Discussão do artigo "Redes neurais de maneira fácil (Parte 27): Aprendizado Q profundo (DQN)"
Для тестирования была создана сверточная модель следующей архитектуры:
- Camada de dados de origem, 240 elementos (20 velas, 12 neurônios por descrição de uma vela).
- Camada convergente, janela de dados de origem 24 (2 velas), etapa 12 (1 vela), 6 filtros de saída.
- Camada convergente, janela de dados de origem 2, etapa 1, 2 filtros.
- Camada de colapso, janela de dados de origem 3, etapa 1, 2 filtros.
- Camada convergente, janela de dados de origem 3, etapa 1, 2 filtros.
- Camada neural totalmente conectada com 1.000 elementos.
- Camada neural totalmente conectada de 1000 elementos.
- Camada totalmente conectada de 3 elementos (camada de resultado para 3 ações).
Alguém já descobriu como fazer isso?
Tenho o Transfer Lerning, ele funciona, compilado, mas como criar esse modelo nele?
Alguém já descobriu como fazer isso?
Tenho o Transfer Lerning, ele funciona, compilado, mas como criar esse modelo nele?
1. Inicie o TransferLearning.
2. NÃO abra nenhum modelo.
3. Basta inserir um novo modelo, como adicionar novas camadas neurais.
4. Clique em salvar modelo e especifique o nome do arquivo que será carregado do programa.
1. Inicie o TransferLearning.
2. NÃO abra nenhum modelo.
3.Basta inserir um novo modelo, como adicionar novas camadas neurais.
4. Clique em salvar modelo e especifique o nome do arquivo que será carregado do programa.
Que tipo de camadas e o que selecionar? Há vários tipos e vários parâmetros lá
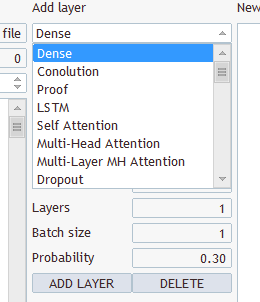
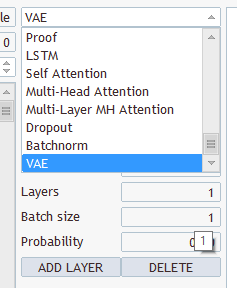
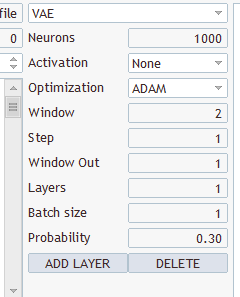
Escolha qualquer um, salve em "EURUSD_PERIOD_H1_Q-learning.nnw", execute Q-learning.mq5, ele escreve no registro.
2022.10.14 15:09:51.743 Experts initialising of Q-learning (EURUSD,H1) failed with code 32767 (incorrect parameters)
E na aba Experts:
2022.10.14 15:09:51.626 Q-learning (EURUSD,H1) OpenCL: dispositivo GPU 'NVIDIA GeForce RTX 3080' selecionado
2022.10.14 15:09:51.638 Q-learning (EURUSD,H1) EURUSD_PERIOD_H1_Q-learning.nnw
Olá, Sr. Gizlyk, antes de mais nada, gostaria de agradecê-lo por sua série bem fundamentada. No entanto, como sou um novato, tenho que enfrentar alguns problemas para entender seu artigo atual. Depois de conseguir reconstruir o arquivo VAE.mqh e a classe CBufferDouble de seus artigos anteriores, posso compilar o aplicativo de amostra deste artigo. Para testar, tentei criar uma rede com seu programa NetCreater. Desisti depois de muitas tentativas. As redes salvas não foram aceitas pelo seu aplicativo deste artigo. Você também não poderia oferecer a rede que criou para download? Mais uma vez, obrigado por seu trabalho!
Olá, Sr. Gizlyk, antes de mais nada, gostaria de agradecê-lo por sua série bem fundamentada. No entanto, como sou um novato, tenho que enfrentar alguns problemas para entender seu artigo atual. Depois de conseguir reconstruir o arquivo VAE.mqh e a classe CBufferDouble de seus artigos anteriores, posso compilar o aplicativo de amostra deste artigo. Para testar, tentei criar uma rede com seu programa NetCreater. Desisti depois de muitas tentativas. As redes salvas não foram aceitas pelo seu aplicativo deste artigo. Você também não poderia oferecer a rede que criou para download? Mais uma vez, obrigado por seu trabalho!
Boa tarde!
Depois que o treinamento não é salvo, o modelo treinado:,
2024.06.01 01:12:26.731 Q-learning (XAUUSD_t,H1) XAUUSD_t_PERIOD_H1_Q-learning.nnw
2024.06.01 01:12:26.833 Q-learning (XAUUSD_t,H1) Iteração 980, perda 0,75659
2024.06.01 01 01:12:26.833 Q-learning (XAUUSD_t,H1) Função ExpertRemove() chamada
Tentando executar o erro do testador:
2024.06.01 01 01:16:31.860 Core 1 2024.01.01 01 01 00:00:00 XAUUSD_t_PERIOD_H1_Q-learning-test.nnw
2024.06.01 01 01:16:31.860 Core 1 testerstopped because OnInit returns non-zero code 1
2024.06.01.01 01 01:16:31.861 Core 1 desconectado
2024.06.01.01 01 01:16:31.861 Core 1 conexão fechada
Quem já se deparou com esse tipo de situação, como resolveu o problema, pode me ajudar?
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Novo artigo Redes neurais de maneira fácil (Parte 27): Aprendizado Q profundo (DQN) foi publicado:
Continuamos nosso estudo sobre aprendizado por reforço. E, neste artigo, vamos nos familiarizar com o método de aprendizado Q profundo. Com esse método, a equipe do DeepMind criou um modelo que pode superar um humano ao jogar jogos do Atari. Acho que será útil avaliar as possibilidades de tal tecnologia para resolver problemas de negociação.
Você provavelmente já adivinhou que o aprendizado Q profundo envolve o uso de uma rede neural para aproximar a função Q. Qual é a vantagem de tal abordagem? Vamos relembrar a implementação do método tabular de entropia cruzada visto no último artigo. Lembre que eu enfatizei que a elaboração de um método de tabela pressupõe um número finito de estados e de ações possíveis. É claro que limitamos o número de estados possíveis agrupando os dados iniciais. Mas é tão bom? O agrupamento sempre nos dará melhores resultados? Ao fazer isso, o uso de rede neural não limita o número de estados possíveis diante de nós. E creio que, no que diz respeito à resolução de problemas de negociação, isto é uma grande vantagem.
E aqui parece bastante óbvio pegar e substituir a tabela do artigo anterior por uma rede neural. Mas, infelizmente, nem tudo é tão simples. Na prática, essa abordagem acaba por não ser tão boa quanto parece à primeira vista. Para implementar a abordagem, precisamos adicionar algo de heurística.
Primeiro, vamos olhar para o propósito do treinamento de nosso agente. Basicamente, seu objetivo é maximizar a recompensa total. Veja a figura 1. O agente deve passar da célula Start para a célula Finish. O agente recebe uma recompensa única quando atinge a célula Finish. Em todos os outros estados, a recompensa é zero.
A figura mostra 2 caminhos. É óbvio para nós que o caminho laranja é mais curto e preferível. Mas em termos de maximização de recompensa, eles são equivalentes.
Autor: Dmitriy Gizlyk