
Approccio econometrico all'analisi dei grafici

Le teorie senza i fatti possono essere sterili, ma i fatti senza teorie sono prive di significato.
K. Boulding
Introduzione
Sento spesso dire che i mercati sono volatili e non c'è stabilità. E questo spiega perché un trading di successo a lungo termine sia impossibile. Ma è vero? Proviamo ad analizzare questo problema scientificamente. E scegliamo i mezzi dell’analisi econometrica. Perché loro? Prima di tutto, la comunità MQL ama la precisione, che sarà fornita dalla matematica e dalla statistica. In secondo luogo, questo argomento non è ancora stato descritto, se non sbaglio.
Permettetemi di ricordare che il problema del trading a lungo termine di successo non può essere risolto all'interno di un singolo articolo. Oggi descriverò solo i diversi metodi di diagnostica per il modello selezionato, che si spera appaiano preziosi per un uso futuro.
Oltre a questo, farò del mio meglio per descrivere in modo chiaro alcuni materiali tra cui formule, teoremi e ipotesi. Tuttavia, mi aspetto che il mio lettore conosca i concetti di base della statistica, come: ipotesi, significatività statistica, statistica (criterio statistico), dispersione, distribuzione, probabilità, regressione, autocorrelazione, ecc.
1. Caratteristiche di una serie temporale
È ovvio che l'oggetto dell'analisi è una serie di prezzi (i suoi derivati), che è una serie temporale .
Gli econometristi studiano le serie temporali dal punto di frequenza ai metodi (analisi dello spettro, analisi wavelet) e ai metodi del dominio del tempo (analisi di correlazione incrociata, analisi di autocorrelazione). Al lettore è già stato fornito l'articolo "Building Spectrum Analysis" che descrive i metodi di frequenza. Ora suggerisco di dare un'occhiata ai metodi del dominio del tempo, all'analisi dell'autocorrelazione e all'analisi della varianza condizionale in particolare.
I modelli non lineari descrivono il comportamento delle serie temporali dei prezzi in modo migliore rispetto a quelli lineari. Ecco perché in questo articolo ci concentriamo sullo studio di modelli non lineari.
Le serie temporali dei prezzi hanno caratteristiche speciali che possono essere prese in considerazione solo da alcuni modelli econometrici. Prima di tutto, tali caratteristiche includono: "fat tail", clusterizzazione della volatilità ed effetto leva.

Figura 1. Distribuzioni con curtosi diverse.
La fig. 1 mostra 3 distribuzioni con curtosi diverse (picco). La distribuzione, che ha un picco inferiore alla distribuzione normale, presenta "fat tails"più spesso delle altre. È mostrata in rosa.
Abbiamo bisogno di una distribuzione per mostrare la densità di probabilità di un valore casuale, che viene utilizzato per il conteggio dei valori della serie studiata.
Per clusterizzazione (da cluster: gruppo, concentrazione) di volatilità intendiamo quanto segue. Un periodo di tempo di alta volatilità è seguito dallo stesso e un periodo di tempo di bassa volatilità è seguito da quello identico. Se i prezzi fluttuavano ieri, molto probabilmente lo faranno anche oggi. Quindi c'è inerzia della volatilità. La fig. 2 dimostra che la volatilità ha una forma a cluster.

Figura 2. Volatilità dei rendimenti giornalieri di USDJPY, la sua clusterizzazione.
L'effetto leva consiste nella volatilità di un mercato in calo superiore a quella di un mercato in rialzo. È stipulato dall'aumento del coefficiente di leva finanziaria, che dipende dal rapporto tra attività prese in prestito e proprie quando i prezzi delle azioni scendono. Tuttavia, questo effetto si applica al mercato azionario e non al mercato dei cambi. Questo effetto non sarà discusso ulteriormente.
2. Il modello GARCH
Quindi, il nostro obiettivo principale è quello di prevedere il tasso di cambio (prezzo) utilizzando un modello. Gli econometristi usano modelli matematici che descrivono l'uno o l'altro effetto che può essere stimato in termini di quantità. In parole semplici, adattano una formula a un evento. E in questo modo descrivono quell'evento.
Considerando che la serie temporale analizzata ha le proprietà sopra menzionate, un modello ottimale che consideri queste proprietà sarà non lineare. Uno dei modelli non lineari più universali è il modello GARCH . Come può aiutarci? Al suo interno(funzione), prenderà in considerazione la volatilità della serie, cioè la variabilità della dispersione nei diversi periodi di osservazione. Gli econometristi chiamano questo effetto con un termine astruso, eteroschedasticità (dal greco hetero, cioè diverso, e skedasis, ovvero dispersione).
Se diamo un'occhiata alla formula stessa, vedremo che questo modello implica che l'attuale variabilità della dispersione (σ2t) è influenzata sia da precedenti cambiamenti di parametri (ε2t-i) che da precedenti stime di dispersione (le cosiddette «vecchie notizie»)(σ2t-i):
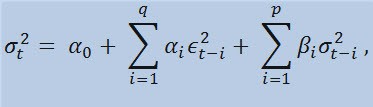
con limiti
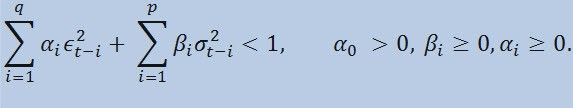
dove: εt - innovazioni non standardizzate;α0, βi, αi , q (ordine dei membri ARCH ε2), p(ordine dei membri GARCH σ 2) - parametri stimati e l’ordine dei modelli.
3. Indicatore dei rendimenti
In realtà, non stimeremo la serie dei prezzi in sé, ma la serie dei rendimenti. Il logaritmo della variazione di prezzo (rendimenti costantemente addebitati) è determinato come un logaritmo naturale della percentuale di rendimento:
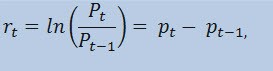
dove:
- Pt - è il valore della serie di prezzi al momento t;
- Pt-1 - è il valore della serie di prezzi al momento t-1;
- pt = ln(Pt) - è il logaritmo naturale Pt.
In pratica, il motivo principale per cui lavorare con i rendimenti è più preferibile che lavorare con i prezzi è che i rendimenti hanno caratteristiche statistiche migliori.
Quindi, creiamo un indicatore dei rendimenti ReturnsIndicator.mq5 che ci sarà molto utile. Qui, farò riferimento all'articolo "Custom Indicators for Newbies", che descrive comprensibilmente l'algoritmo di creazione di un indicatore. Ecco perché ti mostrerò solo il codice in cui è implementata la formula menzionata. Penso che sia molto semplice e non richiede spiegazioni.
//+------------------------------------------------------------------+ //| Custom indicator iteration function | //+------------------------------------------------------------------+ int OnCalculate(const int rates_total, // size of the array price[] const int prev_calculated, // number of bars available at the previous call const int begin, // index of the array price[] the reliable data starts from const double& price[]) // array for the calculation itself { //--- int start; if(prev_calculated<2) start=1; // start filling ReturnsBuffer[] from the 1-st index, not 0. else start=prev_calculated-1; // set 'start' equal to the last index in the arrays for(int i=start;i<rates_total;i++) { ReturnsBuffer[i]=MathLog(price[i]/price[i-1]); } //--- return value of prev_calculated for next call return(rates_total); } //+------------------------------------------------------------------+
L'unica cosa che voglio menzionare è che la serie dei rendimenti è sempre più piccola della serie primaria di un elemento. Ecco perché calcoleremo l’array dei rendimenti a partire dal secondo elemento e il primo sarà sempre uguale a 0.
Pertanto, utilizzando ReturnsIndicator l'indicatore abbiamo ottenuto una serie temporale casuale che verrà utilizzata per i nostri studi.
4. Test statistici
Adesso è il turno dei test statistici. Sono condotti per determinare se la serie temporale presenta segni che dimostrano l'idoneità dell'utilizzo dell'uno o dell'altro modello. Nel nostro caso, tale modello è il modello GARCH.
Usando il Q-test, controlla se le autocorrelazioni della serie sono casuali o se esiste una relazione. A tale scopo, dobbiamo scrivere una nuova funzione. Qui, per autocorrelazione intendo una correlazione (connessione probabilistica) tra i valori della stessa serie temporale X (t) ai momenti temporali t1 e t2. Se i momenti t1 e t2 sono adiacenti (uno segue l'altro), allora cerchiamo una relazione tra i membri della serie e i membri della stessa serie spostati di un'unità temporale: x1, x2, x3, ... и x1+1, x2+1, x3+1, ... Tale effetto di spostamento dei membri è chiamato lag (latenza, ritardo). Il valore di lag può essere qualsiasi numero positivo.
Ora farò un'osservazione tra parentesi e ti parlerò di quanto segue. Per quanto ne so, né С ++, né MQL5 hanno librerie standard che coprono calcoli statistici complessi e medi. Di solito, tali calcoli vengono eseguiti utilizzando speciali strumenti statistici. Per quanto mi riguarda, è più facile utilizzare strumenti come Matlab, STATISTICA 9, ecc. per risolvere il problema. Tuttavia, ho deciso di rifiutare l'uso di librerie esterne in primo luogo per dimostrare quanto sia potente il linguaggio MQL5 per i calcoli, e in secondo luogo ... ho imparato molto quando ho scritto il codice MQL.
Ora dobbiamo puntualizzare questa nota. Per condurre il test Q, abbiamo bisogno di numeri complessi. Ecco perché ho creato la classe Complex. Idealmente, dovrebbe essere chiamata CComplex. Bene, mi sono permesso di rilassarmi per un po'. Sono sicuro che il mio lettore è preparato e quindi non ho bisogno di spiegare cos'è un numero complesso. Personalmente, non mi piacciono le funzioni che calcolano la trasformazione di Fourier pubblicate in MQL5 e MQL4; i numeri complessi sono usati lì in modo implicito. Inoltre, c'è un altro ostacolo: l'impossibilità di ignorare gli operatori aritmetici in MQL5. Quindi ho dovuto cercare altri approcci ed evitare la notazione "C" standard. Ho implementato la classe di numero complesso nel modo seguente:
class Complex { public: double re,im; //re -real component of the complex number, im - imaginary public: void Complex(){}; //default constructor void setComplex(double rE,double iM){re=rE; im=iM;}; //set method (1-st variant) void setComplex(double rE){re=rE; im=0;}; //set method (2-nd variant) void ~Complex(){}; //destructor void opEqual(const Complex &y){re=y.re;im=y.im;}; //operator= void opPlus(const Complex &x,const Complex &y); //operator+ void opPlusEq(const Complex &y); //operator+= void opMinus(const Complex &x,const Complex &y); //operator- void opMult(const Complex &x,const Complex &y); //operator* void opMultEq(const Complex &y); //operator*= (1-st variant) void opMultEq(const double y); //operator*= (2-nd variant) void conjugate(const Complex &y); //conjugation of complex numbers double norm(); //normalization };
Ad esempio, la somma di due numeri complessi può essere eseguita utilizzando il metodo opPlus, la sottrazione viene eseguita utilizzando opMinus, ecc. Se scrivi solo il codice c = a + b (dove a, b, с sono numeri complessi), il compilatore visualizzerà un errore. Ma accetterà la seguente espressione: c.opPlus(a,b)
Se necessario, un utente può estendere il set di metodi della classe Complex. Ad esempio, è possibile aggiungere un operatore di divisione.
Inoltre, ho bisogno di funzioni ausiliarie che elaborano matrici di numeri complessi. Ecco perché li ho implementati al di fuori della classe Complex non per ripetere ciclicamente l'elaborazione degli elementi di array in essa, ma per lavorare direttamente con gli array passati da un riferimento. Ci sono tre di queste funzioni in totale:
- getComplexArr (restituisce un array bidimensionale di numeri reali da un array di numeri complessi);
- setComplexArr (restituisce un array di numeri complessi da un array unidimensionale di numeri reali);
- setComplexArr2 (restituisce un array di numeri complessi da un array bidimensionale di numeri reali).
Va notato che queste funzioni restituiscono matrici passate da un riferimento. Ecco perché i loro corpi non contengono l'operatore di "return". Ma ragionando logicamente, penso che possiamo parlare del ritorno nonostante il tipo nullo.
La classe dei numeri complessi e delle funzioni ausiliarie è descritta nel file di intestazione Complex_class.mqh.
Quindi, quando conduciamo i test, avremo bisogno della funzione di autocorrelazione e della funzione di trasformazione di Fourier. Quindi, abbiamo bisogno di creare una nuova classe. Chiamiamola CFFT. Elaborerà array di numeri complessi per le trasformazioni di Fourier. La classe Fourier è simile alla seguente:
class CFFT { public: Complex Input[]; //input array of complex numbers Complex Output[]; //output array of complex numbers public: bool Forward(const uint N); //direct Fourier transformation bool InverseT(const uint N,const bool Scale=true); //weighted reverse Fourier transformation bool InverseF(const uint N,const bool Scale=false); //non-weighted reverse Fourier transformation void setCFFT(Complex &data1[],Complex &data2[],const uint N); //set method(1-st variant) void setCFFT(Complex &data1[],Complex &data2[]); //set method (2-nd variant) protected: void Rearrange(const uint N); // regrouping void Perform(const uint N,const bool Inverse); // implementation of transformation void Scale(const uint N); // weighting };
Va notato che tutte le trasformazioni di Fourier vengono eseguite con array la cui lunghezza è conforme alla condizione 2^N (dove N è una potenza di due). Di solito la lunghezza dell'array non è uguale a 2^N. In questo caso, la lunghezza dell’array viene aumentata al valore di 2^N per 2^N >= n, dove n è la lunghezza dell’array. Gli elementi aggiunti dell’array sono uguali a 0. Tale elaborazione dell'array viene eseguita all'interno del corpo della funzione autocorr utilizzando la funzione ausiliaria nextpow2 e la funzione pow:
int nFFT=pow(2,nextpow2(ArraySize(res))+1); //power rate of two
Quindi, se abbiamo un array iniziale la cui lunghezza (n) è uguale a 73585, allora la funzione nextpow2 restituirà il valore 17, dove 2^17 = 131072. In altre parole, il valore restituito è maggiore di n per pow(2, ceil(log(n)/log(2))). Quindi calcoleremo il valore di nFFT: 2^(17+1) = 262144. Questa sarà la lunghezza dell'array ausiliario, i cui elementi da 73585 a 262143 saranno uguali a zero.
La classe Fourier è descritta nel file di intestazione FFT_class.mqh.
Per risparmiare spazio, salterò la descrizione dell'implementazione della classe CFFT. Quelli che sono interessati possono controllarli nel file allegato. Passiamo ora alla funzione di autocorrelazione.
void autocorr(double &ACF[],double &res[],int nLags) //1-st variant of function /* selective autocorrelation function (ACF) for unidimensional stochastic time series ACF - output array of calculated values of the autocorrelation function; res - array of observation of stochastic time series; nLags - maximum number of lags the ACF is calculated for. */ { Complex Data1[],Data21[], //input arrays of complex numbers Data2[],Data22[], //output arrays of complex numbers cData[]; //array of conjugated complex numbers double rA[][2]; //auxiliary two-dimensional array of real numbers int nFFT=pow(2,nextpow2(ArraySize(res))+1); //power rate of two ArrayResize(rA,nFFT);ArrayResize(Data1,nFFT); //correction of array sizes ArrayResize(Data2,nFFT);ArrayResize(Data21,nFFT); ArrayResize(Data22,nFFT);ArrayResize(cData,nFFT); double rets1[]; //an auxiliary array for observing the series double m=mean(res); //arithmetical mean of the array res ArrayResize(rets1,nFFT); //correction of array size for(int t=0;t<ArraySize(res);t++) //copy the initial array of observation // to the auxiliary one with correction by average rets1[t]=res[t]-m; setComplexArr(Data1,rets1); //set input array of complex numbers CFFT F,F1; //initialize instances of the CFFT class F.setCFFT(Data1,Data2); //initialize data-members for the instance F F.Forward(nFFT); //perform direct Fourier transformation for(int i=0;i<nFFT;i++) { Data21[i].opEqual(F.Output[i]);//assign the values of the F.Output array to the Data21 array; cData[i].conjugate(Data21[i]); //perform conjugation for the array Data21 Data21[i].opMultEq(cData[i]); //multiplication of the complex number by the one adjacent to it //results in a complex number that has only real component not equal to zero } F1.setCFFT(Data21,Data22); //initialize data-members for the instance F1 F1.InverseT(nFFT); //perform weighter reverse Fourier transformation getComplexArr(rA,F1.Output); //get the result in double format after //weighted reverse Fourier transformation for(int i=0;i<nLags+1;i++) { ACF[i]=rA[i][0]; //in the output ACF array save the calculated values //of autocorrelation function ACF[i]=ACF[i]/rA[0][0]; //normalization relatively to the first element } }
Quindi abbiamo calcolato i valori ACF per il numero specificato di lag. Ora possiamo usare la funzione di autocorrelazione per il test Q. La stessa funzione di test è simile alla seguente:
void lbqtest(bool &H[],double &rets[]) /* Function that implements the Q test of Ljung-Box-Pierce H - output array of logic values, that confirm or disprove the zero hypothesis on the specified lag; rets - array of observations of the stochastic time series; */ { double lags[3]={10.0,15.0,20.0}; //specified lags int maxLags=20; //maximum number of lags double ACF[]; ArrayResize(ACF,21); //epmty ACF array double acf[]; ArrayResize(acf,20); //alternate ACF array autocorr(ACF,rets,maxLags); //calculated ACF array for(int i=0;i<20;i++) acf[i]=ACF[i+1]; //remove the first element - one, fill //alternate array double alpha[3]={0.05,0.05,0.05}; //array of levels of significance of the test /*Calculation of array of Q statistics for selected lags according to the formula: L |----| \ Q = T(T+2) || (rho(k)^2/(T-k)), / |----| k=1 where: T is range, L is the number of lags, rho(k) is the value of ACF at the k-th lag. */ double idx[]; ArrayResize(idx,maxLags); //auxiliary array of indexes int len=ArraySize(rets); //length of the array of observations int arrLags[];ArrayResize(arrLags,maxLags); //auxiliary array of lags double stat[]; ArrayResize(stat,maxLags); //array of Q statistics double sum[]; ArrayResize(sum,maxLags); //auxiliary array po sums double iACF[];ArrayResize(iACF,maxLags); //auxiliary ACF array for(int i=0;i<maxLags;i++) { //fill: arrLags[i]=i+1; //auxiliary array of lags idx[i]=len-arrLags[i]; //auxiliary array of indexes iACF[i]=pow(acf[i],2)/idx[i]; //auxiliary ACF array } cumsum(sum,iACF); //sum the auxiliary ACF array //by progressive total for(int i=0;i<maxLags;i++) stat[i]=sum[i]*len*(len+2); //fill the array Q statistics double stat1[]; //alternate of the array of Q statistics ArrayResize(stat1,ArraySize(lags)); for(int i=0;i<ArraySize(lags);i++) stat1[i]=stat[lags[i]-1]; //fill the alternate array of specified lags double pValue[ArraySize(lags)]; //array of 'p' values for(int i=0;i<ArraySize(lags);i++) { pValue[i]=1-gammp(lags[i]/2,stat1[i]/2); //calculation of 'p' values H[i]=alpha[i]>=pValue[i]; //estimation of zero hypothesis } }
Pertanto, la nostra funzione esegue il test Q di Ljung-Box-Pierce e restituisce l’array di valori logici per i lag specificati. Dobbiamo chiarire che il test di Ljung-Box è il cosiddetto test portmanteau ( test combinato). Significa che un certo gruppo di lag fino a un ritardo specificato viene controllato per la presenza di autocorrelazione. Di solito, l'autocorrelazione viene controllata fino al 10^, 15^ e 20^ lag, inclusi. Una conclusione sulla presenza di autocorrelazione nell'intera serie è fatta sulla base dell'ultimo valore dell'elemento dell'array H, cioè dal 1^ lag al 20^.
Se l'elemento dell’array è uguale a false, allora l'ipotesi zero, che afferma che non vi è alcuna autocorrelazione sui ritardi precedenti e selezionati, non viene rifiutata. In altre parole, non è un'autocorrelazione quando il valore è false. Altrimenti, il test dimostra la presenza dell'autocorrelazione. Pertanto, un'ipotesi alternativa a zero viene accettata quando il valore è true.
A volte capita che le autocorrelazioni non si trovino in serie di rendimenti. In questo caso, per una maggiore sicurezza vengono testati i quadrati dei rendimenti. La decisione finale sull'accettazione o il rifiuto dell'ipotesi zero viene presa nello stesso modo in cui si testa la serie iniziale di rendimenti. Perché dovremmo usare i quadrati dei rendimenti? In questo modo, aumentiamo artificialmente la possibile componente di autocorrelazione non random della serie analizzata, che viene ulteriormente determinata entro i limiti dei valori iniziali dei limiti attendibili. Teoricamente puoi usare quadrati e altre potenze di rendimento. Ma è un carico statistico non necessario, che cancella il significato di test.
Alla fine del corpo della funzione di test Q, quando viene calcolato il valore 'p', è apparsa la funzione gammp(x1/2,x2/2). Permette di calcolare la funzione gamma incompleta per gli elementi corrispondenti. In realtà, abbiamo bisogno di una funzione distribuzione χ2 (chi-square-distribution). Ma è un caso particolare di gamma di distribuzione.
Generalmente, per dimostrare l'idoneità all'uso del modello GARCH è sufficiente ottenere un valore positivo di uno qualsiasi dei ritardi del test Q. Oltre ad esso, gli econometristi conducono un altro test: il test ARCH di Engle, che verifica la presenza di un'eteroschedasticità convenzionale. Tuttavia, suppongo che il test Q sia sufficiente per il momento. È il più universale.
Ora, poiché abbiamo tutte le funzioni necessarie per condurre il test, dobbiamo pensare a visualizzare i risultati ottenuti sullo schermo. A questo scopo, ho scritto un'altra funzione lbqtestInfo che visualizza il risultato del test econometrico sotto forma di una finestra di messaggio e il diagramma di autocorrelazione, proprio sul grafico del simbolo analizzato.
Vediamo il risultato con un esempio. Ho scelto usdjpy come primo simbolo per l'analisi. All'inizio, apro il grafico a linee del simbolo (per prezzi di chiusura) e carico l'indicatore personalizzato ReturnsIndicator per dimostrare la serie di rendimenti. Il grafico è contratto al massimo per visualizzare meglio la clusterizzazione della volatilità dell'indicatore. Quindi eseguo lo script GarchTest. Probabilmente, la risoluzione dello schermo è diversa dalla mia, cioè lo script ti chiederà la dimensione desiderata del diagramma in pixel. Il mio standard è 700*250.
Diversi esempi di test sono mostrati nella fig.3.
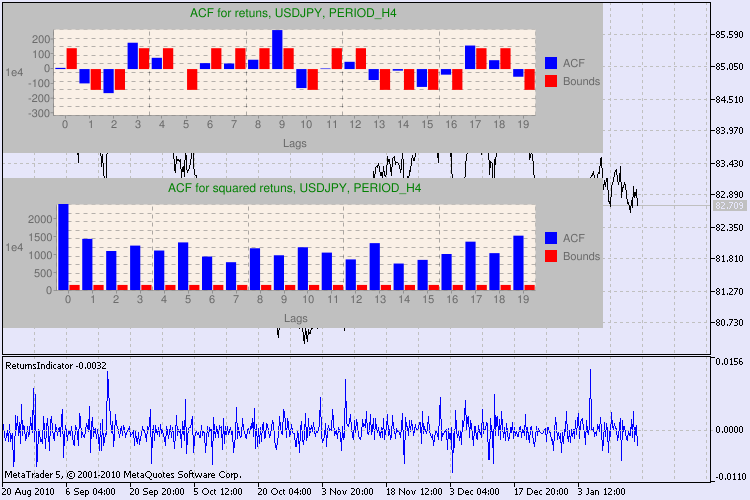
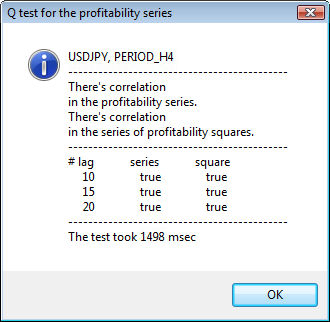
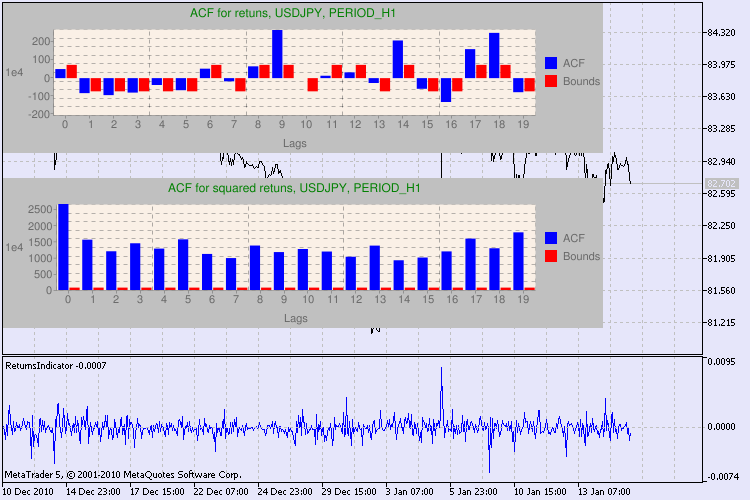
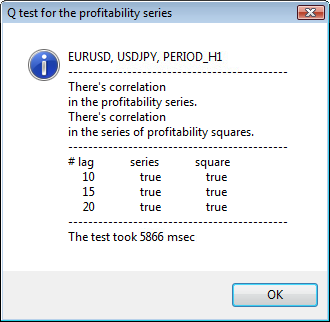
Figura 3. Il risultato del test Q e il diagramma di autocorrelazione per USDJPY per diversi intervalli di tempo.
Sì, ho cercato a lungo una variante della visualizzazione del diagramma su un grafico a simboli su MetaTrader 5. E ho deciso che la variante ottimale è quella di utilizzare una libreria di diagrammi di disegno utilizzando Google Chart API, che è descritto nell'articolo corrispondente.
Come dovremmo interpretare queste informazioni? Diamo un'occhiata. La parte superiore del grafico contiene il diagramma della funzione di autocorrelazione (ACF) per la serie iniziale di rendimenti. Al primo diagramma analizziamo la serie di usdjpy dell’intervallo di tempo H4. Possiamo vedere che diversi valori di ACF (barre blu) superano i limiti (barre rosse). In altre parole, vediamo una piccola autocorrelazione nella serie iniziale di rendimenti. Il diagramma seguente è il diagramma della funzione di autocorrelazione (ACF) della serie di quadrati di rendimenti del simbolo specificato. Tutto è chiaro lì, una vittoria completa delle barre blu. I diagrammi H1 vengono analizzati allo stesso modo.
Alcune parole sulla descrizione degli assi del diagramma. L'asse x è chiaro; visualizza gli indici dei lag. Sull'asse y è possibile vedere il valore esponenziale, il valore iniziale di ACF per cui viene moltiplicato. Quindi, 1e4 significa che il valore iniziale viene moltiplicato per 1e4 (1e4 = 10000) e 1e2 significa moltiplicare per 100, ecc. Tale moltiplicazione viene eseguita per rendere il diagramma più comprensibile.
La parte superiore della finestra di dialogo visualizza il nome di un simbolo o di una coppia incrociata e il relativo intervallo di tempo. Dopo di essi, puoi vedere due frasi che ci dicono della presenza o dell'assenza di autocorrelazione nella serie iniziale di rendimenti e nella serie di quadrati di rendimenti. Quindi vengono elencati il 10^, il 15^ e il 20^ lag, nonché il valore dell'autocorrelazione nella serie iniziale e nella serie di quadrati. Qui viene visualizzato un valore relativo di autocorrelazione: un flag booleano durante il test Q che determina se esiste una correzione automatica ai flag precedenti e specificati.
Alla fine, se vediamo che l'autocorrelazione esiste ai flag precedenti e specificati, allora il flag sarà uguale a true, altrimenti un false. Nel primo caso, la nostra serie è un "client" per l'applicazione del modello GARCH non lineare e, nel secondo caso, abbiamo bisogno di utilizzare modelli analitici più semplici. Un lettore attento noterà che la serie iniziale di rendimenti della coppia USDJPY è leggermente correlata tra loro, in particolare quella del periodo di tempo più grande. Ma la serie di quadrati di rendimenti mostra l'autocorrelazione.
Il tempo dedicato ai test è mostrato nella parte inferiore della finestra.
L'intero test è stato eseguito utilizzando lo script GarchTest.mq5.
Conclusioni
Nel mio articolo ho descritto come gli econometristi analizzano le serie temporali o, per essere più precisi, come iniziano i loro studi. Nel frattempo, ho dovuto scrivere molte funzioni e codificare diversi tipi di dati (ad esempio, i numeri complessi). Probabilmente, la stima visiva di una serie iniziale dà quasi lo stesso risultato della stima econometrica. Tuttavia, abbiamo accettato di utilizzare solo metodi precisi. Sai, un buon medico può stabilire una diagnosi senza utilizzare tecnologie e metodologie complesse. Ma, in ogni caso, studierà il paziente con attenzione e meticolosità.
Cosa otteniamo con l'approccio descritto nell'articolo? L'uso dei modelli non lineari GARCH consente di rappresentare formalmente la serie analizzata dal punto di vista matematico e di creare una previsione per un numero specificato di passaggi. Inoltre, ci aiuterà a simulare il comportamento delle serie nei periodi di previsione e testare qualsiasi Expert Advisor già pronto utilizzando le informazioni previste.
Posizione dei file:
| # | File | Percorso |
|---|---|---|
| 1 | ReturnsIndicator.mq5 | %MetaTrader%\MQL5\Indicators |
| 2 | Complex_class.mqh | %MetaTrader%\MQL5\Include |
| 3 | FFT_class.mqh | %MetaTrader%\MQL5\Include |
| 4 | GarchTest.mq5 | %MetaTrader%\MQL5\Scripts |
I file e la descrizione della libreria google_charts.mqh e Libraries.rar possono essere scaricati dall'articolo precedentemente citato.
Letteratura utilizzata per l'articolo:
- Analysis of Financial Time Series, Ruey S. Tsay, 2nd Edition, 2005. - p. 638.
- Applied Econometric Time Series,Walter Enders, John Wiley & Sons, 2nd Edition, 1994. - p. 448.
- Bollerslev, T., R. F. Engle, and D. B. Nelson. "ARCH Models." Handbook of Econometrics. Vol. 4, Chapter 49, Amsterdam: Elsevier Science B.V.
- Box, G. E. P., G. M. Jenkins, and G. C. Reinsel. Time Series Analysis: Forecasting and Control. 3rd ed. Upper Saddle River, NJ: Prentice-Hall, 1994.
- Numerical Recipes in C, The Art of Scientific Computing, 2nd Edition, W.H. Press, B.P. Flannery, S. A. Teukolsky, W. T. Vetterling, 1993. - p. 1020
- Gene H. Golub, Charles F. Van Loan. Matrix computations, 1999.
- Porshnev S. V. "Computing mathematics. Series of lectures", S.Pb, 2004.
Tradotto dal russo da MetaQuotes Ltd.
Articolo originale: https://www.mql5.com/ru/articles/222
Avvertimento: Tutti i diritti su questi materiali sono riservati a MetaQuotes Ltd. La copia o la ristampa di questi materiali in tutto o in parte sono proibite.
Questo articolo è stato scritto da un utente del sito e riflette le sue opinioni personali. MetaQuotes Ltd non è responsabile dell'accuratezza delle informazioni presentate, né di eventuali conseguenze derivanti dall'utilizzo delle soluzioni, strategie o raccomandazioni descritte.

 Le tabelle elettroniche in MQL5
Le tabelle elettroniche in MQL5
 Il Wizard MQL5: Come creare un modulo di segnali di trading
Il Wizard MQL5: Come creare un modulo di segnali di trading
 L'implementazione di una modalità multivaluta su MetaTrader 5
L'implementazione di una modalità multivaluta su MetaTrader 5
 Il Wizard MQL5: Come creare un modulo di gestione del rischio e del denaro
Il Wizard MQL5: Come creare un modulo di gestione del rischio e del denaro
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Non riesco a compilare
GarchTest
GarchTest_html
Pubblicato il nuovo articolo Un approccio econometrico all'analisi dei grafici:
Autore: Dennis Kirichenko
C'è un errore quando cerco di compilare "garchtest.mq5".
'-' - espressione intera attesa garchtest.mq5 154 28
In base alla vostra esperienza, pensate che questo metodo abbia una buona precisione nella pratica?
È stato un articolo decente. Mi è piaciuto molto. Voglio prevedere se un trend sta per iniziare o meno su una coppia di valute in uno specifico lasso di tempo, ad esempio H1. A tal fine, per prima cosa ottengo i rendimenti all'interno di un lasso di tempo di una certa lunghezza, ad esempio le ultime N "candele H1", e poi utilizzo il Q test. Se il test Q viene superato, adatto i parametri di un modello GARCH(1,1) ai rendimenti ottenuti dalla finestra temporale scelta e calcolo il valore atteso della varianza prevista per la candela H1 successiva. Se è superiore a una determinata soglia, allora possiamo aspettarci un trend in arrivo.
In base alla vostra esperienza, pensate che questo metodo abbia una buona precisione nella pratica?
Grazie per la sua opinione. Il modello non prevede la tendenza o l'inizio piatto. Permette piuttosto di definire i limiti dei rendimenti futuri. E la seconda opportunità è quella di simulare i rendimenti futuri (prezzi) all'interno dei limiti convalidati .
Grazie Denis per la tua preziosa risposta. Quindi, il modello predice i "limiti" dei rendimenti futuri, non il "segno" dei rendimenti futuri. È possibile prevedere il segno dei rendimenti futuri con altri modelli statistici complementari?