Régression bayésienne - Est-ce que quelqu'un a fait un EA en utilisant cet algorithme ? - page 40
Vous manquez des opportunités de trading :
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Inscription
Se connecter
Vous acceptez la politique du site Web et les conditions d'utilisation
Si vous n'avez pas de compte, veuillez vous inscrire
Et mon âme continue de vouloir creuser le sujet des citations incrémentales supposées normalement distribuées.
Si quelqu'un y est favorable, je donnerai des arguments expliquant pourquoi ce processus ne peut être normal. Et ces arguments seront compréhensibles par tous, tout en étant cohérents avec le CPT. Et ces arguments sont si triviaux qu'il ne devrait y avoir aucun doute.
Et qu'exprimera la probabilité, la prévision pour la prochaine barre, ou le vecteur de mouvement des prochaines barres ?
La probabilité exprime la prévision du prochain tick (incrément). Je le veux juste :
- calculer les valeurs des futurs ticks Ybayes pour lesquelles la probabilité par la formule de Bayes sera maximale.
- Comparez les Ybayes aux ticks Yreal réels qui arrivent . Collecter et traiter les statistiques .
Si la différence de valeurs se situe dans une fourchette raisonnable, je posterai le code et demanderai ce qu'il faut faire ensuite. Régression ? Vecteur ? Scalping ?
La probabilité exprime la prédiction du prochain tick (incrément). Je le veux juste :
Pourquoi descendre jusqu'aux tiques ? Vous pouvez apprendre à prédire les directions des tics en 5 minutes avec une précision de 70 %, mais 100 tics à l'avance, vous savez que la précision va chuter.
Essayez par tranches d'une demi-heure ou d'une heure à l'avance. C'est intéressant pour moi aussi, peut-être que je peux aider d'une manière ou d'une autre.
La probabilité exprime la prédiction du prochain tick (incrément). Je le veux juste :
- calculer les valeurs des futurs ticks Ybayes pour lesquelles la probabilité par la formule de Bayes sera maximale.
- Comparez les Ybayes aux ticks Yreal réels qui arrivent . Collecter et traiter les statistiques .
Si la différence de valeurs se situe dans une fourchette raisonnable, je posterai le code et demanderai ce qu'il faut faire ensuite. Régression ? Vecteur ? Courbe ? Scalping ?
Quel est le problème avec ARIMA ? Dans les paquets, le nombre de diffs (incréments d'incréments) est calculé automatiquement en fonction du flux d'entrée. De nombreuses subtilités liées à la stationnarité sont cachées dans l'emballage.
Si tu veux vraiment aller aussi loin, alors un certain ARCH ?
J'ai essayé une fois. Le problème est le suivant. L'incrément peut être calculé facilement. Mais si nous ajoutons l'intervalle de confiance de cet incrément à l'incrément lui-même, il sera soit ACHETER, soit VENDRE puisque la valeur du prix précédent se situe à l'intérieur de l'intervalle de confiance.
Oui, l'approche classique, comme l'écrit SanSanych, est l'analyse des données, les exigences en matière de données et les erreurs de système.
Mais ce fil de discussion porte sur Bayes et j'essaie de penser en termes bayésiens, comme le soldat dans la tranchée qui calcule la probabilité postérieure (après expérience). J'ai donné un exemple du soldat ci-dessus.
L'une des principales questions est de savoir ce qu'il faut prendre comme probabilité a priori. En d'autres termes, qui devrions-nous mettre derrière le rideau du futur, à droite de la barre du zéro ? Gauss ? Laplace ? Wiener ? Qu'est-ce que les mathématiciens professionnels écrivent ici (pour moi une "forêt" sombre) ?
Je choisis Gauss parce que j'ai une idée de la distribution normale et que j'y crois. S'il ne "tire" pas, il est possible de prendre d'autres lois et de substituer Gauss à la formule de Bayes, ou avec Gauss comme produit de deux probabilités. Essayez de faire un réseau bayésien, si je comprends bien.
Naturellement, je ne peux pas le faire seul. Je voudrais résoudre le problème avec Gauss, que j'ai formulé sous le bouquet. Si quelqu'un est prêt à se joindre à moi sur une base volontaire, qu'il le fasse. Voici un problème réel.
Soit : un générateur de nombres aléatoires.
Besoin : Ecrire le code MQL4 comme fonction FP() convertissant le tableau МТ4[] formé par le RNG standard en tableau ND[] avec une distribution normale.
Vasily (je ne connais pas mon patronyme) Sokolov m'a montré les formules de transformation sur https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
L'altruisme et la bonté seront une représentation graphique des résultats, bien que je puisse zoomer les graphiques des tableaux calculés directement dans la fenêtre MT4. Je le faisais dans mes projets.
Je comprends que de nombreuses personnes ici présentes peuvent résoudre ce problème en quelques clics dans des progiciels mathématiques, mais je veux parler dans un langage MQL4, qui est communément compris par les traders, les programmeurs, les économistes et les philosophes.
Oui, l'approche classique, comme l'écrit SanSanych, est l'analyse des données, les exigences en matière de données et les erreurs de système.
Mais ce fil de discussion porte sur Bayes et j'essaie de penser en termes bayésiens, comme le soldat dans la tranchée qui calcule la probabilité postérieure (après expérience). J'ai donné un exemple du soldat ci-dessus.
L'une des principales questions est de savoir ce qu'il faut prendre comme probabilité a priori. En d'autres termes, qui devrions-nous mettre derrière le rideau du futur, à droite de la barre du zéro ? Gauss ? Laplace ? Wiener ? Qu'est-ce que les mathématiciens professionnels écrivent ici (pour moi une "forêt" sombre) ?
Je choisis Gauss parce que j'ai une idée de la distribution normale et que j'y crois. S'il ne "tire" pas, il est possible de prendre d'autres lois et de substituer Gauss à la formule de Bayes, ou avec Gauss comme produit de deux probabilités. Essayez de faire un réseau bayésien, si je comprends bien.
Naturellement, je ne peux pas le faire seul. Je voudrais résoudre le problème avec Gauss, que j'ai formulé sous le bouquet. Si quelqu'un est prêt à se joindre à moi sur une base volontaire, qu'il le fasse. Voici un problème réel.
Soit : un générateur de nombres aléatoires.
Besoin : Ecrire le code MQL4 comme fonction FP() convertissant le tableau MT4[] formé par le RNG standard en tableau ND[] avec une distribution normale.
Vasily (je ne connais pas mon patronyme) Sokolov m'a montré les formules de transformation sur https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/.
Cependant, je peux redimensionner les graphiques des tableaux calculés directement dans la fenêtre de MT4. Je le faisais dans mes projets.
Je comprends que de nombreux traders peuvent résoudre ce problème dans des progiciels mathématiques en deux clics, mais je veux utiliser le langage MQL4, qui est généralement accessible aux traders, aux programmeurs, aux économistes et aux philosophes.
Voici un générateur avec différentes distributions, dont la normale :
https://www.mql5.com/ru/articles/273
Brève analyse de la distribution en R :
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Nous avons estimé les paramètres de la distribution normale à partir des incréments de prix d'ouverture des barres d'horloge disponibles et nous avons tracé des graphiques pour comparer la fréquence et la densité pour la série originale et la série normale avec les mêmes distributions. Comme vous pouvez le constater même à l'œil nu, la série originale d'incréments des barres horaires est loin d'être normale.
Et d'ailleurs, nous ne sommes pas dans un temple de Dieu. Il n'est pas nécessaire et même nuisible de croire.
Voici une ligne curieuse du post ci-dessus, qui fait écho à ce que j'ai écrit plus haut
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
D'après ce que je comprends dans les quadrants, 50% de tous les incréments sur l'horloge sont inférieurs à 7 pips ! Et les incréments les plus décents se trouvent dans les queues épaisses, c'est-à-dire de l'autre côté du bien et du mal.
Alors, à quoi ressemblera le TS ? C'est là le problème, pas le Bayesian et autres, autres, autres.....
Ou faut-il le comprendre autrement ?
Voici une ligne curieuse du post ci-dessus, qui fait écho à ce que j'ai écrit plus haut
-2,515e-02 -6,800e-04 0,000e+00 -3,400e-076,900e-04 6,849e-02
D'après ce que je comprends dans les quadrants, 50% de tous les incréments sur l'horaire sont inférieurs à 7 pips ! Et les incréments les plus décents se trouvent dans les queues épaisses, c'est-à-dire de l'autre côté du bien et du mal.
Alors, à quoi ressemblera le TS ? C'est là le problème, pas le Bayesian et autres, autres, autres.....
Ou faut-il le comprendre autrement ?
SanSanych, oui !
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')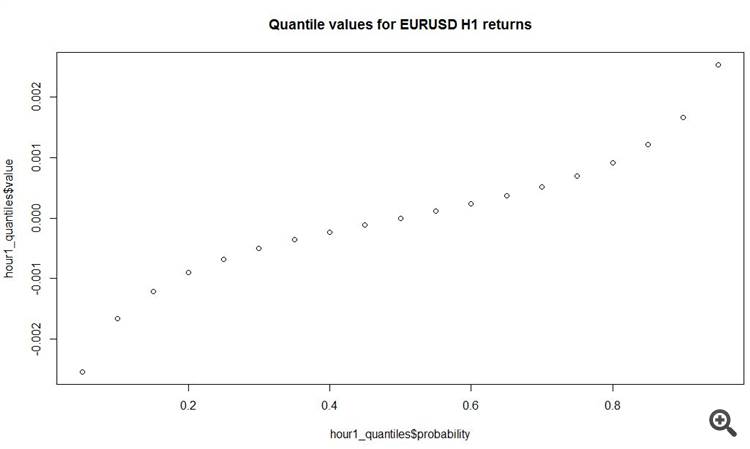
Et une autre chose intéressante est que l'incrément absolu moyen sur les barres horaires est de 11 pips ! Total.
Vous devrez le faire pendant longtemps, car vous avez besoin de vous retransformer et... Et Box-Cox n'aime pas vraiment ça)))). C'est juste une honte que si vous n'avez pas
C'est juste dommage que si vous n'avez pas de bons prédicteurs, cela n'aura pas beaucoup d'effet sur le résultat final...