Discussão do artigo "Redes neurais de maneira fácil (Parte 29): Algoritmo ator-crítico de vantagem (Advantage actor-critic)"
Olá,
Bom trabalho! Tenho trabalhado ativamente em algoritmos de negociação baseados em aprendizado por reforço e gosto de seus artigos sobre o assunto.
Tenho uma pergunta sobre os resultados. Vejo que você está mostrando apenas o desempenho de negociação dos primeiros 10 dias (2022-09-01 até 2022-09-10). O EA estava perdendo após o 10º dia?
/Rasoul
Oi Dmitriy
Muito obrigado pela série exaustiva e muito instrutiva de artigos. Muito bem feito.
Só uma pergunta: depois de baixar todo o código do anexo do seu último artigo (nº 29), não consigo compilar porque está faltando a definição da classe CBufferDouble, que eu suponho que deveria estar dentro de
NeuroNet_DNG\NeuroNet.mqh
mas não está.
Estou perdendo alguma coisa?
Obrigado!
Atenciosamente
Paolo
Oi Dmitriy
Muito obrigado pela série exaustiva e muito instrutiva de artigos. Muito bem feito.
Só uma pergunta: depois de baixar todo o código do anexo do seu último artigo (nº 29), não consigo compilar porque está faltando a definição da classe CBufferDouble, que, suponho, deveria estar dentro de
NeuroNet_DNG\NeuroNet.mqh
mas não está.
Estou perdendo alguma coisa?
Obrigado!
Com os melhores cumprimentos
Paulo
Olá, no último artigo, mudei CBufferDouble para CBufferFloat. Isso ajuda a executar a biblioteca na GPU sem o tipo double.
Oi Dmitriy,
Ótima série, sou um grande fã desse trabalho. Também tentei compilar o Reinforce EA e vi que ele também precisava do codificador aunto (é claro), então adicionei a última versão incluída (da postagem 22) VAE.mqh, mas, por algum motivo, ele não consegue encontrar as definições do Normal.mqh:
![]()
Tenho certeza de que fiz algo errado, espero que possa me ajudar.
Obrigado!
Oi Dmitriy,
Ótima série, sou um grande fã desse trabalho. Também tentei compilar o Reinforce EA e vi que ele também precisava do codificador aunto (é claro), então adicionei a última versão incluída (da postagem 22) VAE.mqh, mas, por algum motivo, ele não consegue encontrar as definições do Normal.mqh:
Tenho certeza de que fiz algo errado, espero que você possa ajudar.
Obrigado!
Olá, carregue a última versão deste artigo https://www.mql5.com/ru/articles/11804
: Полностью параметризированная квантильная функция")
- www.mql5.com
Obrigado, Dmitriy, pela resposta rápida e por fornecer sua ajuda e tempo valioso, mas ainda obtive o mesmo resultado.
Aparentemente, o aprendizado do FQF chama o FQF.mqh
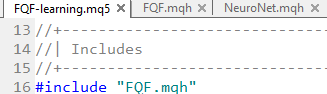
Que, por sua vez, exige o NeuroNet...
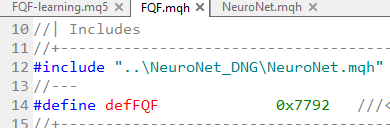
E, é claro, esse último chama o VAE.mqh
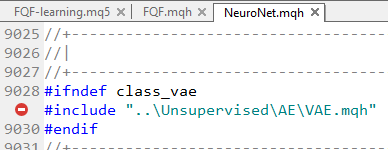
E a única versão que consegui encontrar foi a da postagem 22...
O uso dessa versão faz com que o VAE não encontre referência às funções Normal.mqh
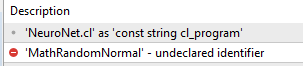
Seria a versão do meu Editor?

Muito obrigado.
...Bem, por alguma razão, a biblioteca Normal não pode ser acessada no VAE.mqh se for chamada a partir do NeuroNet, eu realmente não sei por que (tentei em duas compilações diferentes)...
Então, resolvi isso adicionando a chamada para a Normal diretamente no VAE e na Neuronet, mas tive que me livrar do espaço Math no FQF:
estranho... mas funcionou:
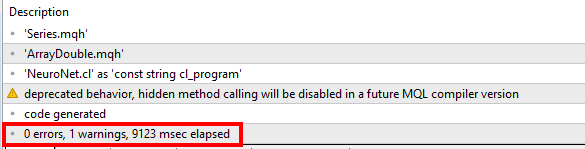
A inicialização falhou devido à ausência do EURUSD_PERIOD_H1_REINFORCE.nnw ao executar as seguintes instruções
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
retorna INIT_FAILED;
Como resolver esse problema? Obrigado.
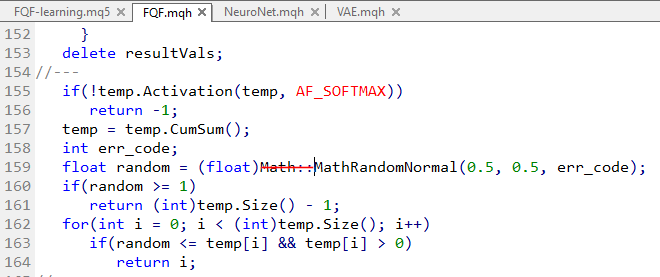
Outra solução para um aviso "... hidden method calling ..."
Na linha 327 de Actor_Critic.mq5:

Estou recebendo o aviso "comportamento obsoleto, a chamada de método oculto será desativada em uma versão futura do compilador MQL":

Isso se refere à chamada de "Maximum(0, 3)", que deve ser alterada para:

Portanto, nesse caso, temos que adicionar "CArrayFloat::" para especificar o método em questão. O método Maximum() é sobrescrito pela classe CBufferFloat, mas esse método não tem parâmetros.
Embora a chamada não deva ser ambígua porque tem dois parâmetros, o compilador quer que estejamos atentos ;-)
A inicialização falhou devido à ausência do EURUSD_PERIOD_H1_REINFORCE.nnw ao executar as seguintes instruções
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) ||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
retorna INIT_FAILED;
Como resolver esse problema? Obrigado.
Nessas linhas, a estrutura de rede que deve ser treinada é carregada. Você precisa criar a rede e salvá-la no arquivo nomeado antes de iniciar esse EA. Você pode usar, por exemplo, a ferramenta de criação de modelos no Artigo nº 23
: Practicing Transfer Learning")
- www.mql5.com
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Redes neurais de maneira fácil (Parte 29): Algoritmo ator-crítico de vantagem (Advantage actor-critic) foi publicado:
Nos artigos anteriores desta série, conhecemos 2 algoritmos de aprendizado por reforço. Cada um deles tem suas próprias vantagens e desvantagens. Como costuma acontecer quando nos deparamos com esses casos, surge a ideia de combinar os dois métodos em um algoritmo que incorpore o melhor dos dois. E assim compensar as deficiências de cada um deles. Falaremos sobre tal combinação de métodos neste artigo.
Como vantagem do retreinamento dos modelos dos artigos anteriores, podemos mencionar o fato de podermos utilizar os EAs de teste do artigo anterior para verificar seus resultados de treinamento. Eu fiz isso. Depois de treinar o modelo, peguei o modelo de política retreinado e rodei o EA "REINFORCE-test.mq5" no testador de estratégia usando o modelo mencionado. O algoritmo para sua construção foi descrito no artigo anterior. E seu código completo pode ser encontrado no anexo.
Abaixo está um gráfico do balanço do EA durante os testes. É importante notar que o balanço aumentou bastante uniformemente durante o teste. Observe que o modelo foi testado com dados não incluídos no conjunto de treinamento. O que fala sobre a consistência da abordagem para construir um sistema de negociação. Para uma verificação impecável do trabalho do modelo, todas as operações foram realizadas com um lote mínimo fixo sem o uso de stop loss e take profit. O uso de tal EA é altamente desencorajado para negociação real, mas demonstra bem o trabalho do modelo treinado.
No gráfico de preços, pode-se ver com que rapidez os negócios perdedores são fechados e as posições lucrativas são mantidas um pouco. Aqui é necessário prestar atenção para que todas as operações sejam realizadas na abertura de uma nova vela. Ao fazer isso, pode-se notar várias operações de negociação realizadas quase na abertura das velas (de fractal) de reversão.
Autor: Dmitriy Gizlyk