Que mettre à l'entrée du réseau neuronal ? Vos idées... - page 68
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Par exemple : le rapport entre le prix actuel et les N dernières bougies. Ou soumettre la même séquence chronologique, mais avec la relation obligatoire avec les données les plus récentes : s'il s'agit du prix - le reflet de l'incrément du prix le plus récent par rapport au reste. Et alors la chronologie "morte" et non viable commence à prendre vie.
Comment procédiez-vous auparavant ? Vous soumettiez des valeurs de prix absolues à des fins de formation ? Comme 1,14241, 1,14248.
Ce que vous avez décrit, ce sont des prix relatifs. Vous pouvez faire la différence (delta) du prix actuel par rapport à d'autres barres ou ratios, comme vous l'avez décrit.
Je me suis toujours entraîné sur les deltas. Le résultat est le même...
Comment procédiez-vous auparavant ? Avez-vous soumis des prix absolus à l'étude ? Comme 1,14241, 1,14248.
Ce que vous avez décrit est un prix relatif. Vous pouvez faire la différence (delta) du prix actuel par rapport à d'autres barres ou ratio, comme vous l'avez décrit.
Je me suis toujours entraîné sur les deltas. Le résultat est le même...
L'entréen' estpas la force du signal
Sa force lui est donnée par des poids. Mais le nombre d'entrées lui-même porte a priori déjà ( !) un élément de puissance - son facteur quantitatif.Plus tôt, j'ai soulevé le problème de la compréhension des données d'entrée. En donnant un nombre à l'entrée, nous la dotons déjà initialement d'une valeur de force.
C'est une erreur, car l'essence de notre NS consiste simplement à trouver le facteur de puissance et à le répartir entre les entrées. 0,9 à l'entrée - cela équivaut au fait que le signal est extrêmement fort. Et puis il y a des questions légitimes : 1) Pourquoi est-il fort ? 2) Où est-il fort ? À l'achat ? S'asseoir ? Maintenir ? Fermer l'achat ?
La valeur numérique de l'entrée est donc déjà prête pour le "post-traitement", donnant au préalable l'intensité du signal. Mais elle empêche le SN de travailler avec les données.
C'est le"bruit" même, dont l'essence est l'"interférence", le "brouillage", la "dégradation", le "cryptage". Cela équivaut à l'initialisation aléatoire des échelles avant la première époque d'apprentissage.
Ce n'est important que pour les poids, mais pour les entrées, c'est du bruit intentionnel. Et le SN est alors chargé de "nettoyer" les données d'entrée au lieu de les apprendre. Passons maintenant à la fonction destructrice des données numériques :lorsque le nombre 0,9 est donné en entrée, qu'est-ce que cela signifie ? "Acheter activement" ?
"Du point de vue de tout oscillateur dont la plage est comprise entre 0 et 1, il s'agit soit d'un achat, soit d'une vente,en fonction de .... du trader !
Seul ce dernier "dote" les oscillateurs de signaux magiques lorsqu'il élabore sa stratégie de trading. En pratique, ces chiffres ne signifient absolument rien.
N'importe quel programmeur/codeur parcourra l'ensemble de l'historique et constatera que ces signaux sont aléatoires. Lorsque le nombre 0,9 est saisi, que signifie-t-il ?
Le NS a la possibilité de l'"affaiblir" de manière significative à l'aide de poids. Qu'est-ce que cela implique ?
Si l'on tient compte du fait que les poids sont statiques dans toutes les architectures, cela signifie que les nombres inférieurs à 0,9 avec un affaiblissement significatif ne fonctionneront PAS. Ils n'affecteront tout simplement pas la performance globale, car dans l'additionneur, la somme totale se déplacera de manière insignifiante. Imaginons simplement que le NS ait fixé un poids de 0,1 au nombre d'entrée, qui a un maximum de "1" ; par conséquent, si l'entrée est de 0,9, le nombre deviendra 0,09.
9, le nombre deviendra 0,09, et si 0,1 arrive, le nombre sera 0,01. Littéralement, TOUTE la plage inférieure à 1 est simplement tuée. Et si la "viabilité" d'un nombre d'entrée donné se situe dans la plage de 0,1 à 0,5, et qu'en tombant dans cette zone, le nombre doit être "renforcé" ( !) pour l'architecture globale et les calculs ultérieurs dans les couches suivantes ? Cela ne fonctionnera pas, le nombre 0,9 s'introduira et "cassera" tout simplement toute la ruée.
Même dans le problème XOR, il n'y a pas de 2, il n'y a pas de 0,5 sur l'entrée. Il y a un 1-tuple. Par conséquent, l'entrée se présente comme suit : "oui, il y a un signal" (1) et "pas de signal" (0).
Le même signal est toujours appliqué à une entrée du problème. Si nous traduisons cette approche dans le langage des NS pour le forex, nous obtenons ce qui suit : si le nombre 0,9 arrive - nous l'appliquons à la première entrée, et si le nombre 0,1 arrive - nous l'appliquons à la deuxième entrée, sinon - 0.
Remarque : nous obtenons despoids dynamiques, c'est-à-dire qu'à l'étape initiale, le "bruit" est filtré.
Si 0,9 est un "mauvais" chiffre, nous le multiplions, disons, par 0,0001 afin de le "sprinter" tout en bas, de sorte qu'il n'interfère pas avec l'apprentissage avec son facteur de puissance excessif. Et si le chiffre est 0,1, nous le multiplions par le poids maximal "1,0" afin de définir l'influence maximale du chiffre sur le NS. Il y a donc quelque chose de raisonnable et de potentiel dans la dynamique des poids.
Je n'ai pas encore connecté le MLP plus avant, parce que je n'ai pas encore bien compris le problème du recyclage dans la dynamique des poids.
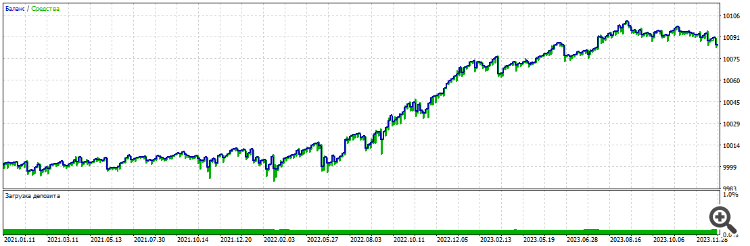
Tout cela avec les outils MT5, optimisation habituelle. Optimisation du filtre 2000-2021, EURUSD, H1 :
En avant première année 2021-2022
En avant deuxième année 2022-2023
Troisième année 2023-2024
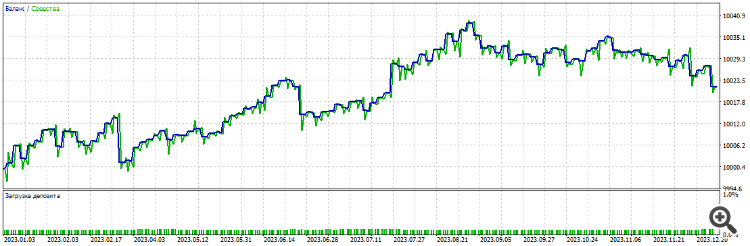
Les trois années de l'avant
UPDL'idée estdonc que le nombre sur l'entrée n'est que la position de la ligne indicatrice, pas la force.C'est un modèle de construction, qualitativement différent de tout autre (nombre).
Chaque modèle de construction doit se voir attribuer un poids, de sorte que leur nombre combiné organise le (grand) modèle de travail global .
Quelqu'un a eu de la chance avec NN et DL ?
---
sauf pour les graphiques en python et les tests ajustés :-) Au moins "Expert Advisor trades on demo and plus".
---
ou bien on a le sentiment qu'il s'agit d'une branche de l'évolution sans issue et que toute la production du mashobuch et des neurones se retrouve dans la publicité, les spams et les "mutual_sending".
c'est une branche de l'évolution sans issue.
Un peu comme le marc de café du 21e siècle.
Que se passe-t-il si la "praticabilité" d'un nombre d'entrée donné se situe entre 0,1 et 0,5 et que, tombant dans cette zone, le nombre doit être "renforcé" ( !) pour l'architecture globale et les calculs ultérieurs dans les couches suivantes ? Cela ne fonctionnera pas, le nombre 0,9 s'introduira et "cassera" tout simplement tout le bazar. Après tout, il est plus influent sur la solution NS en raison de sa domination quantitative constante.
Dans le cas des arbres, le problème est résolu par des divisions - les feuilles dont la valeur prédictive est < 0,1 et > 0,5 ne produiront pas de signaux.
En NS, cela est également possible si l'on utilise des fonctions d'activation non linéaires telles que la sigmoïde. Mais je n'ai pas étudié les NS depuis longtemps, je ne peux donc pas l'affirmer avec certitude. Mais en principe, ils fonctionnent également au niveau des modèles en bois, parfois mieux, et peuvent donc couper ce qui n'est pas nécessaire. C'est pourquoi je suis passé aux arbres, car on peut comprendre pourquoi une telle décision a été prise.