Hearst index - page 22
You are missing trading opportunities:
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
Registration
Log in
You agree to website policy and terms of use
If you do not have an account, please register
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
I am confused by your "Not a single workable one." after the words "... and in the literature". There are many different approaches in the literature that give slightly different results from each other, which is not surprising as they are all estimates. However, it is also true that the larger the sample, the more accurate these estimates should be and the more "equal" they are to each other. I would only agree that a workable Hurst algorithm is hard to find on the forums.
As for what to feed to the input of the algorithm, the algorithm doesn't care. Feed the price and you'll get something around one. Indeed, for the essence of the algorithm the price has a strong long-term memory, because it stays relatively far from the original values. Feed price increments - you get something like 0.5, which again is justified, because their relative changes are large and almost random. Feed trends and/or cycles - get persistence. Noise generally reduces the index. I see that the question, "is our price noisy or a fair market price?" is not the subject of Hearst's algorithm, that is another realm.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
In general, the longer the better. According to the algorithm in Peters' book, the length that has the greatest number of integer divisors is better.
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
Two models are distinguished:
1. The process has a "stable" Hurst index. That is, the index is a constant and does not change in time (during the whole existence of the process). In this case, its definition is taken as a minimum - a statistically significant segment - i.e. a segment which allows to make a confident estimate of the distribution of the process. Or without bothering - as large a segment as possible.
2. The indicator is some function, possibly very complex, possibly random. In this case, there are no objective criteria for selecting the BP length. Estimating the index for the general case is impossible in either the time or frequency domain, unless you are a psychic.
Importantly, RS analysis is one of the crudest methods, its estimation is always biased and the sample size will not help in any way. To get a correct calculation of the Hurst index, use wavelet-based estimation (the algorithm can be found in mathlab, for example).
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
Hearst for price is ~1, but here what?
The only thing I can help in this case is to point out that there is no Hearst or R/S analysis in the _hurst_classik file. The point of the name "R/S" itself is to rescale the row. But the _hurst_classik that has a pretension to _RS_Analiz does not re-mastering, but, for example, trivially takes the difference between the maximum and minimum prices.
Moreover, R/S analysis, in order to reach Hearst, calculates the slope of the curve and for this it needs many points on the plane log(R/S) - log(n) instead of one. In this miracle _RS_Analiz there is no such thing.
The main point of my post was "identify BP model", but that didn't catch your attention.
If we are talking about ARFIMA-class models or something like that, I am really not interested, because these models are growing "nakuya", the purpose of which is to raise money for investment funds. Such "science" is called armchair science because it is created only for the sake of tweaking the scientific basis for a known desired result, usually a price prediction.
If we are talking about ARFIMA-class models or something like that, I am really not interested, because these models are growing "naqui", the purpose of which is to raise money for investment funds. Such "science" is called cabinet science because it is created only for the sake of fitting a scientific framework to a deliberately desired result, usually a price prediction.
Let's not make estimates. We are now talking about approaches using the BP model and not using it at all.HELP CALCULATE HEARST INDICATOR!!!*
*small remark: like Peters
I read the whole thread from beginning to end: yes, I did not expect that everyone, from respected academic men to ordinary onlookers have their own opinion on what Hirst is, and how it should be counted and interpreted. The closest to the original was Eric Nyman in his article and book. But... we (in Russia so to speak) still don't have an adequate tool for generating graphs, which are presented in Peters's book.
So, I have tried to mimic as closely as possible the sequence of steps that Peters described in his first book: "Chaos and Order in the Capital World", to calculate the R/S statistics for the S&P 500.
1. we take monthly charts of S&P 500 from 01.01.1950 to 01.07.1988.
2. We load them into the technical analysis program (I use WealthLab and C#, here and further I will use the WL/C# code)
3. Convert prices into returns using the formula from Peters book: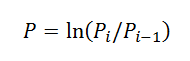
4. Peters himself does not mention that once the returns are calculated, they are converted back into an accumulated series: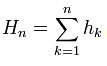 . However, this is obvious, based on those R/S spread values which he has, besides the source also explicitly states it, I quote: "For each natural n let us compose the values (see above formula) and compute the following numerical characteristics of the resulting subsequence".
. However, this is obvious, based on those R/S spread values which he has, besides the source also explicitly states it, I quote: "For each natural n let us compose the values (see above formula) and compute the following numerical characteristics of the resulting subsequence".
5. We divide the resulting series into k periods, the length of each period being N from 6 to 231 months or observations.
6. Now here is an important point. If the integer number of periods is not obtained (unused data remains), they are discarded. However, if the remainder is too large (e.g. 462 / 232 = 233 and 230 in the remainder) an incorrect value is obtained. My understanding is that Peters uses shifts, however this is a very fiddly option in terms of programming and I simply discard the period if its residual is greater than 6. Since adjacent periods have almost the same R/S value this is the correct option.
7. R is then calculated using the formula:
8. R is divided by the standard deviation (calculated by the WL indicator) and logarithmic: log10(R/S).
9. The current period is logarithmed: log10(N);
10. The obtained ratio log10(R/S) to log10(N) is written to the file.
If the optimizer goes through N from 6 (like Peters) to 231 (minimum number of experiments is 2), then we get a table of two columns in double logarithmic scale: 1. period 2. value of R/S.
Now begins the most interesting part. If you plot this table in Excel, the following will come out:
The original is presented on the right. As you can see, there is some similarity, but still not the same. In particular, the initial figure turns out to be slightly overestimated (0.33 vs. about 0.31), and secondly, the final values suddenly start to fall drastically, which should not be the case in principle. According to his graph, only the slope angle should change at the end of the series, telling us that the memory effect is limited.
So far I have stopped at this point. I haven't decided to apply U/V statistics yet, given only partial overlap with the original.
Converting R/S scores to Hearst also gives somewhat inflated results. If the Hearst figure is: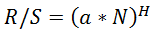 , then using the Excel formula we get LOG(HERST(10;B1);C1*0.5), where B1 is the current R/S score.
, then using the Excel formula we get LOG(HERST(10;B1);C1*0.5), where B1 is the current R/S score.
Below is the WL/C# code that calculates the R/S statistics:
p.s. Funny, MQL4 doesn't have keywords like overide and using, but the syntax still highlights them:)Is there a calculation of the Hurst index in Matcad (need formulas in discrete form)?
So far I have only found this
File with approaches to time series analysis attached. I took these formulas from there.
Sorry, of course.
Is it interesting? Looking at these formulas I do not see the sense in applying them to Forex.
It's easier to draw up a series that describes forex. It's already out there, people have won Nobel prizes for it. But the result is very averaged. It is necessary always to estimate the average first - the error, and then try to remove the minuses from the probability in connection with the errors, and then to bother with it.
Sorry, of course.
So, is it interesting? Looking at the formulas - I don't see the point in applying them to forex at all.
It's easier to throw up a series yourself that will describe forex. It already exists, people took a Nobel Prize for it. But the result is very, very averaged. First it is necessary always to estimate the average - the error, and then try to remove the minuses from the probability in connection with the errors, and then to bother with it.
Sorry. But for the future, let's agree not to post idle musings in this thread. Some are interested in "forex row", some in Hearst's statistics. Let everyone have their own thread.
I'm posting a CSV type table in double logarithmic scale: estimate R/S to period.