Regressão Bayesiana - Alguém já fez um EA usando este algoritmo? - página 40
Você está perdendo oportunidades de negociação:
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Registro
Login
Você concorda com a política do site e com os termos de uso
Se você não tem uma conta, por favor registre-se
E minha alma continua querendo se aprofundar no assunto de citações incrementais supostamente distribuídas normalmente.
Se alguém for a favor, eu darei argumentos para que este processo não possa ser normal. E estes argumentos serão compreensíveis para todos, ao mesmo tempo em que serão coerentes com o CPT. E estes argumentos são tão triviais que não deve haver dúvidas.
E o que expressará a probabilidade, a previsão para a próxima barra, ou o vetor de movimento das próximas barras?
A probabilidade expressará a previsão do próximo tick (incremento). Eu só quero:
- calcular os valores dos futuros carrapatos Ybayes para os quais a probabilidade pela fórmula Bayes será máxima.
- Compare Ybayes com os carrapatos reais Yreal que estão chegando. Coletar e processar as estatísticas .
Se a diferença de valores estiver dentro de uma faixa razoável, então postarei o código e perguntarei o que fazer a seguir. Regressão? Vetor? Escamação?
A probabilidade expressará a previsão do próximo tick (incremento). Eu só quero:
Por que descer para os carrapatos? Você pode aprender a prever as direções dos tick em 5 minutos com 70% de precisão, mas 100 ticks à frente, você sabe que a precisão cairá.
Tente com incrementos de meia hora ou uma hora de antecedência. É interessante para mim também, talvez eu possa ajudar de alguma forma.
A probabilidade expressará a previsão do próximo tick (incremento). Eu só quero:
- calcular os valores dos futuros carrapatos Ybayes para os quais a probabilidade pela fórmula Bayes será máxima.
- Comparar Ybayes com carrapatos Yreal reais chegando . Coletar e processar as estatísticas .
Se a diferença de valores estiver dentro de uma faixa razoável, postarei o código e perguntarei o que fazer a seguir. Regressão? Vetor? Curva? Escamação?
O que há de errado com a ARIMA? Em pacotes o número de diffs (incrementos de incrementos) é calculado automaticamente, dependendo do fluxo de entrada. Muitas sutilezas relacionadas à estacionaridade estão escondidas dentro da embalagem.
Se você realmente quer ir tão fundo, um pouco de ARCH?
Eu tentei uma vez. O problema é este. O incremento pode ser calculado facilmente. Mas se adicionarmos o intervalo de confiança deste incremento ao próprio incremento, ele será COMPRAR ou VENDER, já que o valor do preço anterior cai dentro do intervalo de confiança.
Sim, a abordagem clássica, como a SanSanych escreve, é a análise de dados, requisitos de dados e erros de sistema.
Mas esta linha é sobre Bayes e estou tentando pensar em termos Bayesianos, como o soldado na trincheira calculando a probabilidade posterior (após a experiência). Eu dei um exemplo do soldado acima.
Uma das principais questões é o que tomar como probabilidade a priori. Em outras palavras, quem devemos colocar atrás da cortina do futuro, à direita da barra zero? Gauss? Laplace? Wiener? O que os matemáticos profissionais escrevem aqui (para mim uma "floresta" escura)?
Eu escolho Gauss porque tenho uma idéia de distribuição normal e acredito nela. Se não "disparar", então é possível tomar outras leis e substituir Gauss em vez da fórmula Bayes, ou junto com Gauss como produto de duas probabilidades. Tente fazer uma rede Bayesiana, se eu a entendi corretamente.
Naturalmente, não posso fazer isso sozinho. Eu gostaria de resolver o problema com Gauss, que formulei sob o buquê. Se alguém estiver disposto a se juntar a mim voluntariamente, por favor, faça-o. Aqui está um problema real.
Dado: МТ4 gerador de números aleatórios.
Necessidade: Escreva o código MQL4 como função FP() convertendo a matriz MT4[] formada pelo RNG padrão em matriz ND[] com distribuição normal.
Vasily (não conheço meu patronímico) Sokolov me mostrou as fórmulas de transformação em https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
O altruísmo e a gentileza serão uma representação gráfica dos resultados, embora eu possa ampliar os gráficos das arrays calculadas diretamente na janela MT4. Eu estava fazendo isso em meus projetos.
Entendo que muitas pessoas aqui podem resolver este problema com alguns cliques em pacotes de matemática, mas eu quero falar em uma linguagem MQL4, que é comumente entendida por comerciantes, programadores, economistas e filósofos.
Sim, a abordagem clássica, como a SanSanych escreve, é a análise de dados, requisitos de dados e erros de sistema.
Mas esta linha é sobre Bayes e estou tentando pensar em termos Bayesianos, como o soldado na trincheira calculando a probabilidade posterior (após a experiência). Eu dei um exemplo do soldado acima.
Uma das principais questões é o que tomar como probabilidade a priori. Em outras palavras, quem devemos colocar atrás da cortina do futuro, à direita da barra zero? Gauss? Laplace? Wiener? O que os matemáticos profissionais escrevem aqui (para mim uma "floresta" escura)?
Eu escolho Gauss porque tenho uma idéia de distribuição normal e acredito nela. Se não "disparar", então é possível tomar outras leis e substituir Gauss em vez da fórmula Bayes, ou junto com Gauss como produto de duas probabilidades. Tente fazer uma rede Bayesiana, se eu a entendi corretamente.
Naturalmente, não posso fazer isso sozinho. Eu gostaria de resolver o problema com Gauss, que formulei sob o buquê. Se alguém estiver disposto a se juntar a mim voluntariamente, por favor, faça-o. Aqui está um problema real.
Dado: МТ4 gerador de números aleatórios.
Necessidade: Escreva o código MQL4 como função FP() convertendo a matriz MT4[] formada pelo RNG padrão em matriz ND[] com distribuição normal.
Vasily (não conheço meu patronímico) Sokolov me mostrou as fórmulas de transformação em https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
No entanto, eu posso e posso rescindir gráficos de arrays calculados diretamente na janela MT4. Eu estava fazendo isso em meus projetos.
Entendo que muitos comerciantes podem resolver este problema em alguns cliques usando pacotes matemáticos, mas quero usar a linguagem MQL4, que é geralmente acessível a comerciantes, programadores, economistas e filósofos.
Aqui está um gerador com diferentes distribuições, incluindo a normal:
https://www.mql5.com/ru/articles/273
Breve análise da distribuição em R:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Estimamos os parâmetros da distribuição normal a partir dos incrementos de preço de abertura de barras de relógio disponíveis e plotamos para comparar a freqüência e densidade para a série original e a série normal com as mesmas distribuições. Como você pode ver até mesmo a olho nu, a série original de incrementos de barras horárias está longe de ser normal.
E, a propósito, não estamos em um templo de Deus. Não é necessário e até prejudicial acreditar.
Aqui está uma linha curiosa do correio acima, que ecoa o que escrevi acima
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Até onde entendo em quadrantes, 50% de todos os incrementos no horário de trabalho são menos de 7 pips! E os incrementos mais decentes estão nas caudas grossas, ou seja, no outro lado do bem e do mal.
Então, como será o TS? Esse é o problema, não o Bayesiano e outros, outros, outros....
Ou deveria ser entendido de alguma outra forma?
Aqui está uma linha curiosa do correio acima, que ecoa o que escrevi acima
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
Até onde entendo em quadrantes, 50% de todos os incrementos no horário são menos de 7 pips! E os incrementos mais decentes estão nas caudas grossas, ou seja, no outro lado do bem e do mal.
Então, como será o TS? Esse é o problema, não o Bayesiano e outros, outros, outros....
Ou deveria ser entendido de alguma outra forma?
SanSanych, sim!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')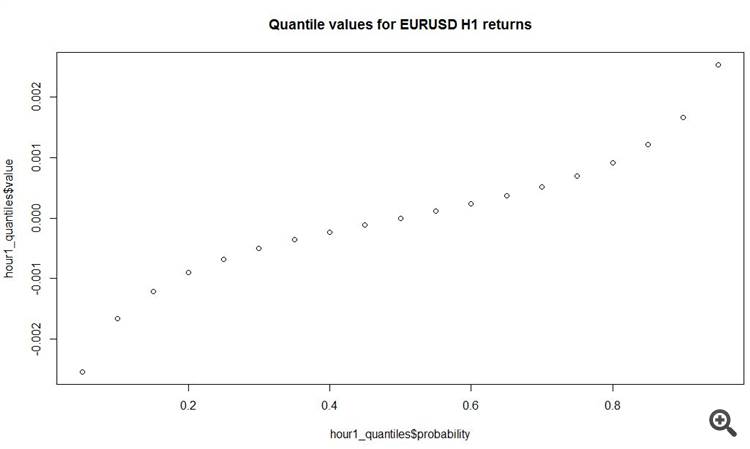
E outra coisa interessante é que o incremento médio absoluto nas barras horárias é de 11 pips! Total.
Você terá que fazer isso por muito tempo, porque precisa de retransformação e... E a Box-Cox não gosta muito)))) É apenas uma pena que se você não tiver
É uma pena que, se você não tiver bons preditores, isso não terá muito efeito no resultado final...