Phénomènes de marché - page 33
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Non pas que ce soit mal. C'est vrai, aussi vrai que l'expression "acheter bon marché, vendre cher". Ce n'est pas seulement l'exactitude qui compte, mais aussi la formalisabilité. Il ne sert à rien d'élaborer des constructions philosophiques intelligentes proches du marché si elles (les constructions) sont comme le lait d'une chèvre.
Pensez-vous que le délai après l'acceptation d'une perte est difficile à formaliser ? Ou qu'est-ce qui est différent ?
Merci. Je vais réfléchir à SOM à mon aise.
L'article en lien donne un aperçu des méthodes de segmentation des séries temporelles. Ils font tous à peu près la même chose. Non pas que SOM soit la meilleure méthode pour le forex, mais ce n'est pas non plus la pire, c'est un fait ;))
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.115.6594&rep=rep1&type=pdf
Mes collègues, malheureusement, ne me permettent pas de consacrer plus de temps au commerce, mais j'ai trouvé un peu de temps et j'ai décidé de demander (pour mon propre intérêt, pour ne pas l'oublier :o, donc je reviendrai plus tard, quand j'aurai plus de temps libre)
L'essence du phénomène.
Permettez-moi de vous rappeler l'essence de ce phénomène. Il a été découvert lors de l'analyse de l'influence des "longues queues" sur la déviation des prix futurs. Si nous classons les longues queues et examinons les séries chronologiques sans elles, nous pouvons observer certains phénomènes curieux, uniques pour presque chaque symbole. L'essence du phénomène est une classification très spécifique, basée en quelque sorte sur une approche "neuronale". En fait, cette classification "décompose" les données brutes, c'est-à-dire le processus de cotation lui-même, en deux sous-processus, qui sont conventionnellement appelés"alpha" et"betta". D'une manière générale, le processus initial peut être décomposé en un plus grand nombre de sous-processus.
Système à structure aléatoire
Ce phénomène s'applique très bien aux systèmes à structure aléatoire. Le modèle lui-même aura l'air très simple. Prenons un exemple. La série initiale EURUSD M15(nous avons besoin d'un échantillon long, et d'un cadre aussi petit que possible), à partir d'un certain "maintenant" :
Étape 1 : Classification
Une classification est effectuée et deux processus"alpha" et"beta" sont obtenus. Les paramètres du processus principal sont définis (le processus qui traite de l'"assemblage" final du devis).
Étape 2 Identification
Pour chaque sous-processus, un modèle basé sur le réseau de Volterry est défini :
Oh, quel malheur de les identifier.
Étape 3 Prédiction des sous-processus
Une prévision est faite pour 100 comptages pour chaque processus (pendant 15 minutes, soit un peu plus d'une journée).
Étape 4 : Modélisation de la simulation
Un modèle de simulation est construit, qui générera le nombre x.o. d'implémentations futures. Le schéma du système est simple :
Trois randomisations : une erreur pour chaque modèle et les conditions de transition du processus. Voici les réalisations elles-mêmes (à partir de zéro) :
Étape 5 : La solution commerciale.
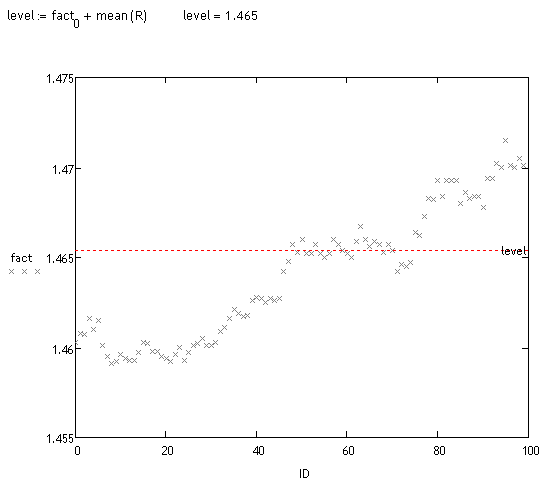
Une analyse de biais de ces réalisations est effectuée. Cela peut se faire de différentes manières. Visuellement, nous pouvons voir qu'une grande masse de trajectoires sont décalées. Regardons les faits :
<>
Essais préliminaires
J'ai pris environ 70 "mesures" au hasard (il faut beaucoup de temps pour compter). Environ 70% des déviations détectées par le système sont correctes, il n'a donc encore rien dit, mais j'espère revenir sur cette piste dans quelques mois, bien que je n'aie pas encore fini de travailler sur le projet principal :o(.
à sayfuji
Может не совсем корректно: по какому принципу производится классификация и, собственно, разложение на какие процессы предполагается?
Non, tout est correct. C'était l'un des sujets de discussion sur plusieurs dizaines de pages de ce fil. J'ai écrit tout ce que j'ai jugé nécessaire. Malheureusement, je n'ai pas le temps de développer davantage le sujet. En outre, ce phénomène en particulier, bien qu'intéressant, n'est pas très prometteur. Le phénomène des "longues queues" apparaît sur des horizons longs, c'est-à-dire là où il y a de grandes déviations de trajectoires, mais pour cela il faut prévoir au loin les processus alpha et betta (et d'autres processus). Et c'est impossible. Il n'y a pas de telle technologie...
:о(
à tous
Chers collègues, il s'avère qu'il y a des messages auxquels je n'ai pas répondu. Pardonnez-moi, il est inutile d'essayer de bouger maintenant.
Prohwessor Fransfort, veuillez répondre à la question de savoir quel programme vous utilisez pour vos recherches.
Et aussi...si quelqu'un a un manuel en russe ou un russifier pour le programme http://originlab.com/ (OriginPro 8.5.1)
Un résultat intéressant.
Ce phénomène pourrait-il être dû au fait que les données historiques sont des prix Bid ? (Lambda dans l'expérience est comparable à l'écart).
Ne pensez-vous pas qu'il est plus logique de tester la qualité du processus de "tendance" résultant en utilisant une régression linéaire avec des coefficients constants par morceaux lorsqu'ils sont considérés comme des fonctions du temps ?
Vous pouvez additionner les incréments filtrés et vous obtenez deux processus :