市场现象 - 页 33 1...262728293031323334353637383940...75 新评论 Vladimir Paukas 2011.07.20 15:39 #321 joo: 不是说这是错的。对,就像 "买得便宜,卖得好 "的说法一样正确。重要的不仅仅是正确性,还有形式上的可塑性。构建聪明的哲学近似市场的构架是没有意义的,如果它们(构架)就像山羊的牛奶。 你认为吃亏后的时间差是否难以正式确定?还是别的什么? khorosh 2011.07.20 15:54 #322 paukas: 你认为接受损失后的时间间隔是否难以正式确定?或者有什么不同? 是的,你可以,当然,没有问题。你也可以在波动性低的时候禁止交易。 Alexey Burnakov 2011.07.21 08:05 #323 gpwr: 谢谢。我将在闲暇时思考SOM。 链接中的文章对时间序列 分割方法进行了概述。他们都做了差不多的事情。并不是说SOM是最好的外汇方法,但也不是最差的,这是一个事实 )) http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf Сергей 2011.10.21 11:07 #324 我的同事,不幸的是,不允许我给更多的时间来做交易,但我找到了一些时间,决定问一下(为了我自己的利益,所以我不会忘记它:o,所以我以后会回来,当我有更多的空闲时间时) 现象的本质。 让我提醒你这个现象的本质。这是在分析 "长尾 "对未来价格偏离的影响时发现的。如果我们对长尾进行分类,看看没有长尾的时间序列,我们可以观察到一些奇怪的现象,几乎每个符号都是独一无二的。该现象的本质是一种非常具体的分类,以某种方式基于 "神经 "方法。事实上,这种分类法将原始数据,即报价过程本身 "分解 "为两个子过程,习惯上被称为"α"和"β"。一般来说,最初的过程可以被分解成更多的子过程。 具有随机结构的系统 这种现象非常适用于具有随机结构的系统。该模型本身看起来会非常简单。让我们来看看一个例子。最初的欧元兑美元 系列 M15(我们需要一个长的样本,和尽可能小的框架),从一些 "现在"。 步骤1:分类 进行分类,得到两个过程"α"和"β"。定义主流程的参数(该流程涉及报价的最终 "组合")。 第2步 识别 对于每个子过程,都定义了一个基于Volterry网络的模型。 哦,识别它们是多么的痛苦。 步骤3 子过程预测 对每个过程的100个计数进行预测(15分钟,即刚刚超过一天)。 第4步:模拟建模 建立一个模拟模型,它将产生未来实施的x.o.数量。该系统的方案很简单。 三个随机化:每个模型和过程过渡条件的误差。下面是变现本身(从零开始)。 第5步:交易方案。 对这些变现进行了偏差分析。这可以通过不同的方式进行。从视觉上我们可以看到,大量的轨迹被转移了。让我们看一下事实。 <> 初步测试 随机进行了大约70次 "测量"(需要很长的时间来计算)。大约70%的系统检测到了正确的偏差,所以它还没有说什么,但我希望在几个月内回到这个轨道上,尽管我还没有完成主要项目的工作 :o(。 Илья 2011.10.21 16:59 #325 也许不完全正确:用什么原则来分类,并实际分解成什么过程的目的? Сергей 2011.10.24 08:07 #326 对sayfuji Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается? 不,一切都很正确。这是本主题中几十页的讨论主题之一。所有我认为必要的东西--我都写了。 不幸的是,我没有时间来进一步发展这个话题。此外,这种现象特别有趣,但不是很有希望。"长尾 "现象出现在长周期上,即轨迹有较大偏差的地方,但为此有必要对阿尔法和贝塔过程(以及其他过程)进行远距离预测。而这是不可能的。 没有这样的技术... :о( 对所有 同事们,事实证明,有些帖子我还没有回答。请原谅我,现在试图移动是没有意义的。 Artemka 2012.01.14 10:58 #327 Prohwessor Fransfort,请回答你用哪个程序进行研究。 还有......如果谁有俄文手册或程序的俄文版 http://originlab.com/ (OriginPro 8.5.1) Sceptic Philozoff 2012.01.14 15:04 #328 如果我没弄错的话,Matlab就是。 anonymous 2012.01.14 18:01 #329 Farnsworth:我们希望在研究 "胖尾巴 "的过程中,能够接触到更严肃的 "分形 "数学。这还需要一些时间,但现在我发布一项近乎科学的研究,给了我一些思考。 模型假设。有理由认为,有几个过程是坐在小床上的,这是我想找到的。主要的 "承载过程 "应该是某种增加/减少的趋势,它通过某种随机算法打断了另一个(或多个)过程。这个想法开始时很简单--去除那些理论上属于 "胖尾巴"(或其他一些子过程)的增量,看看会发生什么。首先,最简单的分类方法是 "过滤掉 "位于+/-LAMBDA内的所有东西。Open(n)-Open(n-1)增量,M15,EURUSD。从0.0001的增量到0.025,我通过LAMBDA,只留下那些属于特定的+/-LAMBDA通道的增量,加起来,并确定每个LAMBDA的线性回归决定系数。是的,很明显会有遗漏(我把它们算作零),但现在我只想看看过程本身。测定系数(CD)/ LAMBDA让我提醒你,CoD,很简单,是一个一定的百分比,它显示了有多少数据能解释这个模型。当LAMBDA=0.0006时,达到最大值(0.97)。过滤后的增量可以加在一起,得到两个过程。0.0006的数值略低于增量过程的有效值。作为比较,我们可以看一下第二个局部极值,LAMBDA值为0.0023(约3个有效值)。这种 "趋势 "在所有商数上都可以确定,而且有些(和大多数)是向上的,有些是向下的。很明显,这种方法是近乎科学的,但另一方面,它给出了一些想法,一种具有随机结构的系统的替代表示。 一个有趣的结果。 这种现象会不会是由于历史数据是Bid价格造成的?(实验中的Lambda与传播率相当)。 你不认为用具有片状常数系数的线性回归 来测试所产生的 "趋势 "过程的质量,作为时间的函数来看,更有意义吗? Artemka 2012.01.15 11:57 #330 教授,你在第22页图2的图表与 欧元-美元月度 图表非常相似--非常相似。 你可以把过滤后的增量加起来,就可以得到两个过程。 1...262728293031323334353637383940...75 新评论 您错过了交易机会: 免费交易应用程序 8,000+信号可供复制 探索金融市场的经济新闻 注册 登录 拉丁字符(不带空格) 密码将被发送至该邮箱 发生错误 使用 Google 登录 您同意网站政策和使用条款 如果您没有帐号,请注册 可以使用cookies登录MQL5.com网站。 请在您的浏览器中启用必要的设置,否则您将无法登录。 忘记您的登录名/密码? 使用 Google 登录
不是说这是错的。对,就像 "买得便宜,卖得好 "的说法一样正确。重要的不仅仅是正确性,还有形式上的可塑性。构建聪明的哲学近似市场的构架是没有意义的,如果它们(构架)就像山羊的牛奶。
你认为接受损失后的时间间隔是否难以正式确定?或者有什么不同?
谢谢。我将在闲暇时思考SOM。
链接中的文章对时间序列 分割方法进行了概述。他们都做了差不多的事情。并不是说SOM是最好的外汇方法,但也不是最差的,这是一个事实 ))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
我的同事,不幸的是,不允许我给更多的时间来做交易,但我找到了一些时间,决定问一下(为了我自己的利益,所以我不会忘记它:o,所以我以后会回来,当我有更多的空闲时间时)
现象的本质。
让我提醒你这个现象的本质。这是在分析 "长尾 "对未来价格偏离的影响时发现的。如果我们对长尾进行分类,看看没有长尾的时间序列,我们可以观察到一些奇怪的现象,几乎每个符号都是独一无二的。该现象的本质是一种非常具体的分类,以某种方式基于 "神经 "方法。事实上,这种分类法将原始数据,即报价过程本身 "分解 "为两个子过程,习惯上被称为"α"和"β"。一般来说,最初的过程可以被分解成更多的子过程。
具有随机结构的系统
这种现象非常适用于具有随机结构的系统。该模型本身看起来会非常简单。让我们来看看一个例子。最初的欧元兑美元 系列 M15(我们需要一个长的样本,和尽可能小的框架),从一些 "现在"。
步骤1:分类
进行分类,得到两个过程"α"和"β"。定义主流程的参数(该流程涉及报价的最终 "组合")。
第2步 识别
对于每个子过程,都定义了一个基于Volterry网络的模型。
哦,识别它们是多么的痛苦。
步骤3 子过程预测
对每个过程的100个计数进行预测(15分钟,即刚刚超过一天)。
第4步:模拟建模
建立一个模拟模型,它将产生未来实施的x.o.数量。该系统的方案很简单。
三个随机化:每个模型和过程过渡条件的误差。下面是变现本身(从零开始)。
第5步:交易方案。
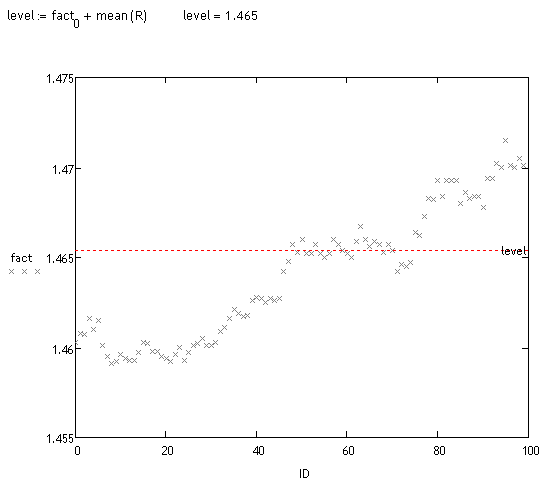
对这些变现进行了偏差分析。这可以通过不同的方式进行。从视觉上我们可以看到,大量的轨迹被转移了。让我们看一下事实。
<>
初步测试
随机进行了大约70次 "测量"(需要很长的时间来计算)。大约70%的系统检测到了正确的偏差,所以它还没有说什么,但我希望在几个月内回到这个轨道上,尽管我还没有完成主要项目的工作 :o(。
对sayfuji
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
不,一切都很正确。这是本主题中几十页的讨论主题之一。所有我认为必要的东西--我都写了。 不幸的是,我没有时间来进一步发展这个话题。此外,这种现象特别有趣,但不是很有希望。"长尾 "现象出现在长周期上,即轨迹有较大偏差的地方,但为此有必要对阿尔法和贝塔过程(以及其他过程)进行远距离预测。而这是不可能的。 没有这样的技术...
:о(
对所有
同事们,事实证明,有些帖子我还没有回答。请原谅我,现在试图移动是没有意义的。
Prohwessor Fransfort,请回答你用哪个程序进行研究。
还有......如果谁有俄文手册或程序的俄文版 http://originlab.com/ (OriginPro 8.5.1)
一个有趣的结果。
这种现象会不会是由于历史数据是Bid价格造成的?(实验中的Lambda与传播率相当)。
你不认为用具有片状常数系数的线性回归 来测试所产生的 "趋势 "过程的质量,作为时间的函数来看,更有意义吗?
你可以把过滤后的增量加起来,就可以得到两个过程。