文章 "蒙特卡罗方法在强化学习中的应用"
我愿意为观察结果做出贡献:
本版本的优点:
*************************************
1.与之前的版本不同,此版本不会一直进行交易。当信号良好时,它会有选择性地进行交易。这是满足您需求的一大优势。否则,这是件好事。))..
2.可以快速、轻松地进行优化。
3.训练器模型体积小,因此我们可以训练大数据。
该版本的缺点:
*******************************************
1.很多时候我们需要花费大量时间来进行下一次优化,因此不得不手动停止优化过程。
2.由于某些原因,运行测试不是那么容易。我必须重启 MT5 终端,但有时仍然无法运行。
我的改进建议
*************************************
1.尝试使用至少 4 到 5 个输入函数进行训练,例如开仓、平仓、高位、低位。
2.在优化获取交易信号时,尝试正确使用 "MathMoments ()"函数:
https:// www.mql5.com/en/docs/standardlibrary/mathematics/stat/mathsubfunctions/statmathmoments
3.尝试每天或每周执行迭代训练课程。
这是一种随机结果。
4.尝试多个时间段。
我需要这样做。我们怎样才能做得更好 :))))

- www.mql5.com
敬佩作者又写了一篇有趣的文章,以开放和建设性的态度对待 MO,尽管该主题的其他参与者和管理部门的 Zugunder 在暗中用鼠标做手脚:)
具体到这个问题--我不太理解蒙特卡洛射击寻找目标的意义,因为它们几乎是明确无误的确定性目标,而且可以根据之字形的顶点或相同返回值以更快的速度找到。
在我看来,将这种方法应用于不确定性更大的多维问题,如预测因子的选择和排序,会更加合理。理想情况下,在解决这个问题时,预测因子应该在一个综合体中进行评估,而文章中描述的对每个预测因子单独进行搜索和交替训练,看起来就像是用一个未知数组成方程组。
敬佩作者又写了一篇有趣的文章,以开放和建设性的态度对待 MO,尽管该主题的其他参与者和管理部门的 Zugunder 在暗中用鼠标做手脚:)
具体到这个问题--我不太理解蒙特卡洛射击寻找目标的意义,因为目标几乎是明确确定的,而且可以根据之字形的顶点或相同返回值更快地找到一个数量级。
在我看来,将这种方法应用于不确定性更大的多维问题,如预测因子的选择和排序,会更加合理。理想情况下,在解决这个问题时,预测因子应该在一个复合体中进行评估,而文章中描述的对每个预测因子单独进行搜索和交替训练,看起来就像是在用一个未知数组成方程组。
至于 "明确的确定性"--这是不正确的,因为 TA 数据和 "回报 "在分析时非常模糊和不可靠。
因此,作者没有使用它们,而是用蒙特卡罗方法进行实验。
你好,马克西姆。
有一个问题。
"shift_probab "和 "regularisation "所使用的值仅供优化之用,而不是在 实际交易过程 中使用。我说的对吗?
或者说,在每次优化完成后,是否有必要在图表上设置优化后的 shift_probab 和 regularisation 值?
谢谢。
您好,根据 RL 的所有原则,通过蒙特卡洛随机枚举目标。也就是说,有许多策略(步骤),代理通过 oos 上的最小误差寻找最优策略。新特征的构建也是通过 MSUA 在其中一个库中实现的(参见代码库)。本文只实现了对现有图谱的暴力搜索,而没有构建新图谱。参见递归消除法。也就是说,文件和目标都是递归消除的。以后我还可以提出其他变体,实际上有很多变体。但比较试验需要很多时间。
嗨,当然,随机选择行动是 RL 的基本原则,而且,它可能是必要的,因为代理的不同行动可能会改变环境,从而产生趋于无穷的变体,当然,蒙特卡罗很可能被用来优化这些行动的顺序。
但在我们的案例中,环境--市场报价并不取决于代理的行动,尤其是在所考虑的实施方案中,使用的是事先已知的历史数据,因此代理行动(交易)顺序的选择可以不使用随机方法。
附注:例如,可以通过报价https://www.mql5.com/zh/code/9234 找到具有最大可能利润的目标交易序列。

- www.mql5.com
你好,马克西姆。
有一个问题。
"shift_probab "和 "regularisation "所使用的值仅供优化之用,而不是在 实际交易过程 中使用。我说的对吗?
或者说,在每次优化完成后,是否有必要在图表上设置优化后的 shift_probab 和 regularisation 值?
谢谢。
当然,随机选择行动是 RL 的基本原则,而且可能是必要的,因为代理的不同行动可能会改变环 境,从而产生趋于无穷大的选项数量,当然蒙特卡罗也可以应用于优化这些行动的顺序。
但在我们的案例中,环境--市场报价并不依赖于代理的行动,尤其是在所考虑的实施方案中,使用的是事先已知的历史数据,因此代理行动(交易)顺序的选择无需使用随机方法。
附注:例如,可以通过报价https://www.mql5.com/zh/code/9234,找到利润最大的目标交易序列。
关于 "明确的确定性 "是错误的,因为 TA 的数字和 "回报 "是非常模糊和不可靠的分析。
因此,作者没有使用它们,而是用蒙特卡罗方法进行实验。
新文章 蒙特卡罗方法在强化学习中的应用已发布:
在本文中,我们将应用强化学习来开发可以自主学习的EA交易。在前一篇文章中,我们考虑了随机决策森林算法,并编写了一个简单的基于强化学习的自学习EA,概述了这种方法的主要优点(交易算法的开发简单和“培训”速度快)。强化学习(RL)可以很容易地融入到任何交易EA中,并加速其优化。
停止优化后,只需启用单一测试模式(因为最佳模型已写入文件,并且只上载该模型):
让我们滚动两个月前的历史记录,看看该模型在整个四个月内是如何工作的:
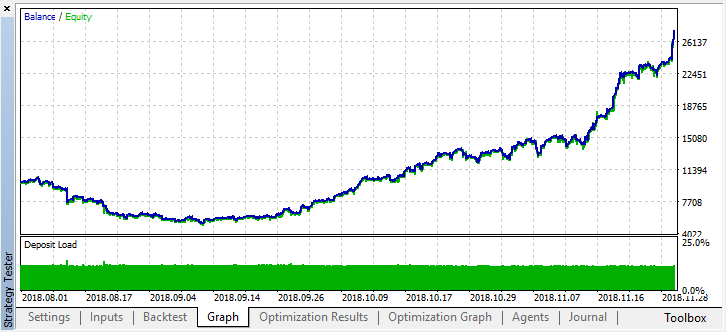
我们可以看到结果模型持续了另一个月(几乎整个9月),而在8月崩溃。作者:Maxim Dmitrievsky