Bibliotecas: Statistical Functions
Como você implementa?
Obrigado pelo interesse em minha biblioteca. É muito fácil usá-la, pois você opera principalmente em matrizes de 1 dimensão.
Por exemplo, você pode remover facilmente a tendência linear da série temporal com a função detrend:
detrend(timeSerie, detrendResultArray);
timeSerie é uma matriz preenchida com preços e detrendResultArray deve ser uma matriz vazia na qual os resultados serão armazenados.
Portanto, após a chamada da função, você terá uma matriz com uma série temporal detrendida na qual poderá realizar uma análise adicional (por exemplo, verificar se a série é estacionária).
Por exemplo, supondo que você tenha uma matriz com Currency1 (possivelmente retroativa), você pode prever seu próximo valor com:
double detrendedSerie[]; double forecastedValue; //fazer com que Currency1 seja armazenada de trás para frente (o último valor na matriz é o preço mais recente) detrend(Currency1, detrendedSerie); if(dickeyFuller(detrendedSerie)){ forecastedValue = AR1(detrendedSerie); } if(forecastedValue > detrendedSerie[ArraySize(detrendedSerie)-1]){ //Comprar }else{ //Vender }
Outra função interessante disponível é a integral assinada. Usá-la na forma atual é muito fácil, basta chamar a função, definir os limites e o grau polinominal (que pode ser pequeno),
para obter uma boa aproximação da integral dada. Você também pode editar a função "foo" para integrar funções diferentes de f(x) = x.
Como você implementa?
Como você implementa?
{kind=link}
Fico feliz em saber que você gostou! Por favor, cole aqui um link se você criar algum EA/Indicador usando essa biblioteca.
Olá, Herajika,
Estou tentando replicar as estatísticas do teste Dickey-Fuller do código que você compartilhou com outro software estatístico/matemático. Especificamente, estou usando o Wolfram Mathematica para isso.
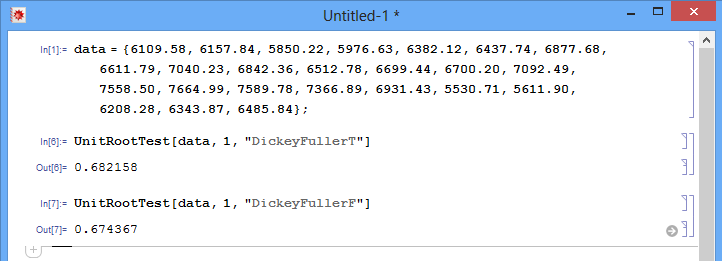
Considere os dados do artigo original que você usou (do Scribd):
double data[] = {6109.58, 6157.84, 5850.22, 5976.63, 6382.12, 6437.74, 6877.68, 6611.79, 7040.23, 6842.36, 6512.78, 6699.44, 6700.20, 7092.49, 7558.50, 7664.99, 7589.78, 7366.89, 6931.43, 5530.71, 5611.90, 6208.28, 6343.87, 6485.84};
Para obter as estatísticas de teste usando seu código, removi o comentário antes da função Print, como pode ser visto no código abaixo:
bool dickeyFuller(double &arr[]) { // n=25 50 100 250 500 >500 // {-2.62, -2.60, -2.58, -2.57, -2.57, -2.57}; double cVal; bool result; int n=ArraySize(arr); double tValue; double corrCoeff; double copyArr[]; double difference[]; ArrayResize(difference,n-1); //--- for(int i=0; i<n-1; i++) { difference[i]=arr[i+1]-arr[i]; } //--- ArrayCopy(copyArr,arr,0,0,n-1); corrCoeff=correlation(copyArr,difference); tValue=corrCoeff*MathSqrt((n-2)/1-MathPow(corrCoeff,2)); //--- if(n<25) { cVal=-2.62; }else{ if(n>=25 && n<50) { cVal=-2.60; }else{ if(n>=50 && n<100) { cVal=-2.58; }else{ cVal=-2.57; } } } Print(tValue); //--- Estatísticas de teste ?? result=tValue>cVal; return(result); }
Como dito, estou mais interessado nas estatísticas do teste em si, em vez de apenas na conclusão do teste. Nesse sentido, usando o código que você compartilhou, obtive:
void OnStart() { //--- FONTE: http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel# double data[] = {6109.58, 6157.84, 5850.22, 5976.63, 6382.12, 6437.74, 6877.68, 6611.79, 7040.23, 6842.36, 6512.78, 6699.44, 6700.20, 7092.49, 7558.50, 7664.99, 7589.78, 7366.89, 6931.43, 5530.71, 5611.90, 6208.28, 6343.87, 6485.84}; //--- dickeyFuller(data); }
Como agora estou imprimindo a linha com as estatísticas do teste, obtenho:
-1.719791886975595No entanto, o artigo original afirma que a estatística t é 1,8125.
No entanto, quando uso o Wolfram Mathematica no mesmo conjunto de dados, obtenho::

Você tem alguma ideia do que poderia ser a causa de 3 testes darem 3 resultados de teste diferentes?
Atenciosamente,
Malacarne
Olá! Quanto à diferença entre o resultado do artigo(http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel#) e minha implementação,
observe que, no site mencionado, há um problema com a exibição dos sinais (+, -). Portanto, na verdade, o resultado apresentado no artigo é -1,8125.
Quanto à diferença com o Wolfram Mathematica, talvez as diferentes implementações de tendência usem valores críticos diferentes e calculem os valores t de forma diferente. Ao fazer o mesmo no Matlab, obtive
mais um resultado (0,6518).
No entanto, se você tentar o mesmo no Excel, ele deverá mostrar algo próximo a -1,8125.
Atenciosamente,
Herajika
Olá! Quanto à diferença entre o resultado do artigo(http://pt.scribd.com/doc/80877200/How-to-do-a-Dickey-Fuller-Test-using-Excel#) e minha implementação,
observe que, no site mencionado, há um problema com a exibição dos sinais (+, -). Portanto, na verdade, o resultado apresentado no artigo é -1,8125.
Quanto à diferença com o Wolfram Mathematica, talvez as diferentes implementações de tendência usem valores críticos diferentes e calculem os valores t de forma diferente. Ao fazer o mesmo no Matlab, obtive
mais um resultado (0,6518).
No entanto, se você tentar o mesmo no Excel, ele deverá mostrar algo próximo a -1,8125.
Atenciosamente,
Herajika
Olá , Herajika,
Obrigado pela resposta. Então, nesse caso, qual estatística deve ser considerada a correta?
O artigo original está mostrando valores errados para as estatísticas de teste?
Atenciosamente,
Malacarne
P.S.: no Mathematica, se eu não usar a opção "TestStatistic", obtenho resultados semelhantes em comparação com o MatLab.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Statistical Functions:
Autor: Haruna Nakamura