즉, 이 스레드에서 제시된 가장 약한 랩톱에서 이것이 결과입니다. 그래서 매우 유망합니다.
//---
유감스럽게도 저는 아직 이 주제에 대해 자유롭게 이야기할 수 없습니다. 제가 joo 기사를 공부하지도 않았고 신경망을 전혀 다루지 않았기 때문에 OpenCL 이 있습니다. 코드의 모든 라인을 이해하지 않고는 이 코드나 저 코드를 사용할 수 없습니다. 모든 것을 알고 싶습니다. ))) 거래 프로그램의 엔진을 작업하는 동안. 머리가 핑핑 돌 정도로 할 일이 너무 많다. )))
In mathematics, the term chaos game, as coined by Michael Barnsley,1 originally referred to a method of creating a fractal, using a polygon and an initial point selected at random inside it.2 The fractal is created by iteratively creating a sequence of points, starting with the initial random point, in which each point in the sequence is a...
3층 16x7x3 뉴런을 만들었습니다. Sobsno는 어제 디버깅을 오늘 수행했습니다. 그 전에는 CPU를 확인할 때 결과가 수렴되지 않았습니다. 여기 에서 이유를 설명하지 않겠습니다(서사시가 매우 흥미롭고 유익하지만). 적어도 지금은 아닙니다. 저는 정말 자고 싶습니다. :)
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222 2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass 2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024 2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms 2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass 2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024 2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms 2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. 그건 그렇고, 주의: CPU 의 실행 시간 측면에서 당신의 시스템과 내 시스템(Pentium G840 기반)의 차이는 더 이상 크지 않습니다.
2. 당신은 빠른 RAM을 가지고 있습니까? 1333MHz가 있습니다.
1. 여가 시간에 오버클럭을 복원했습니다. 어떻게 든 내 차가 갑자기 멈췄습니다 (나중에 디스크의 전원 코드가 소켓에서 날아간 것으로 판명 됨). 그래서 기적을 찾기 위해 마더 보드의 "MemoryOK"버튼을 눌렀습니다. 그 후에도 여전히 작동하지 않고 모든 CMOS 매개변수만 기본 상태로 재설정되었습니다. 그리고 이제 다시 프로세서 주파수를 3840MHz로 따라잡았습니다. 이제 더 빠르게 작동합니다.
2. 나는 아직도 이해할 수 없다. :) BIOS는 1866Mhz를 보여주지만 어떤 테스트에서도 이를 확인하지 않습니다. 특히 레나트가 링크한 벤치마크는 1600MHz를 보여주고 있다. 그리고 Windows는 일반적으로 1033MHz를 보여줍니다. :))) 메모리 자체가 2GHz이고 어머니가 1866년까지 (공식적으로) 끌어온다는 사실에도 불구하고.
MetaDriver : 유일한 설명이 있습니다. 계산은 물론 사용 가능한 모든 코어와 벡터 SSE 명령을 사용하여 CPU-OpenCL에서 이루어집니다. :)
나는 의심한다. 특히 코어가 2개밖에 없기 때문에. 그렇다면 25배의 이익은 어디에서 오는가?
음, 전체 Intel Math Kernel Library 또는 Intel Performance Primitives(내가 다운로드하지 않음)가 고정 배선되어 있다면 여전히 가능합니다... 어떤 경우에는. 그러나 이것은 가능성이 희박합니다. 무게는 수백 메가입니다.
구글이 이에 대해 어떻게 말해야 하는지 지켜봐야 할 것이다.
Mathemat: 그리고 한 가지 더: CPU에서 계산할 때 두 코어가 모두 로드되어 있다는 것이 흥미롭습니다.
아니요, 저는 OpenCL이 없는 CPU의 순수한 컴퓨팅에 대해 이야기하고 있었습니다. 거기에서 부하는 100% 미만이며 각 코어에는 비슷한 부하 값이 있습니다. 그러나 OpenCL 코드를 실행하면 100%까지 늘어나는데, 이는 GPU 작업으로 정확하게 이해할 수 있습니다.
...
--
512를 수행하고 결과를 확인하십시오. 프로그램을 파쇄하는 것을 두려워하지 마십시오. 이것에서 더 많은 것이 될 것입니다. :) 하시면 여기에 올려주세요.
확인! 512개의 패스와 144,000개의 바:
글쎄, 60이 최선의 선택이라면 일반적으로 멋지다.
//---
즉, 이 스레드에서 제시된 가장 약한 랩톱에서 이것이 결과입니다. 그래서 매우 유망합니다.
//---
유감스럽게도 저는 아직 이 주제에 대해 자유롭게 이야기할 수 없습니다. 제가 joo 기사를 공부하지도 않았고 신경망을 전혀 다루지 않았기 때문에 OpenCL 이 있습니다. 코드의 모든 라인을 이해하지 않고는 이 코드나 저 코드를 사용할 수 없습니다. 모든 것을 알고 싶습니다. ))) 거래 프로그램의 엔진을 작업하는 동안. 머리가 핑핑 돌 정도로 할 일이 너무 많다. )))
CountBars를 30배(최대 4,320,000) 늘렸고, 하중에 대한 돌의 저항을 확인하기로 결정했습니다.
나는 모든 것을 신경 쓰지 않습니다. 쟁기질하고 가열되지만 땀을 많이 흘리지는 않습니다. 온도가 서서히 상승하고 있지만 이미 포화 상태에 도달했습니다.
빨간색 선은 온도이고 녹색 선은 코어의 부하입니다.
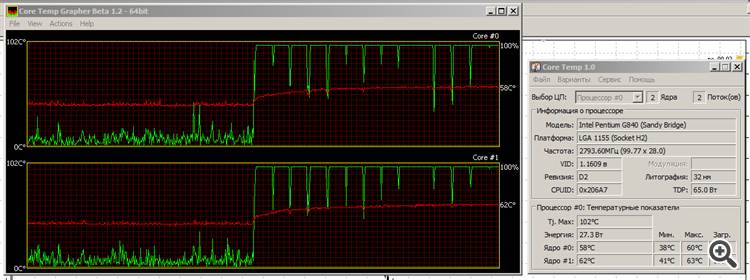
이것이 내가 Sandy Bridge Intel을 사랑하는 이유입니다. 그것은 녹색입니다. 네, 그래픽이 그렇게 핫하지는 않지만 아이비브릿지가 어떻게 될지 지켜보겠습니다......
이것이 내가 Sandy Bridge Intel을 사랑하는 이유입니다. 그것은 녹색입니다. 네, 그래픽이 그렇게 화끈하지는 않지만 아이비브릿지 가 어떻게 될지 지켜보겠습니다...오. 이것은 실제 스트레스 테스트입니다. :) 내 것은 아마 이미 구부러져있을 것입니다.
그러면 Haswell 과 Rockwell 은 나중에 어떻게 될까요? ...)))
OpenCL에서 Barnsley 펀의 구현 예.
계산은 Chaos Game 알고리즘( 예제 )에 따라 이루어지며 고유한 궤적을 생성하기 위해 난수 생성기가 get_global_id(0)에 의해 반환되는 스레드 ID에 의존하는 생성 기반과 함께 사용됩니다.
크기 조정 시 이미지 품질을 유지하는 데 필요한 포인트 수가 2차적으로 증가하므로 이 구현에서는 각 커널 인스턴스가 가시 영역에 속하는 고정된 수의 포인트를 그리는 것으로 가정합니다.
계산된 스레드 수는 191행에 지정됩니다.
포인트 수 - 233행:
UPD
IFS-fern.mq5 - CPU 아날로그
scale=1000일 때:
3층 16x7x3 뉴런을 만들었습니다. Sobsno는 어제 디버깅을 오늘 수행했습니다. 그 전에는 CPU를 확인할 때 결과가 수렴되지 않았습니다. 여기 에서 이유를 설명하지 않겠습니다(서사시가 매우 흥미롭고 유익하지만). 적어도 지금은 아닙니다. 저는 정말 자고 싶습니다. :)
시간적 특성:
내일 나는 이 그리드에 대한 Optimizer를 만들 것입니다. 그런 다음 실제 데이터를 로드하고 MT5 테스터에서 확인된 현실적인 계산에 맞게 테스터를 미세 조정하기 시작합니다. 그런 다음 자체 최적화를 위해 MLP 메시 생성기 + cl 코드를 다룰 것입니다.
나는 출처를 게시하지 않습니다 - 두꺼비. 그러나 ex5 트레일러에서 하드웨어를 테스트하려는 사람들을 위해.
푸틴과 마찬가지로 모든 것이 안정적입니다.
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
그건 그렇고,주의하십시오 : CPU 의 실행 시간 측면에서 귀하의 시스템과 내 시스템 (Pentium G840 기반)의 차이는 더 이상 크지 않습니다.
당신은 빠른 RAM을 가지고 있습니까? 1333MHz가 있습니다.
그리고 한 가지 더: CPU에서 계산할 때 두 코어가 모두 로드되어 있다는 것이 흥미롭습니다. 마지막에 부하가 급격히 감소합니다. 이는 계산이 끝난 후입니다. 그게 무슨 뜻이야?
푸틴과 마찬가지로 모든 것이 안정적입니다.
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CpuTime/GpuTime = 24.08037178786222
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Cpu МахResult==1.09311 at 771 pass
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:38:22 ParallelTester_00-02-j16x7x3z (EURUSD,H1) CPU time = 176172 ms
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Result on Gpu МахResult==1.09311 at 771 pass
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) Соunt inticators = 16; Count history bars = 144000; Count pass = 1024
2012.03.08 05:35:26 ParallelTester_00-02-j16x7x3z (EURUSD,H1) GPU time = 7316 ms
2012.03.08 05:35:18 ParallelTester_00-02-j16x7x3z (EURUSD,H1) OpenCL init OK!
1. 그건 그렇고, 주의: CPU 의 실행 시간 측면에서 당신의 시스템과 내 시스템(Pentium G840 기반)의 차이는 더 이상 크지 않습니다.
2. 당신은 빠른 RAM을 가지고 있습니까? 1333MHz가 있습니다.
1. 여가 시간에 오버클럭을 복원했습니다. 어떻게 든 내 차가 갑자기 멈췄습니다 (나중에 디스크의 전원 코드가 소켓에서 날아간 것으로 판명 됨). 그래서 기적을 찾기 위해 마더 보드의 "MemoryOK"버튼을 눌렀습니다. 그 후에도 여전히 작동하지 않고 모든 CMOS 매개변수만 기본 상태로 재설정되었습니다. 그리고 이제 다시 프로세서 주파수를 3840MHz로 따라잡았습니다. 이제 더 빠르게 작동합니다.
2. 나는 아직도 이해할 수 없다. :) BIOS는 1866Mhz를 보여주지만 어떤 테스트에서도 이를 확인하지 않습니다. 특히 레나트가 링크한 벤치마크는 1600MHz를 보여주고 있다. 그리고 Windows는 일반적으로 1033MHz를 보여줍니다. :))) 메모리 자체가 2GHz이고 어머니가 1866년까지 (공식적으로) 끌어온다는 사실에도 불구하고.
그리고 한 가지 더: CPU에서 계산할 때 두 코어가 모두 로드되어 있다는 것이 흥미롭습니다. 마지막에 부하가 급격히 감소합니다. 이는 계산이 끝난 후입니다. 그게 무슨 뜻이야?
그렇다면 GPU에 대해 전혀 생각하지 않을 수 있습니까? 드라이버가 일어 났지만 .. 설명이 하나뿐입니다. 계산은 CPU-OpenCL에서 발생하며 물론 사용 가능한 모든 코어와 벡터 SSE 명령을 사용하여 이루어집니다. :)
두 번째 옵션 - GPU와 CPU 모두에서 계산됩니다. 이(CPU-ZHPU) 지원이 드라이버에서 어떻게 제공되는지 모르겠지만 원칙적으로 OpenCL 처리를 시작하기 위한 이러한 옵션을 제외하지 않습니다.
그렇다면 이것은 내 추측입니다. 또는 지금 쓰는 것이 유행하는 방법 - "IMHO". ;)
나는 의심한다. 특히 코어가 2개밖에 없기 때문에. 그렇다면 25배의 이익은 어디에서 오는가?
음, 전체 Intel Math Kernel Library 또는 Intel Performance Primitives(내가 다운로드하지 않음)가 고정 배선되어 있다면 여전히 가능합니다... 어떤 경우에는. 그러나 이것은 가능성이 희박합니다. 무게는 수백 메가입니다.
구글이 이에 대해 어떻게 말해야 하는지 지켜봐야 할 것이다.
Mathemat: 그리고 한 가지 더: CPU에서 계산할 때 두 코어가 모두 로드되어 있다는 것이 흥미롭습니다.
아니요, 저는 OpenCL이 없는 CPU의 순수한 컴퓨팅에 대해 이야기하고 있었습니다. 거기에서 부하는 100% 미만이며 각 코어에는 비슷한 부하 값이 있습니다. 그러나 OpenCL 코드를 실행하면 100%까지 늘어나는데, 이는 GPU 작업으로 정확하게 이해할 수 있습니다.