Как совместить информацию по нескольким ТФ для обучения нейросети?
Есть идея обучить нейросеть, чтобы она могла учитывать краткосрочные и среднесрочные движения, т.е. на вход подавать бары разных таймфреймов. Как лучше это сделать?
Так же как если бы вы подавали на вход данные с 1-ного ТФ. Только кол-во входящих сигналов увеличится на кол-во таймфреймов. Лучше всего,я думаю, на вход давать не саму цену, а какое то нормализованное значение. Например разницу между ценой закрытия 1-го бара и 2-го. Тогда получается если эта разница отрицательная то сигмоидальная функция активации будет выдавать значение ниже 0.5 если положительная то значение выше 0.5
Так же как если бы вы подавали на вход данные с 1-ного ТФ. Только кол-во входящих сигналов увеличится на кол-во таймфреймов. Лучше всего,я думаю, на вход давать не саму цену, а какое то нормализованное значение. Например разницу между ценой закрытия 1-го бара и 2-го. Тогда получается если эта разница отрицательная то сигмоидальная функция активации будет выдавать значение ниже 0.5 если положительная то значение выше 0.5
так то оно да, но тут проблема будет при обучении, если мы обучаем Н1 и хотим подавать ТФ W1 и MN , то будет примерно так обучаться:
H1[1] , W1[1] , MN[1]
H1[2] , W1[1] , MN[1]
H1[3] , W1[1] , MN[1]
...
H1[23] , W1[1] , MN[1]
...
H1[1] , W1[2] , MN[1]
....
H1[1] , W1[2] , MN[2]
т.е. на одно изменение W1 будем подавать более сотни Н1 , а на одно изменение MN более 500 изменений H1
имхо веса сети будут некорректно формироваться
так то оно да, но тут проблема будет при обучении, если мы обучаем Н1 и хотим подавать ТФ W1 и MN , то будет примерно так обучаться:
H1[1] , W1[1] , MN[1]
H1[2] , W1[1] , MN[1]
H1[3] , W1[1] , MN[1]
...
H1[23] , W1[1] , MN[1]
...
H1[1] , W1[2] , MN[1]
....
H1[1] , W1[2] , MN[2]
т.е. на одно изменение W1 будем подавать более сотни Н1 , а на одно изменение MN более 500 изменений H1
имхо веса сети будут некорректно формироваться
Тут уже зависит от топологии сети. У меня еще пока мало в этом опыта. Не знаю что из этого получится. Я разбиваю сигналы на группы и для каждой группы сигналов своя отдельная сеть, которую так же можно обучать отдельно от всей сети. Плюс еще одна "обобщающая" сеть, которая работает уже с выходными сигналами этих отдельных сетей. Пример на картинке.
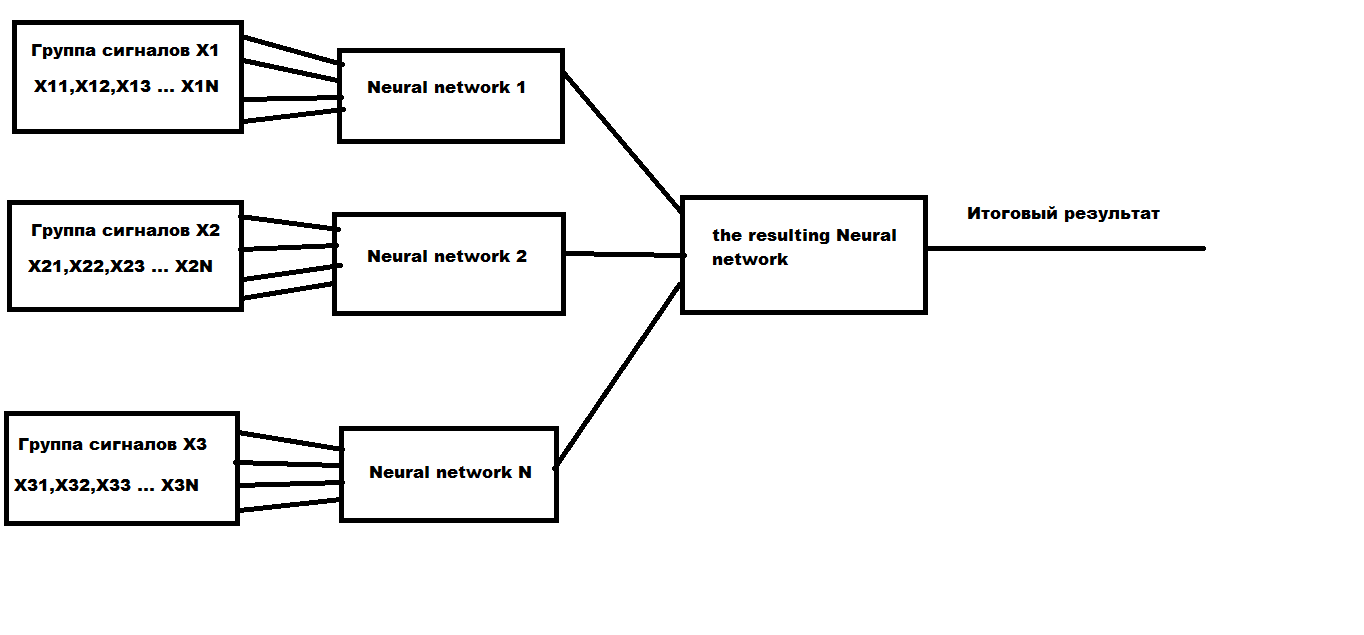
То есть получается на одну сеть подаем сигналы с H1 и обучаем ее торговать на H1. Но вторую сигналы с W1 - обучаем на W1, на третью MN1 и также ее обучаем. Итоговая сеть должна уже принимать решения на основании выводов первых трех сетей. К примеру: если все три сети выдают сигнал покупать, то итоговый сигнал покупать. Группы сигналов должны быть не зависимы друг от друга. А как известно, на разных TF одновременно могут быть разные тренды (на одном тренд вверх, на другом вниз, на 3-м флет ....) . По этому условие независимости соблюдаются.
сложно предположить как формирует в итоге "черный ящик" свои результаты
да и задача обучать старшим ТФ из младших...имхо это не формализованная задача, некая эвристика )))
по идее задача ТС должна решаться просто увеличением размера входных данных, т.е. хотим "прихватить" старший ТФ из Н1, значит для W1 мы должны использовать 24ч * 5 дней = 120 баров Н1, для MN соответственно 24ч * 30 дней = 720 баров...
но тут возникает много проблем, есть пропуски баров, насколько вероятно, что при таком большом кол-ве входов НС оценит значимость старших ТФ...
имхо, такую задачу (в теории) решают LSTM-сети, но... все равно будем иметь "черный ящик", который видит свою целесообразность использования входных данных
ЗЫ: все не соберусь дочитать как работают ансамбли НС, возможно там ответ, как у Вас на рисунке
сложно предположить как формирует в итоге "черный ящик" свои результаты
да и задача обучать старшим ТФ из младших...имхо это не формализованная задача, некая эвристика )))
по идее задача ТС должна решаться просто увеличением размера входных данных, т.е. хотим "прихватить" старший ТФ из Н1, значит для W1 мы должны использовать 24ч * 5 дней = 120 баров Н1, для MN соответственно 24ч * 30 дней = 720 баров...
но тут возникает много проблем, есть пропуски баров, насколько вероятно, что при таком большом кол-ве входов НС оценит значимость старших ТФ...
имхо, такую задачу (в теории) решают LSTM-сети, но... все равно будем иметь "черный ящик", который видит свою целесообразность использования входных данных
ЗЫ: все не соберусь дочитать как работают ансамбли НС, возможно там ответ
Да действительно, можно и так. Старший TF состоит из последовательности баров младшего TF. Можно просто подавать на вход, как вы написали, больше данных с рабочего TF (принятого основным). По аналогии, как если на H1 установить MA c периодом 24. И на D1 MA с периодом 1. По идее если пропусков баров нет то они должны выдавать одинаковое значение.
По аналогии, как если на H1 установить MA c периодом 24. И на D1 MA с периодом 1. По идее если пропусков баров нет то они должны выдавать одинаковое значение.
нет!
нет!
Очень информативный комментарий :)
Очень информативный комментарий :)
:)
MA(1) D1 не равно MA(24) на Н1. (как и любая другая функция). Если хотите симулировать старший таймфрейм используя текущий, то нужно брать не все точки, т.е. пропускать (если речь о ценах закрытия) - именно так формируется старший тф, а не усреднением.
например, в вашем примере с МА на H1 брать каждую 24ю цену закрытия (если бары не пропущены).
По предложенной вами схеме это не будет обучением на двух ТФ, а по прежнему на одном ТФ. Либо нужен блок подготовки данных, ведь очевидно, что из младшего ТФ можно собрать старший :)
Что-то сумбурно получилось :( прежний комментарий был точнее :)
:)
MA(1) D1 не равно MA(24) на Н1. (как и любая другая функция). Если хотите симулировать старший таймфрейм используя текущий, то нужно брать не все точки, т.е. пропускать (если речь о ценах закрытия) - именно так формируется старший тф, а не усреднением.
например, в вашем примере с МА на H1 брать каждую 24ю цену закрытия (если бары не пропущены).
По предложенной вами схеме это не будет обучением на двух ТФ, а по прежнему на одном ТФ. Либо нужен блок подготовки данных, ведь очевидно, что из младшего ТФ можно собрать старший :)
Что-то сумбурно получилось :( прежний комментарий был точнее :)
Наоборот, теперь понятно, что вы имели в виду под словом "нет". Я не проверял правильность моего утверждения (по поводу МА на H1 и D1). Это был скорее всего не совсем удачный пример моего предыдущего высказывания (про последовательность баров), которое вы выдернули из контекста.
так то оно да, но тут проблема будет при обучении, если мы обучаем Н1 и хотим подавать ТФ W1 и MN , то будет примерно так обучаться:
H1[1] , W1[1] , MN[1]
H1[2] , W1[1] , MN[1]
H1[3] , W1[1] , MN[1]
...
H1[23] , W1[1] , MN[1]
...
H1[1] , W1[2] , MN[1]
....
H1[1] , W1[2] , MN[2]
т.е. на одно изменение W1 будем подавать более сотни Н1 , а на одно изменение MN более 500 изменений H1
имхо веса сети будут некорректно формироваться
Да, примерно об этом я и думал, только немного иначе.
Я хотел брать некоторый диапазон баров с каждого ТФ (например по 100 баров) и смещать это окно на один бар (имитация реальных торгов), таким образом иметь достаточно большой входной вектор.
Примерно так:
H1[1] , H1[2], H1[3], H1[4], ..., H1[100], W1[1], W1[2], W1[3], W1[4], ..., W1[100], MN[1], MN[2], MN[3], MN[4], ..., MN[100]
H1[2] , H1[3], H1[4], H1[5], ..., H1[101], W1[2], W1[3], W1[4], W1[5], ..., W1[101], MN[2], MN[3], MN[4], MN[5], ..., MN[101]
H1[3] , H1[4], H1[5], H1[6], ..., H1[102], W1[3], W1[4], W1[5], W1[6], ..., W1[102], MN[3], MN[4], MN[5], MN[6], ..., MN[102]
Да, получится, что крайний бар старшего ТФ долго будет оставаться без изменений, но его цена закрытия (максимум и минимум) всё равно будет изменяться, т.к. он состоит из баров младшего тф, а они будут "поступать" динамически, а не все сразу. Я имею в виду имитацию поступления котировок как в реальном времени, т.е. датасет для обучения будет формироваться так, как будто истории нет, а торговля ведётся прямо сейчас. Это позволит избежать излишнего застоя в барах старших таймфреймов.
По поводу ансамбля сетей, я об этом тоже думал, но, чисто, абстрактно, можно предположить, что кол-во фич на одном тф будет несравнимо меньше, чем от комбинации нескольких тф. С этим всем надо экспериментировать, но лично я бы создал ансамбль для всех возможных пар из заданных таймфреймов. А выходы таких сетей сделал как можно более разнообразными (скажем, классификация на 10000 признаков), т.к. эти выходы всё равно будет читать результирующая сеть, а не человек.
В результате, должно получиться так, что сеть не будет давать сигнал на покупку/продажу на каждом баре, а долгое время будет давать нейтральный сигнал, чтобы оставаться вне рынка. Выжидание подходящего хорошего входа это важно.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Есть идея обучить нейросеть, чтобы она могла учитывать краткосрочные и среднесрочные движения, т.е. на вход подавать бары разных таймфреймов. Как лучше это сделать?