Optimierung von Algorithmen.
joo
Für den Anfang sollten Sie den Code zu bringen:
1. Kompilierbar.
2. Lesbare Form.
3. Kommentar.
Im Prinzip ist das Thema interessant und dringend.
joo
Für den Anfang sollten Sie den Code zu bringen:
1. Kompilierbar.
2. Lesbare Form.
3. Kommentar.
Gut.
Wir haben eine sortierte Reihe von reellen Zahlen. Sie müssen eine Zelle in der Matrix mit einer Wahrscheinlichkeit wählen, die der Größe des imaginären Roulettesektors entspricht.
Der Testsatz von Zahlen und ihre theoretische Wahrscheinlichkeit des Herausfallens werden in Excel berechnet und zum Vergleich mit den Ergebnissen des Algorithmus in der folgenden Abbildung dargestellt:
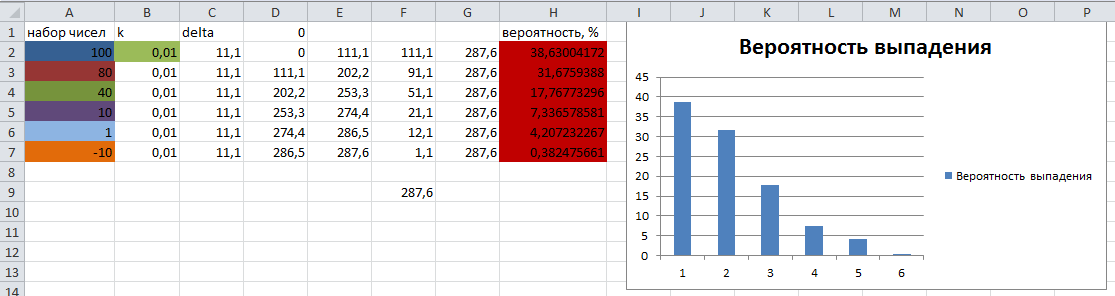
Das Ergebnis der Ausführung des Algorithmus:
2012.04.04 21:35:12 Roulette (EURUSD,H1) h0 38618465 38.618465
2012.04.04 21:35:12 Roulette (EURUSD,H1) h1 31685360 31.68536
2012.04.04 21:35:12 Roulette (EURUSD,H1) h3 7.334754 7.334754
2012.04.04 21:35:12 Roulette (EURUSD,H1) h4 4205492 4.205492
2012.04.04 21:35:12 Roulette (EURUSD,H1) h5 385095 0.385095
2012.04.04 21:35:12 Roulette (EURUSD,H1) 12028 ms - Ausführungszeit
Wie Sie sehen können, sind die Ergebnisse der Wahrscheinlichkeit, dass die "Kugel" auf dem entsprechenden Sektor herausfällt, fast identisch mit den theoretisch berechneten.
#property script_show_inputs //--- input parameters input int StartCount=100000000; // Границы соответствующих секторов рулетки double select1[]; // начало сектора double select2[]; // конец сектора //—————————————————————————————————————————————————————————————————————————————— void OnStart() { MathSrand((int)TimeLocal());// сброс генератора // массив с тестовым набором чисел double array[6]={100.0,80.0,40.0,10.0,1.0,-10.0}; ArrayResize(select1,6);ArrayInitialize(select1,0.0); ArrayResize(select2,6);ArrayInitialize(select2,0.0); // счетчики для подсчета выпадений соответствующего числа из тестового набора int h0=0,h1=0,h2=0,h3=0,h4=0,h5=0; // нажмём кнопочку секундомера int time_start=(int)GetTickCount(); // проведём серию испытаний for(int i=0;i<StartCount;i++) { switch(Roulette(array,6)) { case 0: h0++;break; case 1: h1++;break; case 2: h2++;break; case 3: h3++;break; case 4: h4++;break; default: h5++;break; } } Print((int)GetTickCount()-time_start," мс - Время исполнения"); Print("h5 ",h5, " ",h5*100.0/StartCount); Print("h4 ",h4, " ",h4*100.0/StartCount); Print("h3 ",h3, " ",h3*100.0/StartCount); Print("h1 ",h1, " ",h1*100.0/StartCount); Print("h0 ",h0, " ",h0*100.0/StartCount); Print("----------------"); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Рулетка. int Roulette(double &array[], int SizeOfPop) { int i=0,u=0; double p=0.0,start=0.0; double delta=(array[0]-array[SizeOfPop-1])*0.01-array[SizeOfPop-1]; //------------------------------------------------------------------------------ // зададим границы секторов for(i=0;i<SizeOfPop;i++) { select1[i]=start; select2[i]=start+MathAbs(array[i]+delta); start=select2[i]; } // бросим "шарик" p=RNDfromCI(select1[0],select2[SizeOfPop-1]); // посмотрим, на какой сектор упал "шарик" for(u=0;u<SizeOfPop;u++) if((select1[u]<=p && p<select2[u]) || p==select2[u]) break; //------------------------------------------------------------------------------ return(u); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Генератор случайных чисел из заданного интервала. double RNDfromCI(double min,double max) {return(min+((max-min)*MathRand()/32767.0));} //——————————————————————————————————————————————————————————————————————————————
GUT.
Wir haben eine sortierte Reihe von reellen Zahlen. Wir müssen eine Zelle in der Matrix mit einer Wahrscheinlichkeit auswählen, die der Größe des imaginären Roulettesektors entspricht.
Erläutern Sie das Prinzip der Einstellung der "Sektorbreite": Entspricht sie den Werten im Array? Oder wird sie separat eingestellt?
Dies ist die dunkelste Frage, der Rest ist kein Problem.
Zweite Frage: Was bedeutet die Zahl 0,01? Woher kommt sie?
Kurz gesagt: Sagen Sie mir, wo ich die korrekten Ausfallwahrscheinlichkeiten der Sektoren (Breite als Bruchteil des Umfangs) finden kann.
Sie können einfach die Größe jedes Sektors angeben, vorausgesetzt (die Vorgabe), dass die negative Größe in der Natur nicht vorkommt. Sogar im Kasino. ;)
Erläutern Sie das Prinzip der Einstellung der "Sektorbreite": Entspricht sie den Werten im Array? Oder wird sie separat eingestellt?
Die Breite der Sektoren darf nicht mit den Werten im Array übereinstimmen, da der Algorithmus sonst nicht für alle Zahlen funktioniert.
Entscheidend ist, wie weit die Zahlen voneinander entfernt sind. Je weiter alle Zahlen von der ersten Zahl entfernt sind, desto geringer ist die Wahrscheinlichkeit, dass sie herausfallen. Im Wesentlichen verschieben wir auf einer geraden Linie Bars proportional zum Abstand zwischen den Zahlen, um einen Faktor von 0,01 angepasst, so dass die letzte Zahl die Wahrscheinlichkeit des Herausfallens war nicht gleich 0 als die am weitesten von der ersten. Je höher der Koeffizient ist, desto gleicher sind die Sektoren. Excel-Datei im Anhang, experimentieren Sie damit.
MetaDriver:
1. Kurz gesagt: Sagen Sie mir, wo ich die korrekten Ausfallwahrscheinlichkeiten der Sektoren (Breite in Bruchteilen des Umfangs) finden kann.
2. Sie können einfach die Größe jedes Sektors bestimmen, wobei Sie (standardmäßig) davon ausgehen, dass negative Größen in der Natur nicht vorkommen, nicht einmal in Kasinos. ;)1. Die Berechnung der theoretischen Wahrscheinlichkeiten ist in Excel angegeben. Die erste Zahl ist die höchste Wahrscheinlichkeit, die letzte Zahl ist die niedrigste Wahrscheinlichkeit, aber nicht gleich 0.
2) Negative Sektorengrößen gibt es für keine Zahlenmenge, vorausgesetzt, die Menge ist absteigend sortiert - die erste Zahl ist die größte (funktioniert auch mit der größten Zahl in der Menge, aber einer negativen Zahl).
Die Breite der Sektoren darf nicht mit den Werten im Array übereinstimmen, sonst funktioniert der Algorithmus nicht für alle Zahlen.
hu: Es kommt darauf an, wie weit die Zahlen auseinander liegen. Je weiter alle Zahlen von der ersten Zahl entfernt sind, desto unwahrscheinlicher ist es, dass sie herausfallen. Im Wesentlichen verschieben wir auf einer geraden Linie Segmente proportional zu den Abständen zwischen den Zahlen, um einen Faktor von 0,01 angepasst, so dass die Wahrscheinlichkeit der letzten Zahl nicht zu fallen war 0 als die am weitesten von der ersten. Je höher der Koeffizient ist, desto gleicher sind die Sektoren. Die Excel-Datei ist beigefügt, experimentieren Sie damit.
1. Die Berechnung der theoretischen Wahrscheinlichkeiten ist in der Excel-Datei enthalten. Die erste Zahl ist die höchste Wahrscheinlichkeit, die letzte Zahl ist die niedrigste Wahrscheinlichkeit, aber nicht gleich 0.
2. Es gibt niemals negative Sektorengrößen für eine beliebige Menge von Zahlen, vorausgesetzt, die Menge ist absteigend sortiert - die erste Zahl ist die größte (es funktioniert auch mit der größten Zahl in der Menge, aber auch mit einer negativen Zahl).
Ihr Schema legt "aus heiterem Himmel" die Wahrscheinlichkeit für die kleinste Zahl(vmh) fest. Es gibt keine vernünftige Rechtfertigung.
// Denn "Rechtfertigung" ist ein bisschen schwierig. Das ist in Ordnung - es gibt nur N-1 Zwischenräume zwischen N Nägeln.
Es kommt also auf den "Koeffizienten" an, der ebenfalls aus der Box genommen wird. Warum 0,01 ? warum nicht 0,001 ?
Bevor Sie den Algorithmus anwenden, müssen Sie sich für die Berechnung der "Breite" aller Sektoren entscheiden.
zyu: Geben Sie die Formel zur Berechnung von "Abständen zwischen Zahlen" an. Welche Zahl ist die "erste"? Wie weit ist sie von sich selbst entfernt? Schicken Sie es nicht an Excel, das habe ich schon erlebt. Das ist auf ideologischer Ebene verwirrend. Woher kommt der Korrekturfaktor und warum ist er so hoch?
Das in Rot ist überhaupt nicht wahr. :)
wird es sehr schnell gehen:
int Selection() { return(RNDfromCI(1,SizeOfPop); }
Die Qualität des Algorithmus als Ganzes sollte nicht beeinträchtigt werden.
Und selbst wenn dies der Fall ist, geht diese Option zu Lasten der Qualität und nicht der Geschwindigkeit.
1. Ihr Schema legt "aus heiterem Himmel" die Wahrscheinlichkeit für die kleinste Zahl(vmh) fest. Es gibt keine vernünftige Rechtfertigung. Es(vmh) hängt also auch vom "Koeffizienten" ab. Warum 0,01 ? warum nicht 0,001 ?
2. Bevor Sie den Algorithmus anwenden, müssen Sie sich für die Berechnung der "Breite" aller Sektoren entscheiden.
3. zu: Geben Sie die Formel zur Berechnung von "Abständen zwischen Zahlen" an. Welche Zahl ist die "erste"? Wie weit ist es von Ihnen entfernt? Schicken Sie es nicht an Excel, das habe ich schon erlebt. Das ist auf ideologischer Ebene verwirrend. Woher kommt der Korrekturfaktor überhaupt und warum genau?
4. Das in Rot hervorgehobene ist überhaupt nicht wahr. :)
1. Ja, das ist nicht wahr. Ich mag diesen Koeffizienten. Wenn Ihnen ein anderer gefällt, nehme ich einen anderen - die Geschwindigkeit des Algorithmus ändert sich nicht.
2. Gewissheit erreicht wird.
3. Ok. Wir haben eine sortierte Reihe von Zahlen - array[], wobei die größte Zahl in array[0] steht, und einen numerischen Strahl mit dem Startpunkt 0,0 (Sie können jeden anderen Punkt nehmen - es wird sich nichts ändern) und in die positive Richtung gerichtet. Ordnen Sie die Segmente auf dem Strahl auf diese Weise an:
start0=0=0 end0=start0+|array[0]+delta|
start1=end0 end1=start1+|array[1]+delta|
start2=end1 end2=start2+|array[2]+delta|
......
start5=end4 end5=start5+|array[5]+delta|
Wo:
delta=(array[0]-array[5])*0.01-array[5];
Das ist die ganze Arithmetik. :)
Wenn wir nun einen "Ball" auf unseren markierten Strahl werfen, ist die Wahrscheinlichkeit, ein bestimmtes Segment zu treffen, proportional zur Länge dieses Segments.
4. Denn Sie haben das Falsche (nicht alles) hervorgehoben. Hervorzuheben ist:"Im Wesentlichen zeichnen wir auf der Zahlengeraden die Segmente proportional zu den Abständen zwischen den Zahlen auf, korrigiert um den Faktor 0,01, damit die letzte Zahl keine Wahrscheinlichkeit hat, 0 zu treffen".
wird es sehr schnell gehen:
int Selection() { return(RNDfromCI(1,SizeOfPop); }
Die Qualität des Algorithmus als Ganzes sollte nicht beeinträchtigt werden.
Und wenn sie auch nur geringfügig beeinträchtigt ist, wird sie auf Kosten der Geschwindigkeit die Qualität überholen.
:)
Wollen Sie damit sagen, dass Sie einfach ein Array-Element nach dem Zufallsprinzip auswählen? - Dies berücksichtigt nicht die Abstände zwischen den Array-Nummern, so dass Ihre Option nutzlos ist.
- www.mql5.com
:)
Wollen Sie damit sagen, dass Sie einfach ein Element des Arrays nach dem Zufallsprinzip auswählen? - Dabei wird der Abstand zwischen den Zahlen im Array nicht berücksichtigt, so dass Ihre Option wertlos ist.
Es ist nicht schwer, das zu überprüfen.
Ist es experimentell bestätigt, dass es ungeeignet ist?
Ist es experimentell bestätigt, dass es wertlos ist?
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Ich schlage vor, hier Probleme der optimalen Algorithmenlogik zu diskutieren.
Wenn jemand bezweifelt, dass sein Algorithmus eine optimale Logik in Bezug auf Geschwindigkeit (oder Klarheit) hat, dann ist er willkommen.
Außerdem heiße ich in diesem Thread alle willkommen, die ihre Algorithmen anwenden und anderen helfen wollen.
Ursprünglich hatte ich meine Frage in der Rubrik "Fragen eines Dummies" gepostet, aber ich habe festgestellt, dass sie dort nicht hingehört.
Bitte schlagen Sie also eine schnellere Variante des "Roulette"-Algorithmus als diese vor:
Natürlich können die Arrays aus der Funktion herausgenommen werden, so dass sie nicht jedes Mal deklariert und in der Größe angepasst werden müssen, aber ich brauche eine revolutionärere Lösung. :)