記事"未知の確率密度関数のカーネル密度推定"についてのディスカッション
著者へ分布の密度ではなく、分布関数、つまり密度の積分を推定すると、さらに良い結果が得られます:まず、データ上でそれを構築するのがより簡単であり、それは常に非減少であり、0と1の間で境界を持つので、カーネル、スプライン、回帰など、平滑化アルゴリズムの選択に対する感度がはるかに低くなります。また、利用可能なデータ量に対する要件も減少し、桁が1つ減る。
密度は、必要に応じて数値微分によって簡単に求めることができます。
まあ、密度は必要なら数値微分で簡単に求めることができる。
たぶんね。それについては何も言えない。cdf を使ってpdf を評価しようともしていない。微分を使えばcdfの 推定精度を大幅に上げなければならないという偏見が働いたのだろう。加えて、cdf->pdf の方法を評価した論文や、他の方法と比較した論文にも出会っていません。もしリンクを共有していただけると ありがたい。
たぶんね。それについては何も言えない。cdf を使ってpdf を推定しようともしていない。おそらく、微分を使えばcdf 推定の精度を大幅に上げなければならないという偏見が働いたのだろう。加えて、cdf->pdf の方法を評価した論文や、他の方法と比較した論文にも出会っていません。もしリンクを共有していただけると ありがたいです。
私は参考文献を持っていないので、それを提供することはできません。その代わりに以下の考察を述べます。
pdfを直接評価する場合、定義域をあらかじめ区間に分割しておかなければならないが、2つの問題がある:1つ目は、区間をいくつに分割するのがよいのかわからないこと、2つ目は、どのようなグリッド(一様、...?そして、2つ目の疑問は、例えば分位分割を使うなどして何とか解決しようとする人がいるとしても、1つ目の疑問については、私の意見では、普遍的な方法はまったくない。
cdf推定にはこのような欠点がない。この場合、関数のステップは、入力データが該当する場所に正確に配置されるので、補間用のグリッドを選択する問題はそれ自体で消滅する。一旦グリッドが作成されれば、区間の数を選択することは難しいことではありません。我々はすでに 区間の最大数(とその位置!!)を知っているので、間引くことによって、必要な精度を任意に設定することができ、その都度、入力データの構造に最もマッチした自然なグリッドを使用することができます。
実際に、データサンプル数が100を超えない場合に、経験分布の局所モードを探索するためにこのテクニックを使ったことがあるが、非常に滑らかな結果が得られた。しかし、私は別の平滑化アルゴリズムを使っている。
すべて完璧にフェアだ。しかし、どうやらあなたが注意を払わなかったらしい一点を除けば、私にはそう見える。
カーネル・スムーザーのよく知られた表現は "Kernel smooth "である。
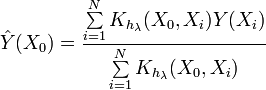
pdf を推定するためのこのようなスムージングに基づく方法は、次のようになります(単純化):
- 入力シーケンスを区間に分割します(クラスタリング,ビン化).
- 結果のヒストグラムを平滑化します。
カーネル・スムージングが好きでなければ,例えばp-スプラインを 使うことができます.(おそらく,すぐにp-spline を 選択する方がよいでしょう).
pdf 推定へのこのアプローチでは、あなたが言ったことはすべてまったく正しいことがわかります。しかし、この場合でさえも、大きな長さ(>1000000)のシーケンスに対するこの推定方法は、優れた結果を与えます。入力配列の長さが短くなるにつれて、あなたが言ったすべての魅力がますます強く現れ始める。
ではカーネル密度推定(KDE)の式を見てみよう。
![]()
この式は先ほどの式とは異なる。見ての通り、この式は与えられた点における確率密度 関数の値を直接決定する。そしてこの場合重要なのは、区間への分割がない ことである。入力シーケンスの値がそのまま使われる。
少なくとも、KDEでは このようになる。この記事で紹介されているpdf 推定アルゴリズムは、一見したところ、20~30要素の長さのシーケンスによく対応しています。時には平滑化の度合いを減らしたくなるかもしれません。コード中の
h=0.9*a/MathPow(N,0.2); // シルバーマンの経験則を
h=0.7*a/MathPow(N,0.2); // シルバーマンの経験則
もともとのアイデアは、外部ツールを一切使わないこと、つまり、すべてをMQL5ツールだけで実装することを前提としていた。
これは例外なくすべての自転車の発明者の考えである。
この点に関して、対応するパッケージが持っているものを見て、あなたが提供したものと比べてみてください-トレーディングに数学統計学と計量経済学を適用する際に必要なもののごくわずかな量です。
親愛なるアレックス、
あなたが高みの見物で推論するのは簡単です。しかし、次のことを考えてみてください:
このリソースは「www.mql5.com- Automated Trading and Testing of Trading Strategies」と呼ばれています。ご覧の ように 、このサイトはmql5と 呼ばれており、EViewsでもMQでも MT5でも ありません。したがって、このサイトがMQL5 プログラミング言語の普及、デバッグ、開発に主眼を置いていることは容易に推測できます。このことは、サービスデスクの存在やサイト上のMQL5 リファレンス情報の配置からも確認できる。
このサイトが例えば「取引戦略集」と呼ばれ、 MQに属して いなかったとしたら 。この場合、 Exel、 R、 EVievs、Gauss、 Stata などのソリューションを説明する出版物がそのようなサイトに掲載されると予想される。
もし私がこの記事をEViewsの サイトで発表していたら、あなたの非難の本質を理解しようとしたかもしれません。しかし、あなたも私も今はEViewsには いない。
このサイトには、まったく異なる背景を持つ人々が訪れている。年齢も違えば学歴も専門も違う。エコノメトリック・パッケージをほとんど、あるいはまったく使ったことのない人がほとんどだと思います。このような人たちをこのサイトから追放して、まずEViewsを 学ば せるべきだと 思いますか?
自費出版をされているのですから、このサイトに記事を掲載する手順もご存知のはずです。自費出版は不可能です。記事を投稿して検討されるだけです。サイトの運営者自身が、その一般的なコンセプトに適した記事を選びます。また、場合によっては、運営者自身が興味のあるテーマの記事を発注することもある。すでに申し上げたように、運営側には一般的なコンセプトがあり、あれこれ掲載依頼数の統計がある。このような状況で、記事のテーマについて私にクレームをつけるのは、ちょっとおかしいと思います。このような問題は、 MQの 代表者と話し合うべきでは ?
このサイトには、私にとって面白くない掲載記事があります。強調したいのは、悪い記事ではなく、私にとっては面白くないということだ。私は通常、そのような記事を読んだり、コメントを書いたりすることはない。あなたも同じような行動を取るべきかもしれない。アドバイスする勇気はないが、あなたがより快適に感じるようにすればいい。
アレックスへ
あなたが飛行の高さから推論するのは簡単です。しかし、次のことを考えてみてください:
このリソースは「www.mql5.com- Automated Trading and Testing of Trading Strategies」と呼ばれています。ご覧の ように 、このサイトはmql5と 呼ばれており、EViewsでもMQでも MT5でも ありません。したがって、このサイトがMQL5 プログラミング言語の普及、デバッグ、開発に主眼を置いていることは容易に推測できます。このことは、サービスデスクの存在やサイト上のMQL5 リファレンス情報の配置からも確認できる。
このサイトが例えば「取引戦略集」と呼ばれ、 MQに属して いなかったとしたら 。この場合、 Exel、 R、 EVievs、Gauss、 Stata などのソリューションを説明する出版物がそのようなサイトに掲載されると予想される。
もし私がこの記事をEViewsの サイトで発表していたら、あなたの非難の本質を理解しようとしたかもしれません。しかし、あなたも私も今はEViewsには いない。
このサイトには、まったく異なる背景を持つ人々が訪れている。年齢も違えば学歴も専門も違う。エコノメトリック・パッケージをほとんど、あるいはまったく使ったことのない人がほとんどだと思います。このような人たちをこのサイトから追放して、まずEViewsを 学ば せるべきだと 思いますか?
自費出版をされているのですから、このサイトに記事を掲載する手順もご存知のはずです。自費出版は不可能です。記事を投稿して検討されるだけです。サイトの運営者自身が、その一般的なコンセプトに適した記事を選びます。また、場合によっては、運営者自身が興味のあるテーマの記事を発注することもある。すでに申し上げたように、運営側には一般的なコンセプトがあり、あれこれ掲載依頼数の統計がある。このような状況で、記事のテーマについて私にクレームをつけるのは、ちょっとおかしいと思います。このような問題は、 MQの 代表者と話し合うべきでは ?
このサイトには、私にとって面白くない掲載記事があります。強調したいのは、悪い記事ではなく、私にとっては面白くないということだ。私は通常、そのような記事を読んだり、コメントを書いたりすることはない。あなたも同じような行動を取るべきかもしれない。アドバイスする勇気はないが、あなたがより快適に感じるようにすればいい。
あなたの回答は、私の投稿の本質をまったく踏まえていないので、受け入れられない。私の見解を説明しよう。
1.Metaquotesは全く関係ない。彼らは非常にまともなツールを提供し、それを実行している。
2.記事のトピックに制限があることは承知していない。もちろん、取引の範囲内で。このサイトには "統計 "というセクションがあります。つまり、彼らはトレーディングの内容や問題に完全に準拠して、あなたよりもはるかに広くサイトのテーマを理解しています。Metaquotesに言及するのはやめて、本題に移ろう。
3. 私の投稿は、何を開発するかではなく、どのように開発するかについてです。私にとっては、これがあなたの記事との関連で基本的なことです。私はEViewsのキャンペーンをしたわけではありません。EViewsはデモやトレーニングの目的には適していますが、それでトレードできるとは思いません。私のリンクは、問題の幅を示すためのパッケージです。
4.私は長い間プログラミングをやってきた。40年前、最初のプログラムライブラリが登場し、すぐに、アマチュアが既存のパッケージから何かのプログラムを書き直すことを批判した。あなたが最初ではない。しかし、このサイトは、自転車を再び組み立てるのが好きなアマチュアでいっぱいだ--それゆえ、私の肥大化した反応なのだ。
5.核評価の問題は咀嚼され、噛み砕かれた問題だ。そして、もしあなたが他の人のライブラリーを取ったとしたら、自分の論文で解決した技術的な難題を乗り越えて、おそらく練習生のalsuが提起した問題に対する解決策を提示したり、分布の視覚的評価がその正式な評価において非常に重要な役割を果たしていることを思い出したり、機能的に拡大したりする機会があるでしょう。- いずれにせよ、あなたは一段高いところにいることになる。
私はあなたに対して攻撃的な表現をするつもりは毛頭ありません。あなたの記事や開発には敬意を表しますが、あなたのアイデアを実現する 手法の方法論的な焦点には同意できません。
あなたの記事に対する私の投稿は、誰かが統計学や計量経済学の手段を用いてメタコット端末を体系的に補足してくれることを期待してのものである。そのような人々を紹介しよう。
非常に興味深い。非常に興味深い。
リクエストは受け付けていますか?
オープンソースのコードに限らず、統計指向のコードが望ましい。Rに注目してください。
非常に興味深い。非常に興味深い。
リクエストは受け付けていますか?
オープンソースに限らず、統計に特化したコードが望ましいです。Rに注目してください。
https://www.mql5.com/ru/forum/6505。 何でも書いてください。:)
- www.mql5.com
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 未知の確率密度関数のカーネル密度推定 はパブリッシュされました:
本稿では、未知の確率密度関数のカーネル密度推定を可能にするプログラム作成に取り組みます。そしてタスク実行のためにカーネル密度推定法を選択しました。本稿にはメソッドのソフトウェア実装コード、その使用例、説明が述べられています。
作者: Victor