In mathematics, the term chaos game, as coined by Michael Barnsley,1 originally referred to a method of creating a fractal, using a polygon and an initial point selected at random inside it.2 The fractal is created by iteratively creating a sequence of points, starting with the initial random point, in which each point in the sequence is a...
...
--
做到512,看看你能得到什么。不要害怕紧缩程序,这只会让它变得更好。:)当你完成后,请在这里发布。
好的!在512个通道和144000条。
好吧,如果60岁是最佳状态,那么一般来说就很酷。
//---
也就是说,在这个主题中提出的最弱的笔记本电脑上,这就是结果。所以非常有希望。
//---
不幸的是,我无法自由地讨论这个问题,因为我甚至没有接触过joo 文章和神经网络,而我也从来没有钻研过OpenCL。如果不了解每一行代码,我就无法使用这个或那个代码。我想知道一切。)))我还在研究交易程序引擎。有这么多事情要做,我的脑子已经在打转了。)))
将CountBars增加了30倍(达到4,320,000),决定测试石头的抗负荷能力。
无所谓了:它能工作,能取暖,但不会出太多的汗。温度正在缓慢上升,但已经达到了饱和状态。
红线是温度,绿线是内核的负载。
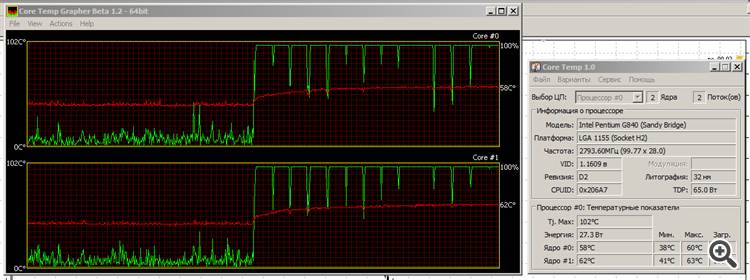
这就是为什么我喜欢英特尔的桑迪桥标本:它是 "绿色 "的。是的,图形不是很好,但我们会看到Ivy Bridge变成什么样子......
这就是为什么我喜欢英特尔的桑迪桥模型:它是 "绿色 "的。是的,图形不是很好,但我们会看到Ivy Bridge 成为什么...哦,(笑)。现在,这是一个真正的压力测试。:)我的可能现在已经死了。
然后是什么哈斯韦尔,再过一会儿是罗克韦尔......。)))
一个在OpenCL中实现巴恩斯利蕨类植物的例子。
该计算基于混沌游戏 算法(示例),使用一个随机数生成器,其生成基数取决于线程ID,并返回get_global_id(0),以创建独特的轨迹。
当缩放时,保持图像质量所需的点的数量呈四次方增长,所以这个实现假设每个内核实例绘制固定数量的落在可见区域的点。
估计线程的数量在第191行中指定。
点的数量是在第233行。
UPD
IFS-fern.mq5--CPU模拟物
在规模=1000时。
我做了三层16x7x3的神经元,其实我前天做的,今天调试的,之前用CPU检查的时候结果不符合--我不在这里 描述原因,至少现在不说--我太困了。:)
时间特征 :
明天我将为这个网格制作优化器。 然后我将忙于加载真实数据,并在MT5测试器可验证的现实计算中完成测试器。 然后我将处理网格的生成器MLP+cl代码,以实现其优化。
由于贪婪,我没有公布源代码,但ex5包括在其中,供那些想在他们的硬件上测试的人使用。
我就像在普京手下一样稳定。
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
顺便说一下,注意:在CPU运行时,你的系统和我的系统(基于奔腾G840)之间的差异并不是很大。
你的RAM快吗?我有1333兆赫。
还有一件事:有趣的是,在计算过程中,两个核心 都加载在CPU上。最后的负荷急剧下降是在计算结束后。这意味着什么呢?
我就像在普京手下一样稳定。
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1.顺便说一下,注意你的系统和我的系统(基于奔腾G840)在CPU执行时间 上的差异。
2.你的内存快吗?我有1333兆赫。
1.我在业余时间一直在恢复我的超频,有一次我遇到了非常严重的死机(后来发现是硬盘电源线从插槽中脱落),于是我按下主板上的 "MemoryOK "按钮,寻找奇迹。之后,它仍然不能工作,只是将CMOS设置重置为默认值。 现在,我又将处理器超频到3840兆赫,所以现在工作得更聪明了。
2.还是搞不清楚。:)特别是,Renat显示的链接的基准,显示为1600MHz。Windows甚至显示1033MHz :)))),尽管内存本身是2GHz,但我母亲可以拉到1866(比喻)。
还有一件事:有趣的是,我在CPU上计算时,两个核心都 加载了。最后的负荷急剧下降是在计算结束后。这将意味着什么?
所以也许根本不是在GPU上,驱动已经启动了,但...我唯一的解释是,计算是在CPU-OpenCL上进行的,当然,只是在所有可用的内核上,并使用向量SSE指令。:)
第二种变体是同时计算CPU和CPU。 我不知道这个(CPU-LPU)支持是如何由驱动实现的,但原则上我不排除opentzl处理启动时也有这样的一种变体。
这是我的推测,如果有的话。或者像现在流行的写法--"IMHO"。;)
我怀疑这一点。特别是因为我只有两个核心。那么25倍的利润从何而来?
好吧,如果岩石有所有的英特尔数学内核 库或英特尔性能原件(我没有下载它们),还是有可能的......在某些情况下。但这不太可能,因为它们重达数百兆。
我得看看谷歌对此有什么说法。
Mathemat: 另外,有趣的是,我的CPU计算有两个核心都 加载。
不,我是指没有任何OpenCL的纯CPU计算。负荷刚好低于100%,其中每个核心都有可比的负荷值。但是当运行OpenCL代码时,它上升到100%,这很容易解释为GPU的操作。