文章 "神经网络变得轻松(第二十九部分):优势扮演者-评价者算法"
你好,德米特里
非常感谢您详尽且极具启发性的系列文章。做得非常好。
只有一个问题:从您上一篇文章(#29)的附件中下载了所有代码后,我无法编译,因为缺少 CBufferDouble 类的定义,我想它应该在
NeuroNet_DNG\NeuroNet.mqh
但是没有。
我是不是漏掉了什么?
谢谢!
致以最崇高的敬意
保罗
你好,德米特里、
这个系列很棒,我是它的忠实粉丝。我也试着编译了 Reinforce EA,发现它也需要 aunto-encoder(当然),所以我添加了最后一个版本(来自第 22 篇)的 VAE.mqh,但由于某些原因,它找不到 Normal.mqh 定义:
![]()
我肯定我做错了什么,希望您能帮忙。
谢谢!
你好,德米特里、
这个系列很棒,我是它的忠实粉丝。我也试着编译了 Reinforce EA,发现它也需要 aunto-encoder(当然),所以我添加了最后一个版本(来自第 22 篇)的 VAE.mqh,但由于某些原因,它找不到 Normal.mqh 定义:
我肯定我做错了什么,希望您能提供帮助。
干杯
您好,请在本文中加载最后一个版本https://www.mql5.com/ru/articles/11804
: Полностью параметризированная квантильная функция")
- www.mql5.com
感谢 Dmitriy 的快速回复、提供的帮助和宝贵的时间,但我还是得到了同样的结果。
似乎 FQF-learning 调用 FQF.mqh
这反过来又调用了 NeuroNet...
当然,最后一个调用的是 VAE.mqh
而我能找到的唯一版本是第 22 篇中的那个...
使用该版本最终导致 VAE 找不到 Normal.mqh 函数的引用
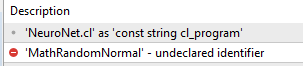
会不会是我的编辑器版本出了问题?

谢谢。
......出于某种原因,如果从 NeuroNet 调用 Normal 库,在 VAE.mqh 上是无法访问的,我真的不知道为什么(我在两个不同的版本上都试过)...
因此,我在 VAE 和 Neuronet 上直接添加了对 Normal 的调用,但不得不删除 FQF 上的数学空间,从而解决了这个问题:
很奇怪......但还是成功了:
执行以下语句时,由于没有 EURUSD_PERIOD_H1_REINFORCE.nnw,初始化失败
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) |||!
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
返回 INIT_FAILED;
如何解决这个问题?谢谢。
警告"...隐藏方法调用... "的另一种解决方案
在 Actor_Critic.mq5 的第 327 行:

我收到了 "已过时的行为,隐藏方法调用将在未来的 MQL 编译器版本中禁用 "的警告:

这是指 "Maximum(0, 3) "的调用,必须改为 "Maximum(0, 3)":

因此,在这种情况下,我们必须添加 "CArrayFloat:: "来指定所指的方法。最大值()方法被 CBufferFloat 类覆盖,但这个方法没有参数。
虽然调用应该是明确的,因为它有两个参数,但编译器还是希望我们能意识到这一点;-)
执行以下语句时,由于没有 EURUSD_PERIOD_H1_REINFORCE.nnw,初始化失败
if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) |||
!Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false))
返回 INIT_FAILED;
如何解决这个问题?谢谢。
在这些行中,加载了应该训练的网络结构。在启动 EA之前 ,您必须先构建网络并将其保存到指定文件中。例如,您可以使用第 23 条中的模型构建工具
: Practicing Transfer Learning")
- www.mql5.com
新文章 神经网络变得轻松(第二十九部分):优势扮演者-评价者算法已发布:
在本系列的前几篇文章中,我们见识到两种增强的学习算法。 它们中的每一个都有自己的优点和缺点。 正如在这种情况下经常发生的那样,接下来的思路是将这两种方法合并到一个算法,使用两者间的最佳者。 这将弥补它们每种的短处。 本文将讨论其中一种方法。
针对前几篇文章中的模型进行附加训练的好处是,我们可用上一篇文章中的测试 EA 来检查它们的训练结果。 这就是我如何做的。 训练模型之后,我采用了额外训练的策略模型,并利用上述模型在策略测试器中启动了 “REINFORCE-test.mq5” EA。 它的算法在上一篇文章中已进行了讲述。 其完整代码可在附件中找到。
下面是测试期间 EA 的余额图形。 如您所见,在测试期间,余额均匀增长。 请注意,模型是基于训练样本之外的数据上进行测试的。 这表明构建交易系统的方式是一致的。 测试仅针对模型,故所有操作均以固定的最小手数执行,且不用止损和止盈。 强烈建议不要在实盘交易中使用这样的 EA。 它仅仅是演示经过训练的模型如何工作。
在价格图表上,您可以看到亏损交易会快速平仓,而盈利持仓则会持有一段时间。 所有操作均在新烛条开盘时执行。 您还可以注意到,若干交易操作几乎是在反转(分形)烛条开盘时就执行了。
作者:Dmitriy Gizlyk