am Ende des Tages (23:45 Uhr) zu schließen, wenn die Take-Outs nicht funktioniert haben, aber eigentlich warte ich jetzt auf TP/SL.
Der anfängliche Aufschlag funktioniert wie folgt - wenn wir im Gewinn geschlossen haben, setzen wir 1, wenn wir im Verlust geschlossen haben -1.
Bei der Aufteilung der Probe, habe ich das Ziel Offset von 300 Pips, so dass, wenn der Gewinn weniger als 300 Pips ist, ist es Null.
Ich habe Daten von 2008 genommen. Ja, es gibt nicht viele Daten, aber es hängt davon ab, wie man es betrachtet, denn wenn wir davon ausgehen, dass das Niveau von 23,6 nicht zufällig ist und seine Überschreitung ist signifikant für den Markt, dann sind dies ähnliche Ereignisse, die miteinander verglichen werden können.
Jetzt ist das Ziel mehr oder weniger klar.
Haben Sie eine Schätzung des Ergebnisses in Pips oder nur Gewinn/Verlust? Sieht nach Letzterem aus. Es ist besser, in Pips zu schätzen.
So dass das Modell, das 75% gibt, nicht in der Tat 50/50 funktioniert.
im Gegensatz zu der Situation, in der die Eingaben bei jedem Balken generiert werden - es gibt viele solcher Ereignisse, was das Lernen nur erschwert.
Ich möchte Ausdünnung hinzufügen - ähnliche Bars, wenn der Preis nicht durch 100 gegangen...1000 pts, dann überspringen.
Sprechen Sie über die erste oder die zweite Probe? Wenn Sie über die erste sprechen, dann hatte ich eine Erwartungsmatrix von etwa 30 Pips für gute Varianten.
Die zweite auf H1. Nun, die erste war nicht besser (aber ich habe sie weniger erforscht, ich habe z.B. keine Merkmale ausgewählt).
Ich kann versuchen, Ihr Beispiel auf CatBoost zu trainieren, wenn Sie es hochladen, natürlich.
Ich habe Hunderte von ihnen. Und ich mag keine von ihnen in den Handel zu setzen. Ich ändere TP oder SL oder etwas anderes - das ist eine neue Variante. Es hat also keinen Sinn.
Jetzt ist das Ziel mehr oder weniger klar.
Haben Sie eine Schätzung des Ergebnisses in Punkten oder nur Sieg/Niederlage? Sieht nach Letzterem aus. Es ist besser, in Punkten zu schätzen.
So dass ein 75%-Modell nicht wirklich 50/50 funktioniert.
Ich habe eine Bewertung in Geld :) Plus Ziel, wie es früher war. Das Ziel kann später verschoben werden, wenn Sie mehr Punkte wollen.
In der spezifischen Strategie ist jetzt alles Take Profit. Ich habe ein kalkuliertes Lot gemacht, in der Tat hat sich herausgestellt, dass der Spread das Verhältnis deutlich verschlechtert, aber es ist in Ordnung, aber es wird Stabilität ohne Emissionen von super profitablen Einträgen geben - das Risiko ist fast überall das gleiche. Wenn Sie dann die Pausen nutzen, können Sie das Ergebnis verbessern.
Ich würde gerne eine Ausdünnung hinzufügen - ähnliche Balken, wenn der Preis nicht um 100...1000 pts gegangen ist, dann überspringen.
Und dann auf jeder Bar zu bewerten, auch Modell zu übernehmen?
Die zweite auf H1. Nun, die erste war nicht besser, (aber ich recherchierte es weniger, ich habe nicht wählen, Chips zum Beispiel).
Ich habe Hunderte von ihnen. Und keiner von ihnen mag ich in den Handel zu setzen. Ich ändere TP oder SL oder etwas anderes - das ist eine neue Variante. Es hat also keinen Sinn.
Ich will damit sagen, dass, wenn es den gleichen Algorithmus für die Erstellung einer Stichprobe gibt, es möglich sein wird, Prädiktoren zu vergleichen.
Und dann zu schätzen, bei jeder Bar, gut das Modell zu verwenden?
Ja, wenn mindestens XX Pips vergangen sind, wie in der Ausbildung. Aber es wird Verzerrungen - nur die ersten Bars von 100 bis 120 (200-220, etc.), wenn bis und 999-979 (899-979) wird häufiger arbeiten.
Mein Punkt ist, dass, wenn es den gleichen Algorithmus zur Erstellung einer Stichprobe gibt, es möglich sein wird, Prädiktoren zu vergleichen.
Ich will nicht wirklich 5000+, es wird lange dauern, sie zu zählen. Aber als Suche nach signifikanten Prädiktoren kann es notwendig sein, sie zu überprüfen.
Guten Tag!
Ich habe einen Ansatz, der dieses Problem lösen kann, aber vorzugsweise sollten die Beispieldateien ohne Prädiktoren sein. D.h. 5000+ Prädiktoren werden nicht benötigt, nur der Bewegungsgraph selbst. Ob sie aus OHLC besteht oder eine Variable hat, ist nicht wichtig. Ich habe jedoch die vorhandene Methode an einer Variablen aus der Stichprobe ausprobiert, nämlich an Spalte 5584, die ich mit der Formel D(i)=D(i-1)+ Target_100_Buy in ein Diagramm umgewandelt habe. Für alle drei Dateien erhielt ich diese Diagramme:
1) train: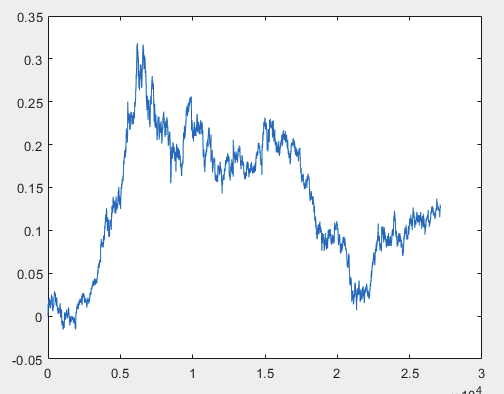
2)test: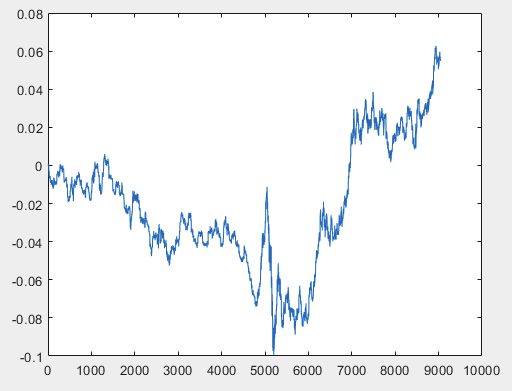
3)Prüfung: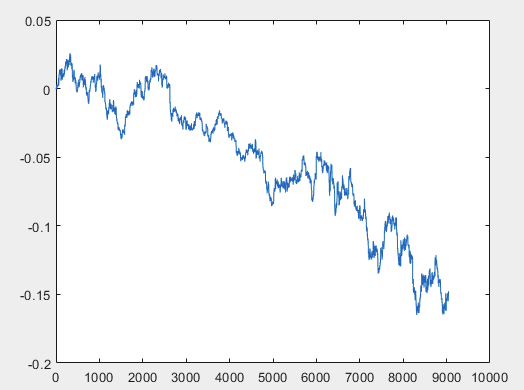
Ich weiß nicht, ob ich es richtig gemacht habe oder nicht, aber wenn der Topikstarter neue Stichproben ohne Prädiktoren macht, werde ich die Methode an neuen Daten testen und Ihnen über den Ansatz berichten.
Nun, und der tatsächliche Gewinn für jede der Proben nach dem Training des Komitees der neuronalen Netze (es gibt insgesamt 10 von ihnen). Der Gewinn wird in der Anzahl der Punkte ausgedrückt, mit Spread=0 und Kommission=0:
1) trainieren: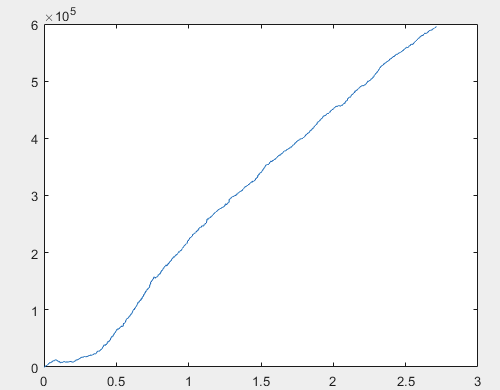
2) Testen: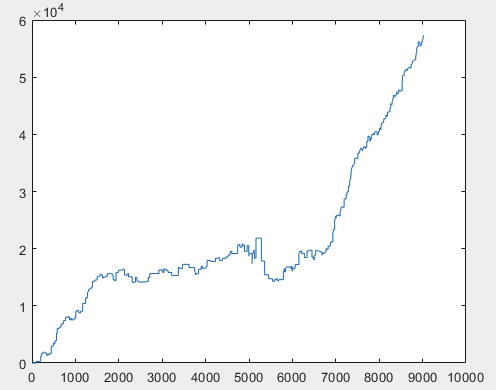
3) Prüfung: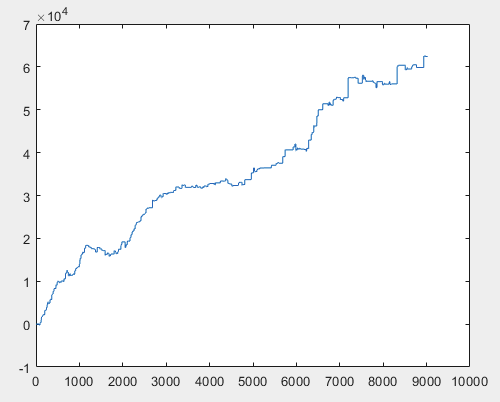
Ich denke, das Ergebnis von 60000+ Pips ist durchaus akzeptabel.
Ich schlage dem Topikstarter vor, neue Stichproben zu machen, und zwar nur von dem "chaotischsten" Signal.
Die Methode wird auf das neue Signal angewandt und die Ergebnisse werden gezeigt, sowie der Ansatz wird bis zu einem gewissen Grad beschrieben.
Mit freundlichen Grüßen, RomFil!
P.S. Die Zukunft ist nicht bekannt, aber eine Methode, sie zu kontrollieren, kann immer gefunden werden ... :)
Guten Tag!
Ich habe einen Ansatz, der dieses Problem lösen kann, aber vorzugsweise sollten die Beispieldateien ohne Prädiktoren sein. D.h. 5000+ Prädiktoren werden nicht benötigt, nur der Bewegungsgraph selbst. Ob es aus OHLC besteht oder eine Variable hat, ist nicht wichtig. Ich habe jedoch die bestehende Methode an einer Variablen aus der Stichprobe ausprobiert, nämlich an Spalte 5584, die ich mit der Formel D(i)=D(i-1)+ Target_100_Buy in ein Diagramm umgewandelt habe. Für alle drei Dateien sehen die Diagramme wie folgt aus:
Ich verstehe nicht, was Sie getan haben und warum eine neue Stichprobe erforderlich ist, wenn Ihr Ansatz mit reinen Preisen funktioniert.
Die Spalten aus der Liste unten sind das Ergebnis des eingetretenen Ereignisses, d.h. sie sollten nicht am Training teilnehmen. Höchstens 5582 - aber da ich denke, dass es leicht vorherzusagen ist, wird es vom Modell so wiedergegeben, wie es ist.
5581 Hilfskraft
5582 Hilfsmittel
5583 Etikett
5584 Hilfsmittel
5585 Hilfskraft
Ich verstehe nicht, was Sie getan haben und warum eine neue Stichprobe erforderlich ist, wenn Ihr Ansatz mit reinen Preisen funktioniert.
Die Spalten in der Liste unten sind das Ergebnis eines Ereignisses, das eingetreten ist, d.h. sie sollten nicht am Training teilnehmen. Höchstens 5582 - aber ich denke, das lässt sich leicht vorhersagen, so dass das Modell es wiederherstellen wird.
5581 Hilfskraft
5582 Hilfsmittel
5583 Bezeichnung
5584 Hilfsmittel
5585 Hilfskraft
"Was habe ich getan?":
Der Beispielzug ist etwa 1 GB groß. Es dauert ziemlich lange, ihn in den Arbeitsbereich zu laden. Ich habe einen i5-3570 mit 24 GB RAM und einer schnellen SSD und es dauert mehrere Minuten, bis Excel diese Datei öffnet. Deshalb habe ich beschlossen, dass sie gekürzt werden sollte. Ich war zu faul, um die Hochkommata für 5000+ Spalten herauszufinden. Ich nahm die Spalte 5584 5586 und wendete auf alle Zeilen ein Signal an, z. B. KAUFEN (ehrlich gesagt, weiß ich nicht mehr, welches, vielleicht VERKAUFEN). So bildete diese Spalte ein Diagramm gemäß der obigen Formel. D.h. der erste Schritt war Null, dann 0,00007, dann 0,00007-0,00002=0,00005, dann 0,00005+0,00007=0,00012, usw. D.h. ab Spalte 5584 5586 habe ich ein Bewegungsdiagramm ohne Bindung gebildet, sozusagen ein relatives Bewegungsdiagramm. Als wäre es ein Close-Chart, d.h. am Ende jedes Schrittes des Charts ändert sich der Preis des Assets um den entsprechenden Wert.
P.S. Habe bei der Säulennummer geschummelt ... Ich habe die letzte 5586 (ich habe sie gerade in Excel nachgeschlagen) mit dem SELL-Signal genommen.
"... warum eine neue Probe":
Um in gewissem Maße den Ansatz an seinem Beispiel zu zeigen und zu erzählen. Wenn Sie die Anzahl der Spalten nennen, in denen Sie OHLC oder nur Clause-Preise nehmen können, ist das ausreichend.
Zum Rest:
Die Daten aus den Beispieldateien werden überhaupt nicht verwendet. Auf der Grundlage der Spalten 5584 5586 aus jeder Datei wird ein Diagramm wie oben beschrieben erstellt. Und schon wird der Ansatz auf diese erhaltenen Graphen angewandt.
Nun, da der Topikstarter keine neuen Beispiele geben will, schlage ich jedem Interessierten vor, seine eigenen zu posten ... :)
Mit freundlichen Grüßen, RomFil!
Guten Tag!
Ich habe einen Ansatz, der dieses Problem lösen kann, aber vorzugsweise sollten die Beispieldateien ohne Prädiktoren sein. D.h. 5000+ Prädiktoren werden nicht benötigt, nur der Bewegungsgraph selbst. Ob sie aus OHLC besteht oder eine Variable hat, ist nicht wichtig. Ich habe jedoch die bestehende Methode an einer Variablen aus der Stichprobe ausprobiert, nämlich Spalte 5584, die ich mit der Formel D(i)=D(i-1)+ Target_100_Buy in ein Diagramm umgewandelt habe. Für alle drei Dateien sehen die Diagramme wie folgt aus:
Die Wiederholbarkeit der Zielfunktion wird trainiert? Wenn sie zum Beispiel 20 Mal erfolgreich war, wird sie dann auch 21 Mal erfolgreich sein?
Wie viele Werte geben Sie als Prädiktoren ein?
Hier sind die einfachsten Ziele für Kauf und Verkauf mit TP/SL=50 pts
M5 für etwa 5 Jahre.
Der Aufschlag gilt für jeden M5-Balken, d.h. höchstwahrscheinlich ist der Handel des letzten Signals (vor 5 Minuten) noch nicht abgeschlossen. Ich bin nicht sicher, ob es korrekt wäre, sie zu stapeln. Das Stapeln wäre für ein Ziel mit nur einem Handel zu einem bestimmten Zeitpunkt in Ordnung - selbst 100 zur gleichen Zeit können nicht über Nacht abgeschlossen werden.
P.S. - Ich habe sie nicht trainieren können. Sie scheitern immer an meinen Prädiktoren.