Discusión sobre el artículo "Sistema secuencial de Tom DeMark (TD SEQUENTIAL) con uso de inteligencia artificial"
Entonces, ¿dónde está la "inteligencia artificial" como usted afirma? ¿Dónde está la red neuronal?
1. ¿Dos direcciones NN? Ha resuelto problemas( en su mayoría) dos - regresión y clasificación. Con menos frecuencia se utiliza la agrupación y clasificación. Y hay docenas, si no cientos, de redes neuronales. ¿Qué tipo de red neuronal has utilizado?
2. El overfiting no sólo está definido, sino que se han desarrollado métodos para reducir la probabilidad de que se produzca. En el caso de las redes neuronales se trata de regularización (L1/L2), estabilización (dropout, dropconnect y muchos otros). Por tanto, parafraseando una conocida expresión: todos los modelos se reentrenan, pero algunos tienen una probabilidad mucho menor de ello.
3. Los clasificadores pueden ser "duros", es decir, que nunca abandonan la predicción, y "blandos", que pueden negarse a predecir y decir "no lo sé". "El clasificador "duro" se convierte en "blando" tras la calibración. Hay otras formas de "suavizar" un clasificador.
4. La recomendación de invertir las señales tras el primer error al principio del día es estupenda.
Si no hubiera numerosos anuncios preliminares del autor con la promesa de una revolución en el uso de redes neuronales, se podría pasar por alto.
Y así, en cuanto a mí - no hay crédito.
Entonces, ¿dónde está la "inteligencia artificial" como usted afirma? ¿Dónde está la red neuronal?
1. ¿Dos direcciones NN? Ha resuelto problemas( en su mayoría) dos - regresión y clasificación. Con menos frecuencia se utiliza la agrupación y clasificación. Y hay docenas, si no cientos, de redes neuronales. ¿Qué tipo de red neuronal has utilizado?
2. El overfiting no sólo está definido, sino que se han desarrollado métodos para reducir la probabilidad de que se produzca. En el caso de las redes neuronales se trata de regularización (L1/L2), estabilización (dropout, dropconnect y muchos otros). Por tanto, parafraseando una conocida expresión: todos los modelos se reentrenan, pero algunos tienen una probabilidad mucho menor de ello.
3. Los clasificadores pueden ser "duros", es decir, que nunca abandonan la predicción, y "blandos", que pueden negarse a predecir y decir "no lo sé". "El clasificador "duro" se convierte en "blando" tras la calibración. Hay otras formas de "suavizar" un clasificador.
4. La recomendación de invertir las señales tras el primer error al principio del día es estupenda.
Si no hubiera numerosos anuncios preliminares del autor con la promesa de una revolución en el uso de redes neuronales, uno podría pasarlo por alto.
Pero en cuanto a mí, es un fracaso.
Bueno ... ¡¡¡excelente!!! Ahí están los primeros comentarios y da gusto verlos.
1. Sí, en efecto, hay muchos tipos de NS, pero los principales son dos direcciones, clasificación y predicción, Clustering, implica cuando las clases no son dos 0 y 1, pero más. aquí es otro nivel de problemas.
2. De hecho nada se detiene, y ya existen métodos para reducir el sobreentrenamiento, pero el grado de sobreentrenamiento no es fácil de identificar.
3. se utiliza un comité de dos redes. Cada red por separado "no abandona la predicción", como usted dice, pero a nosotros sólo nos interesa el momento en que el comité dice simultáneamente "Sí" o "No".Los comités de redes se utilizan desde hace mucho tiempo y son ampliamente utilizados. Según el autor Yuri, un comité tiene mayor poder de generalización que una sola red.
4. Sí que hay que hacerlo con precaución, porque al dar la vuelta a la red se puede cometer un error por segunda vez. La cuestión es que comparamos dos señales, la actual y la anterior, y conociendo el resultado de la anterior podemos sacar una conclusión sobre la señal actual, sobre su verdad, etc. De hecho, la red puede simplemente cometer un error!!!!.
Bueno, yo no prometí ningún golpe, sólo prometí un método de construcción JUSTO de TS, porque a veces algunos escriben tal herejía que da un poco de miedo!!!!.
Lo siento, pero el artículo es muy malo, de verdad, de verdad... ay. Es un anuncio del optimizador Reshetov y eso es todo, nada útil. Tomemos el ejemplo del artículo del Sr. Fomenko sobre los bosques y las tendencias, allí, aunque para los principiantes, pero muy informativo, lo has hecho muy mal, con el debido respeto.
Voy a ser honesto, es mi primera experiencia. ¿Y qué es lo que no te ha gustado? ¿Puedes ser más específico? ¿Quizás algo no está claro? Después de todo, el punto del artículo era informar sobre los métodos que cada uno puede utilizar al construir su propio TS, no es necesario adoptar mi TS en particular.
Bueno.... ¡¡¡genial!!! Ya están los primeros comentarios y da gusto verlos.
1. Sí, en efecto, hay muchos tipos de NS, pero los principales son dos direcciones, clasificación y predicción, Clustering, implica cuando las clases no son dos 0 y 1, pero más. aquí ya es otro nivel de problemas
2. De hecho nada se detiene, y ya existen métodos para reducir el sobreentrenamiento, pero el grado de sobreentrenamiento no es fácil de identificar.
3. se utiliza un comité de dos redes. Cada red por separado "no abandona la predicción", como usted dice, pero a nosotros sólo nos interesa el momento en que el comité dice simultáneamente "Sí" o "No".Los comités de redes se utilizan desde hace mucho tiempo y son ampliamente utilizados. Según el autor Yuri, un comité tiene mayor poder de generalización que una sola red.
4. Sí que hay que hacerlo con precaución, porque al dar la vuelta a la red se puede cometer un error por segunda vez. La cuestión es que comparamos dos señales, la actual y la anterior, y conociendo el resultado de la anterior podemos sacar una conclusión sobre la señal actual, sobre su verdad, etc. De hecho, la red puede simplemente cometer un error!!!!.
Bueno, yo no prometí ningún golpe, sino que sólo prometí un método de construcción JUSTO de TS, porque a veces algunos escriben tal herejía que da un poco de miedo!!!!.
1. Un clasificador puede predecir 10, 100, 1000 clases y seguirá siendo un clasificador. CLASIFICACIÓN es la división de un conjunto de datos sin etiquetar en grupos basados en determinados atributos.
2. No es fácil determinar el momento de inicio del sobreentrenamiento, pero sí muy fácil.
3. Efectivamente, un comité de modelos da (¡no siempre!) el mejor resultado. Pero en su caso no se trata realmente de un comité.
Suerte
Por desgracia, mi crítica no se refiere a la calidad literaria del artículo, que es bastante normal, sino a su contenido semántico. No ha dicho nada interesante.
Consideras algún drenador aleatorio "Demark" y quieres enseñarlo a ganar con la ayuda de NS, este es un enfoque sin salida, en lugar de Demark puedes insertar cualquier indicador, el significado no cambiará, entonces ¿para qué sirve? Y si este filtro en particular es una buena característica, usted no ha explicado por qué es así. Entonces todo lo que en realidad sobre ML y característica-ingeniería , es que todo va a hacer optimizador Reshetov ... mmm.... así que es ... esto es para un artículo específico de la audiencia a continuación, para la "carne", pero la carne ni siquiera puede entender cómo jar ejecutar, no sólo es necesario ejecutar en mt y ver cómo el proceso de drenaje ))).
Explicar de forma sucinta y concisa, con imágenes y fórmulas, cómo funciona el optimizador de Reshetov, ya que todo el punto está en él, cómo hace fichas, cómo clasifica, por qué lo hace mejor que tal o cual método mainstream de extracción de fichas y clasificación, con ejemplos y conjuntos de datos para que todos pudieran convencerse, refinar en general, mientras que es malo.
Y tirar todas las letras, especialmente acerca de las comparaciones de Reshetov con Stradivarius, de lo contrario parece que usted y Reshetov son una persona física, por lo que incluso Lecun nadie alaba))))) He descargado los tipos de Reshetov, pero por lo que las manos no llegó a entender en algoritmo sobre las fuentes, que puede tomar aproximadamente hasta una semana, pero no hay tiempo tanto en algoritmo probablemente extraño, que incluso 2-figuras conjuntos de datos por alguna razón no quiere comer))))) Quería ver cómo lo hace la máscara particionada para distribuciones bidimensionales....
Lo comentaba en el artículo, que se puede tomar cualquier TS como base, yo tomé Demark por las razones que describía en el artículo (hay una ventana, señales en picos y valles). El punto es crear un polinomio que tendrá una generalización de la variable de salida, y con qué ayuda lo harás, no hace ninguna diferencia. Lo principal son los datos de entrada que deben ser la razón del precio, ya que interpertamos el trabajo de cualquier TS al precio.
Me encontré con este recurso después de editar el artículo. Aquí explica más claramente el trabajo del optimizador. Será muy útil para los desarrolladores de IA, que no soy, por favor, tenga en cuenta https://sites.google.com/site/libvmr/home/theory/method-brown-robinson-resetov.
- sites.google.com
1. Un clasificador puede predecir 10, 100, 1000 clases y seguirá siendo un clasificador. CLASIFICACIÓN: dividir un conjunto de datos sin etiquetar en grupos en función de determinados atributos.
2. No es fácil determinar el momento de inicio del sobreentrenamiento, pero sí muy fácil.
3. Efectivamente, un comité de modelos da (¡no siempre!) el mejor resultado. Pero en su caso no se trata realmente de un comité.
Suerte
1. Estoy de acuerdo, la diferencia entre un clasificador y la agrupación en un maestro y sin, en ese caso.
2.Interesante escuchar a un futuro premio Nobel en re-aprendizaje, porque la pregunta es realmente interesante no sólo para mí. ¿Es por qué método???? Y es posible detectar el grado de sobreaprendizaje?
3. ¿Qué te hace estar tan decidido de que esto no es un comité???? cómo así???? Interesante......
Vale, estás insinuando que si Reshetov es un Stradivarius, tú no eres más que Mozart, ¡comprobémoslo!
Te propongo hacerlo, te daré un conjunto de datos, tú aprendes en él y yo un clasificador entrenado, no importa jar o serialización, lo principal es que sea utilizable en un par de clics, y yo lo ejecutaré en un conjunto de prueba, que tú no has visto, si el clasificador vale la pena (por ejemplo, compáralo con XGB ) .luego seguiremos la conversación sobre las creaciones de Reshetov, yo solo cogeré y parsearé el código de sus fuentes, así será más fácil de entender que entender sobre el método Brown-Robinson y el vector Shackley, etc.
Publicaré los resultados con los datos y su modelo. Por ahora es una caja negra más con publicidad simple, de las que hay decenas de miles, y lo siento, pero no puedo permitirme estar una semana analizándola, sin pruebas de que no es peor que XGB.
¡¡¡Gran plan!!! Llevo tiempo queriendo probarlo. Me envías un archivo para entrenar, yo te envío un modelo, y luego lo probamos y posteamos los resultados. ¿VALE?
Vale, estás insinuando que si Reshetov es un Stradivarius, tú no eres más que Mozart, ¡comprobémoslo!
Te propongo hacerlo, te daré un conjunto de datos, tú aprendes en él y yo un clasificador entrenado, no importa jar o serialización, lo principal es que sea utilizable en un par de clics, y yo lo ejecutaré en un conjunto de prueba, que tú no has visto, si el clasificador vale la pena (por ejemplo, compáralo con XGB ) .luego seguiremos la conversación sobre las creaciones de Reshetov, yo solo cogeré y parsearé el código de sus fuentes, así será más fácil de entender que entender sobre el método Brown-Robinson y el vector Shackley, etc.
Publicaré los resultados con los datos y su modelo. Por ahora no es más que otra caja negra con publicidad simple, de las que hay decenas de miles, y lo siento, pero no puedo permitirme pasar una semana analizándola, sin pruebas de que no es peor que XGB.
HMM. Mozart suena orgulloso. Sin embargo, es la preparación de lo dado y la elección de la variable de salida lo que juega un papel IMPORTANTE. Cómo sé que sus entradas son un buen ajuste para la descripción de salida. PERO como se suele decir, es el optimizador el que determinará lo bien que se ajustan tus entradas a la salida. La cuestión es la siguiente. Puedo seleccionar entradas que interpreten bien la salida en el conjunto de entrenamiento, pero las entradas tendrán un rendimiento pobre en el OOS. Esto sugiere que la entrada no es la causa de la salida. Otra cosa es cuando la entrada es la causa de la salida, entonces el rendimiento de la red en el entrenamiento y en el OOS será el mismo. Tenga en cuenta lo siguiente.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Artículo publicado Sistema secuencial de Tom DeMark (TD SEQUENTIAL) con uso de inteligencia artificial:
En este artículo voy a contar sobre cómo se puede tradear con éxito aplicando la «hibridación» de una estrategia muy famosa y una red neuronal. Se trata de la estrategia de Tom DeMark «Sistema secuencial» (TD Sequential), con aplicación de la inteligencia artificial. Nosotros vamos a trabajar SÓLO con la primera parte de la estrategia, usando las señales «Disposición» y «Intersección».
Hay dos soluciones del problema de clasificación del estado «no sé». Veamos la siguiente imagen. Tenemos las señales en las que la ausencia de flechas significa nuestro «no sé», dos redes en círculo las han interpretado de diferentes maneras. En las imágenes, estas señales están marcadas como 1 y 2, además la primera señal tiene que ser falsa, para que se pueda ganar en ella.
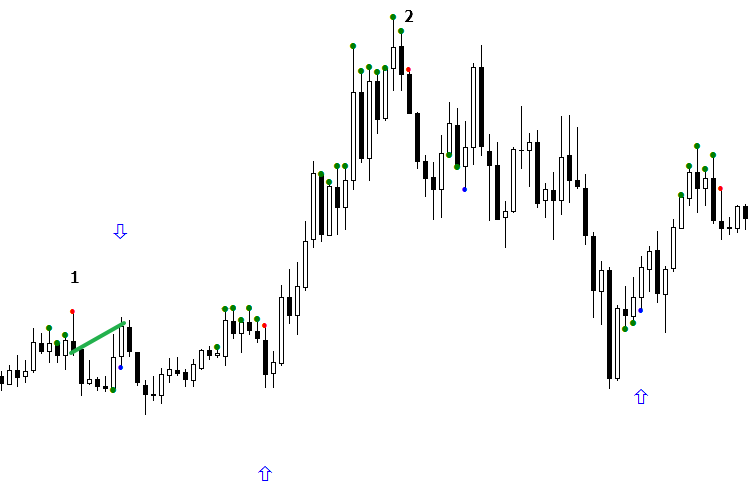
Fig. 6. Método para organizar la orientación de la señal según el contexto del díaAutor: Mihail Marchukajtes