Diskussion zum Artikel "Neuronale Netzwerke leicht gemacht (Teil 13): Batch-Normalisierung"
Bei einem anderen Projekt habe ich einen Vergleich zwischen der schnellen und der klassischen Fehlerberechnung in einer Schleife von 20-50 Zeilen durchgeführt: (Ich nehme an, dass Sie die gleichen kumulierten Fehler auch bei 50 Tausend Zeilen haben, bei Millionen von Zeilen sogar noch mehr)
.
Ich habe zunächst 50 Datenzeilen mit dem Auge verglichen. Sie weisen keine Fehler auf.
Aber die Fehler werden als kumulative Summe betrachtet. Bei jeder Berechnung können wir 1e-14 ... 1e-17 Fehler haben. Wenn man diese Fehler viele Male addiert, kann der Gesamtfehler 1e-5 überschreiten.
Ich habe einen genaueren Vergleich durchgeführt. Ich habe 50.000 Zeilen genommen und dann die Fehler verglichen, wenn der Unterschied groß ist, habe ich sie auf dem Bildschirm angezeigt. Was ich erhielt (siehe unten).
Es gibt einzelne kumulierte Fehler über 1e-4 (d. h. Unterschiede in der 4. Dezimalstelle).
Die Geschwindigkeit ist also sicherlich gut, aber wenn es sich nicht um 50 Tausend, sondern um 500 Millionen Strings handelt? Ich befürchte, dass die Ergebnisse absolut nicht mit der exakten Berechnung in der Schleife vergleichbar sein werden.
fast_error= 9.583545e+02 true_error= 9.582576e+02
fast_error= 9.204969e+02 true_error= 9.204000e+02
fast_error= 8.814563e+02 true_error= 8.813594e+02
fast_error= 8.411763e+02 true_error= 8.410794e+02
fast_error= 7.995969e+02 true_error= 7.995000e+02
fast_error= 7.566543e+02 true_error= 7.565574e+02
fast_error= 7.246969e+02 true_error= 7.246000e+02
fast_error= 6.916562e+02 true_error= 6.915593e+02
fast_error= 6.574762e+02 true_error= 6.573793e+02
fast_error= 6.220969e+02 true_error= 6.220000e+02
fast_error= 5.854540e+02 true_error= 5.853571e+02
fast_error= 5.588969e+02 true_error= 5.588000e+02
fast_error= 5.313562e+02 true_error= 5.312593e+02
fast_error= 5.027762e+02 true_error= 5.026792e+02
fast_error= 4.730969e+02 true_error= 4.730000e+02
fast_error= 4.422538e+02 true_error= 4.421569e+02
fast_error= 4.205969e+02 true_error= 4.205000e+02
fast_error= 3.980561e+02 true_error= 3.979592e+02
fast_error= 3.745761e+02 true_error= 3.744792e+02
fast_error= 3.500969e+02 true_error= 3.500000e+02
fast_error= 3.245534e+02 true_error= 3.244565e+02
fast_error= 3.072969e+02 true_error= 3.072000e+02
fast_error= 2.892560e+02 true_error= 2.891591e+02
fast_error= 2.703760e+02 true_error= 2.702791e+02
fast_error= 2.505969e+02 true_error= 2.505000e+02
fast_error= 2.298530e+02 true_error= 2.297561e+02
fast_error= 2.164969e+02 true_error= 2.164000e+02
fast_error= 2.024559e+02 true_error= 2.023590e+02
fast_error= 1.876759e+02 true_error= 1.875789e+02
fast_error= 1.720969e+02 true_error= 1.720000e+02
fast_error= 1.556525e+02 true_error= 1.555556e+02
fast_error= 1.456969e+02 true_error= 1.456000e+02
fast_error= 1.351557e+02 true_error= 1.350588e+02
fast_error= 1.239757e+02 true_error= 1.238788e+02
fast_error= 1.120969e+02 true_error= 1.120000e+02
fast_error= 9.945174e+01 true_error= 9.935484e+01
fast_error= 9.239691e+01 true_error= 9.230000e+01
fast_error= 8.48555553e+01 true_error= 8.475862e+01
fast_error= 7.677548e+01 true_error= 7.667857e+01
fast_error= 6.809691e+01 true_error= 6.800000e+01
fast_error= 5.875075e+01 true_error= 5.865385e+01
fast_error= 5.409691e+01 true_error= 5.400000e+01
fast_error= 4.905524e+01 true_error= 4.895833e+01
fast_error= 4.357517e+01 true_error= 4.347826e+01
fast_error= 3.759691e+01 true_error= 3.750000e+01
fast_error= 3.104929e+01 true_error= 3.095238e+01
fast_error= 2.829691e+01 true_error= 2.820000e+01
fast_error= 2.525480e+01 true_error= 2.515789e+01
fast_error= 2.187468e+01 true_error= 2.17777878e+01
fast_error= 1.809691e+01 true_error= 1.800000e+01
fast_error= 1.384691e+01 true_error= 1.375000e+01
fast_error= 1.249691e+01 true_error= 1.240000e+01
fast_error= 1.095405e+01 true_error= 1.085714e+01
fast_error= 9.173829e+00 true_error= 9.076923e+00
fast_error= 7.096906e+00 true_error= 7.000000e+00
fast_error= 4.642360e+00 true_error= 4.545455e+00
fast_error= 4.196906e+00 true_error= 4.100000e+00
fast_error= 3.652461e+00 true_error= 3.555556e+00
fast_error= 2.971906e+00 true_error= 2.875000e+00
fast_error= 2.096906e+00 true_error= 2.0000000000e+00
fast_error= 9.302390e-01 true_error= 8.33333333e-01
fast_error= 8.96909057e-01 true_error= 8.000000e-01
fast_error= 8.469057e-01 true_error= 7.500000e-01
fast_error= 7.635724e-01 true_error= 6.66666667e-01
fast_error= 5.969057e-01 true_error= 5.000000e-01
fast_error= 4.546077e+00 true_error= 4.545455e+00
fast_error= 4.100623e+00 true_error= 4.100000e+00
fast_error= 3.556178e+00 true_error= 3.555556e+00
fast_error= 2.875623e+00 true_error= 2.875000e+00
fast_error= 2.000623e+00 true_error= 2.000000e+00
fast_error= 8.339561e-01 true_error= 8.333333e-01
fast_error= 8.006228e-01 true_error= 8.000000e-01
fast_error= 7.506228e-01 true_error= 7.500000e-01
fast_error= 6.672894e-01 true_error= 6.66666667e-01
fast_error= 5.006228e-01 true_error= 5.000000e-01
Was ist das Problem?
Während des Trainings stürzt das Terminal ab und gibt eine Fehlermeldung aus, nicht immer, es ist wie eine Art Poltergeist.
N 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
MP 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Fehlercode=4003
CD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OnInit - 153 -> Fehler beim Lesen EURUSD_PERIOD_H1_ 20AttentionMLMH_d.nnw prev Net 5015
RD 0 22:58:20.933 Core 1 2021.02.01 00:00:00 program string is NULL or empty
QN 0 22:58:20.933 Core 1 2021.02.01 00:00:00 OpenCL program create failed. Error code=4003
IO 0 22:58:20.933 Core 1 final balance 10000.00 USD
LE 2 22:58:20.933 Core 1 2021.02.19 23:54:59 invalid pointer access in 'NeuroNet.mqh' (2271,16)
MS 2 22:58:20.933 Core 1 OnDeinit kritischer Fehler
NG 0 22:58:20.933 Core 1 EURUSD,H1: 863757 Ticks, 360 Bars erzeugt. Umgebung synchronisiert um 0:00:00.018. Test bestanden in 0:00:00.256.
QD 0 22:58:20.933 Core 1 EURUSD,H1: Gesamtzeit von der Anmeldung bis zum Testende 0:00:00.274 (einschließlich 0:00:00.018 für die Synchronisierung der Verlaufsdaten)
LQ 0 22:58:20.933 Core 1 321 Mb Speicher verwendet, einschließlich 0.47 Mb History-Daten, 64 Mb Tick-Daten
JF 0 22:58:20.933 Core 1 Log-Datei "C:\Users\Buruy\AppData\Roaming\MetaQuotes\Tester\36A64B8C79A6163D85E6173B54096685\Agent-127.0.0.0.1-3000\logs\20210410.log" geschrieben
PP 0 22:58:20.939 Core 1 Verbindung geschlossen
Ich danke Ihnen im Voraus für Ihre Hilfe!!!
Dmitry hallo! während ein paar Monate beobachte ich eine starke Diskrepanz zwischen der OOS laufen und die endgültige Arbeit auf dem gleichen Intervall, aber bereits ein Expert Advisor. Alle Signale sind einheitlich (ich lade in eine Datei für jeden Bar alle Signale und vergleichen) Das Netzwerk hat natürlich alle die gleichen Einstellungen. Es besteht der Verdacht, dass der Prozess des Speicherns und Einlesens des Trainings nicht richtig funktioniert. In der NeuroNet.mph Datei ist für jedes Netzwerk eine individuelle Art der Speicherung des Trainings konfiguriert
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
usw.
und Speichern wird verwendet
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Können Sie bitte den Unterschied erklären, und ist es möglich, die gespeicherten Daten mit dem Training aus dem Speicher nach einer Epoche abzugleichen?
Ausgangssignaldaten TempData und ausgehende Neuronen ResultData zum Zeitpunkt des Trainings
und separat zum Zeitpunkt des Testens. Ich habe beide Dateien mit dem Programm WinMerge verglichen.
{kind=link}
Dmitry hallo! während ein paar Monate beobachte ich eine starke Diskrepanz zwischen der OOS laufen und die endgültige Arbeit auf dem gleichen Intervall, aber bereits ein Expert Advisor. Alle Signale sind einheitlich (ich lade in eine Datei für jeden Bar alle Signale und vergleichen) Das Netzwerk hat natürlich alle die gleichen Einstellungen. Es besteht der Verdacht, dass der Prozess des Speicherns und Einlesens des Trainings nicht richtig funktioniert. In der NeuroNet.mph Datei ist für jedes Netzwerk eine individuelle Art der Speicherung des Trainings konfiguriert
bool CNeuronProof::Save(const int file_handle)
bool CNeuronBase::Save(int file_handle)
bool CNeuronConv::Save(const int file_handle)
bool CNeuronLSTM::Save(const int file_handle)
bool CNeuronBaseOCL::Save(const int file_handle)
bool CNeuronAttentionOCL::Save(const int file_handle)
usw.
und Speichern wird verwendet
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true)
Können Sie bitte den Unterschied erklären, und ist es möglich, die gespeicherten Daten mit dem Training aus dem Speicher nach einer Epoche abzugleichen?
Ausgangssignaldaten TempData und ausgehende Neuronen ResultData zum Zeitpunkt des Trainings
und separat zum Zeitpunkt des Testens. Ich habe beide Dateien mit dem Programm WinMerge verglichen.
Guten Tag, Dmitry.
Schauen wir uns die Methode CNet::Save(...) an. Nach der Aufzeichnung der Variablen, die den Trainingszustand des Netzes charakterisieren, wird die Save-Methode des Arrays der neuronalen Schichten (CArrayLayer geerbt von CArrayObj) aufgerufen
bool CNet::Save(string file_name,double error,double undefine,double forecast,datetime time,bool common=true) { if(MQLInfoInteger(MQL_OPTIMIZATION) || MQLInfoInteger(MQL_TESTER) || MQLInfoInteger(MQL_FORWARD) || MQLInfoInteger(MQL_OPTIMIZATION)) return true; if(file_name==NULL) return false; //--- int handle=FileOpen(file_name,(common ? FILE_COMMON : 0)|FILE_BIN|FILE_WRITE); if(handle==INVALID_HANDLE) return false; //--- if(FileWriteDouble(handle,error)<=0 || FileWriteDouble(handle,undefine)<=0 || FileWriteDouble(handle,forecast)<=0 || FileWriteLong(handle,(long)time)<=0) { FileClose(handle); return false; } bool result=layers.Save(handle); FileFlush(handle); FileClose(handle); //--- return result; }
Die Klasse CArrayLayer hat keine Save-Methode, daher wird die Methode der Elternklasse CArrayObj::Save(const int file_handle) aufgerufen . Der Körper dieser Methode enthält eine Schleife, um alle verschachtelten Objekte aufzuzählen und die Save-Methode für jedes Objekt aufzurufen.
//+------------------------------------------------------------------+ //| Array in Datei schreiben| //+------------------------------------------------------------------+ bool CArrayObj::Save(const int file_handle) { int i=0; //--- prüfen if(!CArray::Save(file_handle)) return(false); //--- Array-Länge schreiben if(FileWriteInteger(file_handle,m_data_total,INT_VALUE)!=INT_VALUE) return(false); //--- Array schreiben for(i=0;i<m_data_total;i++) if(m_data[i].Save(file_handle)!=true) break; //--- Ergebnis return(i==m_data_total); }
Mit anderen Worten, hier wird das Prinzip einer verschachtelten Puppe verwendet: Wir rufen die Save-Methode für das oberste Objekt auf, und innerhalb der Methode werden alle verschachtelten Objekte durchsucht und die gleichnamige Methode für jedes Objekt aufgerufen.
Das Laden von Daten aus einer Datei wird auf ähnliche Weise organisiert.
Zu den unterschiedlichen Auswertungen beim Training und im Betrieb. Ich weiß nicht, wie Ihr neuronales Netz im Betriebsmodus organisiert ist, aber im Trainingsmodus ändern sich die Parameter des neuronalen Netzes ständig. Dementsprechend werden die gleichen Eingabedaten unterschiedliche Ergebnisse liefern.
Mit freundlichen Grüßen,
Dmitry.
P.S. Sie können die Korrektheit des Speicherns und Lesens von Daten überprüfen, indem Sie ein kleines Testprogramm erstellen, in dem Sie das neuronale Netz aus einer Datei lesen und es sofort in einer neuen Datei speichern können. Vergleichen Sie dann die beiden Dateien. Wenn Sie Unstimmigkeiten feststellen, schreiben Sie mir und ich werde das überprüfen.
Guten Tag, Dmitry.
Schauen wir uns die Methode CNet::Save(...) an. Nach der Aufzeichnung der Variablen, die den Trainingszustand des Netzes charakterisieren, wird die Methode Save des Arrays der neuronalen Schichten (CArrayLayer geerbt von CArrayObj) aufgerufen
Die Klasse CArrayLayer hat keine Save-Methode, daher wird die Methode der Elternklasse CArrayObj::Save(const int file_handle) aufgerufen . Der Körper dieser Methode enthält eine Schleife, um alle verschachtelten Objekte aufzuzählen und die Save-Methode für jedes Objekt aufzurufen.
Mit anderen Worten, hier wird das Prinzip einer Schachtelpuppe verwendet: Wir rufen die Save-Methode für das oberste Objekt auf, und innerhalb der Methode werden alle verschachtelten Objekte durchsucht und die gleichnamige Methode für jedes Objekt aufgerufen.
Das Laden von Daten aus einer Datei wird auf ähnliche Weise organisiert.
Bezüglich der unterschiedlichen Auswertungen beim Training und im Betrieb. Ich weiß nicht, wie Ihr neuronales Netz im Betriebsmodus organisiert ist, aber im Trainingsmodus ändern sich die Parameter des neuronalen Netzes ständig. Dementsprechend werden die gleichen Eingabedaten unterschiedliche Ergebnisse liefern.
Mit freundlichen Grüßen,
Dmitry.
P.S. Sie können die Korrektheit des Speicherns und Lesens von Daten überprüfen, indem Sie ein kleines Testprogramm erstellen, in dem Sie das neuronale Netz aus einer Datei lesen und es sofort in einer neuen Datei speichern können. Vergleichen Sie dann die beiden Dateien. Wenn Sie Unstimmigkeiten feststellen, schreiben Sie mir und ich werde das überprüfen.
Angenommen, ich werde versuchen, auf folgende Weise zu prüfen. Beim ersten Takt werde ich TempData (Signale) und OUTPUT Neurons in der Datei speichern. Zuerst ohne Laden der Datei, aber mit Training, dann mit Laden des Trainings aus dem gleichen ersten Takt, aber ohne Training im Prozess. nur ein Takt in beiden Fällen und vergleichen. Ich werde zurückschreiben.
p / s / da in den Prozess der Ausbildung wirklich lernen neuronka auf jedem bar, in den Prozess der Tester implementiert den gleichen Prozess, aber mit einem minus N bars.The Auswirkungen sollten nicht signifikant sein. Aber ich stimme zu, es sollte sein.
Lieber Dmitry!
Im Laufe der langen Arbeit mit Hilfe Ihrer Bibliothek ist es mir gelungen, einen Trading Advisor mit einem guten Ergebnis von 11% Drawdown zu fast 100% Gewinn für 5 Jahre EURUSD zu erstellen.
Alpari:
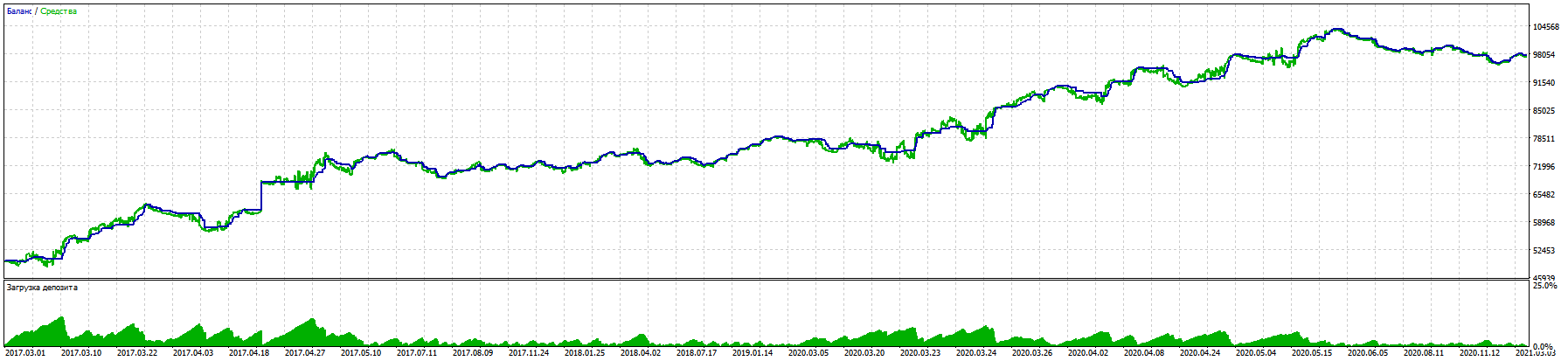
Die Tests auf einem realen Konto folgen der gleichen Logik.
Es ist bemerkenswert, dass sogar auf BKS-Futures RURUSD gibt noch bessere Ergebnisse mit den gleichen Eingaben. (Ich habe noch nicht mit anderen Paaren getestet).
Der entscheidende Sieg war das Testen des blinden Handels (Training nur für die vergangenen Perioden) und des obligatorischen Stoploss ohne Martingale und andere Tricks, mit Ausnahme des Rechts, je nach Signal mehrere Trades in jede Richtung zu eröffnen.
Natürlich musste ich viel aus den fünfwöchigen Kursen an der WSE und der Stanford University sowie aus vielen Artikeln über neuronale Netze lernen und ergänzen, vor allem um zu verstehen, was man lehren muss, was man lehren muss und wie man lehren muss.
Ich danke Ihnen sehr!
Bitte hören Sie nicht auf und entwickeln Sie die Bibliothek weiter.
Was ich Sie bitten möchte, zu bedenken
1. Immer noch über die Erhaltung der Ausbildung. So wie ich es bereits geschrieben habe, funktioniert es nicht. Man muss jedes Mal und "von der Pike auf" lernen, ohne den Handel auszuschalten. Das ist kein Problem, die Ausbildung ist schnell, aber es gibt ein zweites Problem.
2. Zu Beginn haben Sie die Randomisierungslogik so eingestellt, dass sie primäre Neuronen erzeugt. Dies führt zu bis zu drei Versionen des Trainings. (Ich denke, der entscheidende Punkt ist, dass das primäre Neuron anfangs positiv oder negativ ist).
Ja, auch damit kann man umgehen, indem man sozusagen ein neues Training erzwingt, und zwar von Grund auf, wenn man nicht zu den richtigen Metriken kommt.
Aber ich bin sicher, dass man mit einer bedingten Gewichtung von 0,01 für jedes Neuron beginnen kann. (Leider wird dadurch das Übertraining stärker ausgeprägt).
Oder man lernt immer noch, die beste Kopie der Ausbildung zu behalten, dann ist es Punkt 1.
Lieber Dimitri!
In den Prozess der langen Arbeit mit Hilfe Ihrer Bibliothek gelang es mir, ein Trading Advisor mit einem guten Ergebnis von 11% Drawdown zu fast 100% Gewinn für 5 Jahre EURUSD erstellen.
Alpari:
Die Tests auf einem echten Konto folgen der gleichen Logik.
Es ist bemerkenswert, dass RURUSD sogar bei BKS-Futures mit den gleichen Eingaben bessere Ergebnisse liefert. (Ich habe noch nicht auf andere Paare getestet).
Der entscheidende Sieg war das Testen des blinden Handels (Training nur auf vergangenen Perioden) und des obligatorischen Stoploss ohne Martingale und andere Tricks, mit Ausnahme des Rechts, je nach Signal mehrere Trades in jede Richtung zu eröffnen.
Natürlich musste ich vieles aus den fünfwöchigen Kursen an der WSE und der Stanford University sowie aus vielen Artikeln über neuronale Netze lernen und ergänzen, vor allem um zu verstehen, was man lehren muss, was man lehren muss und wie man lehren muss.
Ich danke Ihnen vielmals!
Bitte hören Sie nicht auf und entwickeln Sie die Bibliothek weiter.
Was ich Sie bitten möchte, zu bedenken
1. Immer noch über die Erhaltung der Ausbildung. Wie ich bereits geschrieben habe, funktioniert das nicht. Man muss jedes Mal und "von der Pike auf" lernen, ohne den Handel abzuschalten. Das ist kein Problem, die Ausbildung ist schnell, aber es gibt ein zweites Problem.
2. Zu Beginn haben Sie die Randomisierungslogik so eingestellt, dass sie primäre Neuronen erzeugt. Dies führt zu bis zu drei Versionen des Trainings. (Ich denke, der entscheidende Punkt ist, dass das primäre Neuron anfangs positiv oder negativ ist).
Ja, man kann sich auch dagegen wehren und sozusagen das Training von Grund auf neu erzwingen, wenn man die gewünschten Metriken nicht erreicht hat.
Aber ich bin sicher, dass Sie mit einer bedingten Gewichtung von 0,01 für jedes Neuron beginnen können. (Leider wird das Übertraining dann stärker ausgeprägt)
Oder lernen Sie noch, die beste Kopie der Ausbildung zu behalten, dann ist es Punkt 1.
Vielen Dank, Dimitri, für deine freundlichen Worte. Alle Gewichte mit einem konstanten Wert zu initiieren ist eine schlechte Praxis. In einem solchen Fall arbeiten alle Neuronen während des Lernens synchron als eine Einheit. Und das gesamte neuronale Netz degeneriert zu einem Neuron auf jeder Schicht.
....
Was ich Sie bitten möchte, zu bedenken
1. Immer noch über die Beibehaltung der Ausbildung. Wie ich schon geschrieben habe, funktioniert das nicht. Man muss jedes Mal und "von der Pike auf" lernen, ohne den Handel abzuschalten. Das ist kein Problem, die Ausbildung ist schnell, aber es gibt ein zweites Problem.
2. Zu Beginn haben Sie die Randomisierungslogik so eingestellt, dass sie primäre Neuronen erzeugt. Dies führt zu bis zu drei Versionen des Trainings. (Ich denke, der entscheidende Punkt ist, dass das primäre Neuron anfangs positiv oder negativ ist).
Ja, man kann auch dagegen vorgehen und sozusagen ein neues Training von Grund auf erzwingen, wenn man die gewünschten Metriken nicht erreicht hat.
Aber ich bin sicher, dass Sie mit einer bedingten Gewichtung von 0,01 für jedes Neuron beginnen können. (Leider wird das Übertraining dadurch stärker ausgeprägt)
Oder lernen Sie noch, die beste Kopie der Ausbildung zu behalten, dann ist es Punkt 1.
Dimitri, ich habe das so getestet, wie der Autor es dir empfohlen hat.
1. Trainieren Sie mehrere Epochen, nach jeder Epoche wird die Netzdatei gespeichert.
2. Aus dem Graphen löschen. Erneutes Ausführen mit aktiviertem Parameter testSaveLoad - nach dem Lesen des zuvor trainierten Netzes schreibt der Expert Advisor es erneut, wiederholt den Zyklus Lesen-Schreiben und entlädt es wieder, und wir erhalten drei Dateien, zusätzlich zum ursprünglichen Netz mit den Präfixen _check und _check2.
3. Wir vergleichen die drei Dateien, um a) durch Testen das Programmieren zu lernen und b) nach Fehlern in uns selbst zu suchen.

Danke Alexej, ich habe die Ergebnisse hier nicht veröffentlicht.
Es stellte sich heraus, dass das Problem woanders lag.
Der Speicher-/Ladevorgang funktioniert.
Die Lösung lag in der Zeile für die Erstellung von Neuronennetzelementen mit Randomize.
bool CArrayCon::CreateElement(int index) { if(index<0 || index>=m_data_max) return false; //--- xor128; double weigh=(double)rnd_w/UINT_MAX-0.5; m_data[index]=new CConnection(weigh); if(!CheckPointer(m_data[index])!=POINTER_INVALID) return false; //--- return (true); }
Ich habe sie durch eine stabilere Funktion zum Erstellen von Neuronen ersetzt, und es ist wichtig, eine gleiche Anzahl positiver und negativer Neuronen zu erstellen, damit das Netzwerk nicht zu Verkäufen oder Käufen neigt.
double weigh=(double)MathMod(index,0)?sin(index):sin(-index);
Dasselbe habe ich vorsichtshalber mit der Funktion zur Erstellung der Anfangsgewichte gemacht.
double CNeuronBaseOCL::GenerateWeight(void) { xor128; double result=(double)rnd_w/UINT_MAX-0.5; //--- return result; } //+----
Jetzt liefert der Backtest das gleiche Ergebnis, wenn das trainierte Netzwerk nach dem Laden der Trainingsdatei getestet wird.
Die Eingaben sind eine Einheit pro Sekunde.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Neuronale Netzwerke leicht gemacht (Teil 13): Batch-Normalisierung :
Im vorigen Artikel haben wir begonnen, Methoden zur Verbesserung der Trainingsqualität neuronaler Netze zu besprechen. In diesem Artikel setzen wir dieses Thema fort und betrachten einen weiteren Ansatz — die Batch-Normalisierung.
In der Anwendungspraxis von neuronalen Netzwerken werden verschiedene Ansätze zur Normalisierung von Daten verwendet. Sie zielen jedoch alle darauf ab, die Daten der Trainingsstichprobe und die Ausgabe der versteckten Schichten des neuronalen Netzes innerhalb eines bestimmten Bereichs und mit bestimmten statistischen Merkmalen der Stichprobe, wie z. B. Varianz und Median, zu halten. Dies ist wichtig, weil die Neuronen des Netzes lineare Transformationen verwenden, die im Laufe des Trainings die Stichprobe in Richtung des Antigradienten verschieben.
Betrachten Sie ein vollständig verbundenes Perzeptron mit zwei versteckten Schichten. Während eines Vorwärtsdurchlaufs (feed-forward) erzeugt jede Schicht einen bestimmten Datensatz, der als Trainingsmuster für die nächste Schicht dient. Das Ergebnis der Ausgabeschicht wird mit den Referenzdaten verglichen. Dann wird während des Rückwärtsdurchlaufs (feed-backward) der Fehlergradient von der Ausgabeschicht durch die versteckten Schichten in Richtung der Ausgangsdaten propagiert. Nachdem wir an jedem Neuron einen Fehlergradienten erhalten haben, aktualisieren wir die Gewichtskoeffizienten und passen das neuronale Netz an die Trainingsmuster des letzten Vorwärtsdurchlaufs an. Hier entsteht ein Konflikt: die zweite versteckte Schicht (H2 in der Abbildung unten) wird an die Datenprobe am Ausgang der ersten versteckten Schicht (H1 in der Abbildung) angepasst, während wir durch die Änderung der Parameter der ersten versteckten Schicht bereits das Datenfeld geändert haben. Mit anderen Worten, wir passen die zweite versteckte Schicht an die Datenprobe an, die nicht mehr existiert. Ähnlich verhält es sich mit der Ausgabeschicht, die sich an die bereits geänderte Ausgabe der zweiten versteckten Schicht anpasst. Die Fehlerskala wird noch größer, wenn wir die Verzerrung zwischen der ersten und der zweiten versteckten Schicht berücksichtigen. Je tiefer das neuronale Netz ist, desto stärker ist der Effekt. Dieses Phänomen wird als interne Kovariatenverschiebung bezeichnet.
Klassische neuronale Netze lösen dieses Problem teilweise, indem sie die Lernrate reduzieren. Geringfügige Änderungen in den Gewichten haben keine signifikanten Änderungen in der Probenverteilung am Ausgang der neuronalen Schicht zur Folge. Aber dieser Ansatz löst nicht das Skalierungsproblem, das mit zunehmender Anzahl von Schichten des neuronalen Netzes auftritt, und er verringert auch die Lerngeschwindigkeit. Ein weiteres Problem einer kleinen Lernrate ist, dass der Prozess an lokalen Minima hängen bleiben kann, was wir bereits in Artikel 6 diskutiert haben.
Autor: Dmitriy Gizlyk