記事「ニューラルネットワークが簡単に(第45回):状態探索スキルの訓練」についてのディスカッション
プロセッサはOpenCLをサポートしているが、ビデオカードはサポートしていないため、テストも最適化も始まらない......。
こんにちは、オレグ。
この実装はOpenCLでのみ動作します。これを無効にするには、ネットワークアルゴリズム全体を再設計する必要があります。しかし、プロセッサがOpenCLをサポートしており、対応するドライバがインストールされていれば、プロセッサ上で実行することができます。
こんにちは、オレグ。
この実装はOpenCLでのみ動作します。これを無効にするには、ネットワーク・アルゴリズム全体を再設計する必要があります。しかし、プロセッサがOpenCLをサポートしており、対応するドライバがインストールされていれば、プロセッサ上で実行することができます。
これが私が受け取ったエラーです(スクリーンショット参照)。スクリーンショットでは、ビデオカードがOpenCLをサポートしていないことがわかりますが、プロセッサは問題ありません。これを回避して、テスターやオプティマイザーで実行するにはどうしたらいいでしょうか?何かアドバイスはありますか?

これは私が受け取ったエラーです(スクリーンショットを参照)。スクリーンショットは、ビデオカードがOpenCLをサポートしていないことを示していますが、プロセッサは正常です。これを回避して、テスターやオプティマイザーで実行するにはどうしたらいいでしょうか?何かアドバイスはありますか?
問題なのは、"tester.ex5 "を実行していることです。これは学習済みモデルの品質をチェックするもので、あなたはまだ学習済みモデルを持っていません。まず、Research.mq5を実行して例のデータベースを作成 する必要があります。次にStudyModel.mq5を実行し、オートエンコーダをトレーニングします。俳優の訓練はStudyActor.mq5またはStudyActor2.mq5で行います(報酬関数は異なります)。そしてtester.ex5が動作します。後者のパラメータでは、アクターモデル Act または Act2 を指定する必要があることに注意してください。StudyActorに使用するExpert Advisorによって異なります。
問題は "tester.ex5 "を実行することです。 これは学習済みモデルの品質をチェックするものですが、あなたはまだそのモデルを持っていません。まず、Research.mq5を実行して例のデータベースを作成 する必要がある。次にStudyModel.mq5を実行し、オートエンコーダをトレーニングします。俳優の訓練はStudyActor.mq5またはStudyActor2.mq5で行います(報酬関数は異なります)。そしてtester.ex5が動作します。後者のパラメータでは、アクターモデル Act または Act2 を指定する必要があることに注意してください。StudyActorに使用するExpert Advisorによって異なります。
Researchの 最適化を開始。
その結果、ログに次のように書き込まれる:
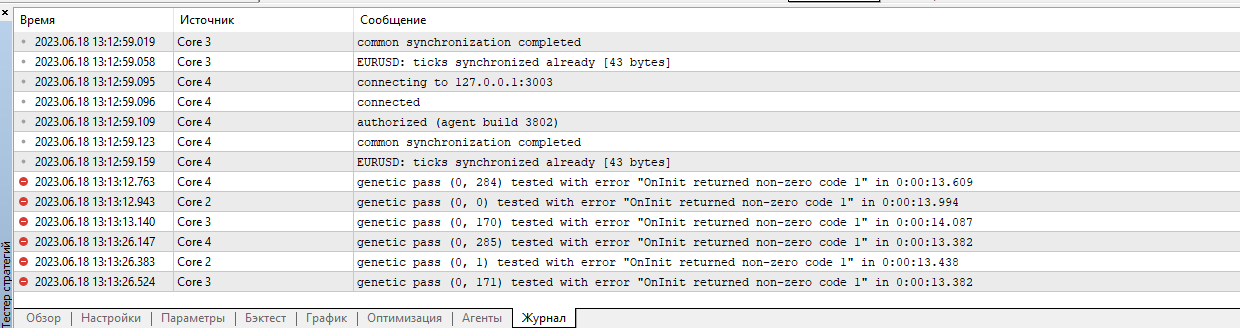
また何か間違っているのでしょうか?

全てのテスターログをクリアし、EURUSD H1で2023年の最初の4ヶ月間Research optimisationを実行しました。
実際のティックで実行しました:
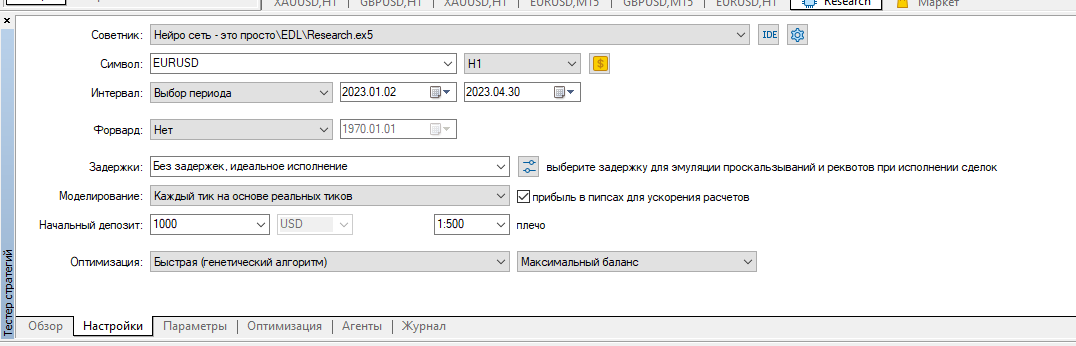
結果:たった4つのサンプル、プラスが2つ、マイナスが2つ:

多分、私が何か間違ったことをしているか、間違ったパラメータを最適化しているか、私のターミナルが何か間違っているのでしょうか?よくわかりません。記事にあるような結果を繰り返そうとしているのですが...。
エラーは最初から始まっています。
最適化のセットと結果、エージェントとテスターのログをResearch.zipアーカイブに添付します。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「ニューラルネットワークが簡単に(第45回):状態探索スキルの訓練」はパブリッシュされました:
明示的な報酬関数なしに有用なスキルを訓練することは、階層的強化学習における主な課題の1つです。前回までに、この問題を解くための2つのアルゴリズムを紹介しましたが、環境調査の完全性についての疑問は残されています。この記事では、スキル訓練に対する異なるアプローチを示します。その使用は、システムの現在の状態に直接依存します。
最初の結果は予想以上に悪くなりました。好結果では、テストサンプルで使用されたスキルの分布がかなり均一です。テストの好結果はここで終わりました。オートエンコーダとエージェントの訓練を何度も繰り返しましたが、訓練セットで利益を生み出すモデルを得ることはできませんでした。どうやら、オートエンコーダが十分な精度で状態を予測できないことが問題だったようです。その結果、残高の曲線は望ましい結果からはほど遠いものとなってしまいました。
この仮定を検証するために、代替エージェント訓練EA EDLStudyActor2.mq5を作成しました。代替オプションと、以前に検討されたオプションの唯一の違いは、報酬を生成するアルゴリズムです。また、このサイクルを使って口座状況の変化を予測しました。今回は、報酬として相対的残高変化指標を使用した。
修正された報酬関数を用いて訓練されたエージェントは、テスト期間中、収益性の上昇がほぼ横ばいでした。
作者: Dmitriy Gizlyk