Discussion de l'article "Estimation de la densité de noyau de la fonction de densité de probabilité inconnue"
A l'auteur. On obtient des résultats encore meilleurs si l'on estime non pas la densité de la distribution, mais la fonction de distribution, c'est-à-dire l'intégrale de la densité : tout d'abord, il est plus facile de la construire sur les données, et comme elle est toujours non décroissante et limitée entre 0 et 1, la sensibilité au choix de l'algorithme de lissage, qu'il s'agisse d'un noyau, d'une spline, d'une régression ou d'autre chose, est beaucoup plus faible. Les exigences relatives à la quantité de données disponibles sont également réduites, et ce d'un ordre de grandeur.
Enfin, la densité peut être facilement obtenue par différenciation numérique, si nécessaire.
La densité peut être facilement obtenue par différenciation numérique si nécessaire.
Peut-être. Je ne peux rien dire à ce sujet. Je n'ai même pas essayé d'évaluer le pdf via le cdf . Il est très probable que le préjugé selon lequel l'utilisation de la différenciation nécessiterait une augmentation significative de la précision de l'estimation du cdf ait fonctionné. En outre, je n'ai trouvé aucune publication évaluant la méthode cdf->pdf ou la comparant à d'autres méthodes. Si vous pouvez partager des liens, je vous en serais reconnaissant.
L'idée originale était de ne pas utiliser d'outils externes, c'est-à-dire qu'il était supposé que tout devait être mis en œuvre uniquement par les outils MQL5.
C'est l'idée de tous les inventeurs de bicyclettes sans exception.
Regardez ce que les paquets correspondants ont à cet égard et comparez-les avec ce que vous avez fourni - une quantité infinitésimale de ce qui est nécessaire pour appliquer la mathématique et l'économétrie au commerce.
Peut-être. Je ne peux rien dire à ce sujet. Je n'ai même pas essayé d'estimer le pdf via le cdf . Très probablement, le préjugé selon lequel l'utilisation de la différenciation nécessiterait une augmentation significative de la précision de l'estimation du cdf a fonctionné. En outre, je n'ai trouvé aucune publication évaluant la méthode cdf->pdf ou la comparant à d'autres méthodes. Si vous me communiquez des liens, je vous en serais reconnaissant.
Je ne peux pas fournir de références car je ne les ai pas. Je vais plutôt donner ces considérations.
Lorsque l'on évalue un pdf directement, il faut diviser le domaine de la définition en intervalles à l'avance, et il y a deux problèmes : premièrement, nous ne savons pas combien d'intervalles il vaut mieux diviser le domaine, et deuxièmement, nous ne savons pas quel type de grille(uniforme, ... ?) serait le meilleur. Et si pour la deuxième question, les gens ont quand même essayé de la résoudre, par exemple en utilisant le partitionnement par quantile, pour la première, à mon avis, il n'y a pas du tout de méthodes universelles : toutes celles que je connais ont des limitations qui les rendent peu utiles dans les tâches d'automatisation, quand on ne peut pas se permettre la méthode du poke.
L'estimation du cdf est dépourvue de ces inconvénients. Dans ce cas, les pas de la fonction sont situés exactement là où tombent les données d'entrée, et donc le problème du choix d'une grille pour l'interpolant disparaît de lui-même. Une fois la grille créée, il n'est pas difficile de choisir le nombre d'intervalles : nous connaissons déjà le nombre maximum d'intervalles (et leur emplacement !!!), donc, par amincissement, nous pouvons fixer n'importe quelle précision requise, et à chaque fois sur une grille naturelle qui correspond le mieux à la structure des données d'entrée.
En pratique, j'ai utilisé cette technique pour rechercher des modes locaux de distributions empiriques lorsque le nombre d'échantillons de données ne dépasse pas 100, et j'ai obtenu des résultats très lisses, et visuellement la précision de la recherche est définie comme assez qualitative, au moins 2-4 modes principaux sont trouvés pratiquement sans déviations. Mais j'utilise un algorithme de lissage différent, je n'aime pas les algorithmes à noyau pour plusieurs raisons.
Tout cela est parfaitement juste. Mais il me semble que c'est le cas, à l'exception d'un point, auquel vous n'avez apparemment pas prêté attention.
Une expression bien connue pour Kernel smoother est "Kernel smooth".
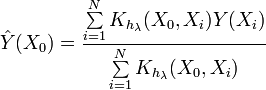
Une méthode basée sur un tel lissage pour l'estimation de la fdp pourrait ressembler à ceci (simplifié) :
- Nous partitionnons la séquence d'entrée en intervalles (clustering, Binning).
- Lissage de l'histogramme résultant.
Si vous n'aimez pas le lissage par noyau, vous pouvez utiliser, par exemple, p-spline. (Il est probablement préférable de choisir p-spline tout de suite).
Avec cette approche de l'estimation du pdf , tout ce que vous avez dit s'avère tout à fait juste. Mais même dans ce cas, cette méthode d'estimation pour les séquences de grande longueur (>1000000) donne d'excellents résultats. Au fur et à mesure que la longueur de la séquence d'entrée diminue, tous les avantages que vous avez mentionnés commencent à se manifester de plus en plus fortement.
Examinons maintenant l'expression de l'estimation de la densité de Kernel (K DE)
![]()
Cette expression est différente de celle donnée précédemment. Comme nous pouvons le voir, cette expression détermine directement la valeur de la fonction de densité de probabilité en un point donné. Et ce qui est important dans ce cas, c'est qu'il n'y a pas de partitionnement en intervalles. Les valeurs de la séquence d'entrée sont utilisées directement.
C'est du moins ainsi que je vois la situation avec KDE. L'algorithme d'estimation pdf présenté dans l'article s'adapte à première vue assez bien aux séquences de 20 à 30 éléments. Il peut arriver que vous souhaitiez réduire le degré de lissage. Vous pouvez facilement le faire en remplaçant dans le code
h=0.9*a/MathPow(N,0.2); // Règle empirique de Silvermanpar
h=0.7*a/MathPow(N,0.2); // Règle empirique de Silverman
L'idée originale était de ne pas utiliser d'outils externes, c'est-à-dire qu'il était supposé que tout devait être mis en œuvre uniquement par les outils MQL5.
C'est l'idée de tous les inventeurs de bicyclettes sans exception.
Regardez ce que les paquets correspondants ont à cet égard et comparez-les avec ce que vous avez fourni - une quantité infinitésimale de ce qui est nécessaire pour appliquer la mathématique et l'économétrie au commerce.
Cher Alex,
Il est facile pour vous de raisonner du haut de votre vol. Mais réfléchissez un instant à ce qui suit :
Cette ressource s'appelle"www.mql5.com - Automated Trading and Testing of Trading Strategies". Comme vous pouvez le constater, le site s'appelle mql5, et non EViews ou même MQ ou MT5. Il est donc facile de supposer que ce site est principalement axé sur la popularisation, le débogage et le développement du langage de programmation MQL5. Ceci est confirmé par la présence du servicedesk et l'emplacement des informations de référence MQL5 sur le site.
Si ce site s'appelait, par exemple, "une collection de stratégies de trading" et n'appartenait pas à MQ. Dans ce cas, on s'attendrait à ce que des publications décrivant des solutions en Exel, R, EVievs, Gauss, Stata , etc. apparaissent sur un tel site.
Si j'avais publié cet article sur le site d'EViews, j'aurais peut-être essayé de comprendre l'essence de votre reproche. Mais vous et moi ne sommes pas sur EViews en ce moment.
Ce site est visité par des personnes d'horizons très différents. Il s'agit de personnes d'âges différents, avec des niveaux d'éducation différents et des spécialités différentes. Je pense que la plupart d'entre eux n'ont que peu ou pas d'expérience avec les progiciels économétriques. Pensez-vous que toutes ces personnes devraient être bannies de ce site, par exemple en les laissant apprendre EViews d'abord ?
Puisque vous vous êtes auto-publié, vous devriez connaître la procédure de publication d'articles sur ce site. Il est impossible d'auto-publier un article. Vous ne pouvez que soumettre un article pour examen. L'administration du site sélectionne elle-même les articles qui conviennent à son concept général. Dans certains cas, l'administration commande elle-même des articles sur des sujets qui l'intéressent. Comme je l'ai déjà dit, l'administration dispose d'un concept général et de statistiques sur le nombre de demandes pour telle ou telle publication. Dans cette situation, je pense qu'il n'est pas tout à fait correct de m'adresser des réclamations sur le sujet de l'article. Peut-être devriez-vous discuter de ces questions avec les représentants de MQ?
Certains articles publiés sur ce site ne m'intéressent pas. J'insiste sur le fait qu'il ne s'agit pas de mauvais articles, mais qu'ils ne m'intéressent tout simplement pas. En général, je ne les lis pas et je n'écris pas de commentaires à leur sujet. Peut-être devriez-vous adopter un comportement similaire ? Bien que je n'ose pas vous donner de conseils, faites comme vous vous sentez le plus à l'aise.
Cher Alex,
Il est facile pour vous de raisonner du haut de votre vol. Mais réfléchissez un instant à ce qui suit :
Cette ressource s'appelle"www.mql5.com - Automated Trading and Testing of Trading Strategies". Comme vous pouvez le constater, le site s'appelle mql5, et non EViews ou même MQ ou MT5. Il est donc facile de supposer que ce site est principalement axé sur la popularisation, le débogage et le développement du langage de programmation MQL5. Ceci est confirmé par la présence du servicedesk et l'emplacement des informations de référence MQL5 sur le site.
Si ce site s'appelait, par exemple, "une collection de stratégies de trading" et n'appartenait pas à MQ. Dans ce cas, on s'attendrait à ce que des publications décrivant des solutions en Exel, R, EVievs, Gauss, Stata , etc. apparaissent sur un tel site.
Si j'avais publié cet article sur le site d'EViews, j'aurais peut-être essayé de comprendre l'essence de votre reproche. Mais vous et moi ne sommes pas sur EViews en ce moment.
Ce site est visité par des personnes d'horizons très différents. Il s'agit de personnes d'âges différents, avec des niveaux d'éducation différents et des spécialités différentes. Je pense que la plupart d'entre eux n'ont que peu ou pas d'expérience avec les progiciels économétriques. Pensez-vous que toutes ces personnes devraient être bannies de ce site, par exemple en les laissant apprendre EViews d'abord ?
Puisque vous vous êtes auto-publié, vous devriez connaître la procédure de publication d'articles sur ce site. Il est impossible d'auto-publier un article. Vous ne pouvez que soumettre un article pour examen. L'administration du site sélectionne elle-même les articles qui conviennent à son concept général. Dans certains cas, l'administration commande elle-même des articles sur des sujets qui l'intéressent. Comme je l'ai déjà dit, l'administration dispose d'un concept général et de statistiques sur le nombre de demandes pour telle ou telle publication. Dans cette situation, je pense qu'il n'est pas tout à fait correct de m'adresser des réclamations sur le sujet de l'article. Peut-être devriez-vous discuter de ces questions avec les représentants de MQ?
Certains articles publiés sur ce site ne m'intéressent pas. J'insiste sur le fait qu'il ne s'agit pas de mauvais articles, mais qu'ils ne m'intéressent tout simplement pas. En général, je ne les lis pas et je n'écris pas de commentaires à leur sujet. Peut-être devriez-vous adopter un comportement similaire ? Bien que je n'ose pas vous donner de conseils, faites comme vous vous sentez le plus à l'aise.
Je ne peux pas accepter votre réponse, car elle ne correspond pas du tout à l'essence de mon message. Je vais essayer d'expliquer mon point de vue.
1. Metaquotes n'a rien à voir avec cela - ils ont fourni un outil très décent et ils le font.
2. Je n'ai pas connaissance de restrictions sur les sujets des articles. Bien sûr, dans les limites de la négociation. Ce site a une section "Statistiques", c'est-à-dire qu'ils comprennent le sujet du site beaucoup plus largement que vous, en pleine conformité avec le contenu et les problèmes du trading. Ne faisons pas référence à Metaquotes et passons au fond.
3. mon post ne porte pas sur CE qu'il faut développer, mais sur COMMENT développer. C'est pour moi ce qui est fondamental par rapport à votre article. Je ne faisais pas campagne pour EViews, dont j'ai une piètre opinion - il est bon à des fins de démonstration et de formation, mais je ne pense pas que l'on puisse faire du commerce avec lui. Mon lien vers les paquets démontre l'ampleur du problème.
4. Je travaille dans le domaine de la programmation depuis longtemps. Il y a 40 ans, les premières bibliothèques de programmes sont apparues et, il y a 40 ans, on a immédiatement critiqué les amateurs qui réécrivaient un programme à partir d'un paquet existant. Vous n'êtes pas le premier. Mais ce site est rempli d'amateurs qui aiment reconstruire une bicyclette - d'où ma réaction hypertrophiée.
5. La question de l'évaluation nucléaire est une question qui a été longuement débattue. Et si vous preniez la bibliothèque de quelqu'un d'autre, vous auriez l'occasion de vous élever au-dessus des difficultés techniques que vous avez résolues dans votre article et peut-être d'offrir une solution aux problèmes soulevés par le praticien alsu, ou de vous rappeler que l'évaluation visuelle des distributions joue un rôle très important dans leur évaluation formelle, ou de vous développer sur le plan fonctionnel, etc. - Dans tous les cas, vous auriez fait un pas en avant.
Je n'avais pas l'intention d'exprimer quoi que ce soit d'offensant à votre égard. Votre article et votre développement sont respectés, mais je ne peux pas être d'accord avec l'orientation méthodologique de la technique de mise en œuvre de vos idées.
Mon post sur votre article est dicté par l'espoir que quelqu'un complétera systématiquement le terminal Metaquot avec des moyens statistiques et économétriques. Je vous renvoie à ces personnes.
Extrêmement intéressant. Très intéressant.
Acceptez-vous des demandes ?
Pas seulement du code source ouvert, mais du code orienté vers les statistiques est souhaitable. Veuillez prêter attention à R.
Les demandes sont acceptées ici : https://www.mql5.com/ru/forum/6505. Écrivez ce que vous voulez. :)
- www.mql5.com
- Applications de trading gratuites
- Plus de 8 000 signaux à copier
- Actualités économiques pour explorer les marchés financiers
Vous acceptez la politique du site Web et les conditions d'utilisation
Un nouvel article Estimation de la densité de noyau de la fonction de densité de probabilité inconnue a été publié :
L'article traite de la création d'un programme permettant d'estimer la densité à noyau de la fonction de densité de probabilité inconnue. La méthode d'estimation de la densité du noyau a été choisie pour exécuter la tâche. L'article contient les codes sources de la mise en œuvre logicielle de la méthode, des exemples d'utilisation et des illustrations.
La figure 1 présente les graphiques d'estimation de la densité pour la séquence ayant la loi de distribution normale et différentes valeurs de l'intervalle h.
Les estimations sont effectuées en utilisant la classe CDens décrite ci-dessus. Les graphiques ont été construits sous forme de pages HTML. La méthode de construction de ces graphiques sera présentée à la fin de l'article. La création de graphiques et de diagrammes au format HTML peut être trouvée à [9].
Fig. 1. Estimation de la densité pour diverses valeurs de l’intervalle h
Auteur : Victor