Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами. Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
_Forex19_>>: Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда. Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы. Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо! PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
using System;
using System.Collections.Generic;
using System.Text;
using System.Drawing;
using System.IO;
using WealthLab;
using WealthLab.Indicators;
namespace WealthLab.Strategies
{
publicclass PetersHerst : WealthScript
{
public StrategyParameter Period;
publicstring path = @"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv";
public PetersHerst()
{
//StreamWriter sw = new System.IO.StreamWriter(path);
Period = CreateParameter("Period", 6, 6, 240, 1);
if(File.Exists(path))File.Delete(path);
}
protectedoverridevoid Execute()
{
int N = Period.ValueInt;
// Так как мы преобразуем исходный ряд в доходности, то количество наблюдений у нас будет на 1 меньше, чем баров на графике.// Отслеживаем, что бы количество отброшенных данных не превышало 6 наблюдений.// Если отбрашиваемых данных слишком много,то период выбран неудачно, и расчет R/S статистики для него не производится.int ost = Bars.Count - 1 - (int)Math.Floor((double)(Bars.Count-1)/N)*N;
if(ost > 6)
{
PrintDebug("Слишком много пропущенных данных (" + ost + "). Необходимо выбрать другой период.");
return;
}
//PrintDebug("Пропущенных данных для рассчета");
DataSeries Returns = new DataSeries("Returns");
DataSeries ret2price = new DataSeries("ret2proce");
// Расcчитываем логарифмические доходности// и собираем из них накопленный ряд.
Returns.Add(0.0, Date[0]);
double acum = 0.0;
for(int i = 1; i < Bars.Count; i++)
{
acum += Math.Log(Close[i]/Close[i-1]);
Returns.Add(Math.Log(Close[i]/Close[i-1]), Date[i]);
ret2price.Add(acum, Date[i]);
}
//ret2price.
PrintDebug(ret2price.Count);
if(Returns.Count < 1)return;
if(N > ret2price.Count)N = ret2price.Count;
double logRS = 0.0;
int count=0; //количество периодов
PrintDebug(Bars.Count);
for(int i = 0; i < ret2price.Count; i++)
{
//Делим ряд на K групп по N доходностей в каждойif((i+1)%N == 0)
{
count++;
if(i - N < 0)continue;
//Находим среднее значение sma или математическое ожидание доходностей за период kdouble sma = SMA.Value(i, ret2price, N);
//Находим стандартное отклонение за период kdouble S = StdDev.Value(i, ret2price, N, WealthLab.Indicators.StdDevCalculation.Sample);
//Находим накопленную разницу между текущим значением и средним.double s = 0.0;
DataSeries acum_div = new DataSeries("");
for(int k = i - N+1; k <= i; k++)
{
s += (ret2price[k] - sma);
//Не учитываем последнее значение, т.к. оно всегда будет равно нулю.//if(k!=i)
acum_div.Add(s);
//PrintDebug(Returns.Date[k].ToShortDateString() +"\tret: "+ Returns[k].ToString("F6") + "\tStd: " + S.ToString("F6") + "\t" + s.ToString("F6"));
}
double R = acum_div.MaxValue - acum_div.MinValue;
//Конечная оценка log(R/S)
logRS += Math.Log(R/S, 10);
//PrintDebug(Returns.Date[i].ToShortDateString() + "\t" + "SMA: " + sma.ToString("F6")// + "\tStd: " + S.ToString("F6") + "\tMaxV: " + acum_div.MaxValue.ToString("F6") +// "\tMinV: " + acum_div.MinValue.ToString("F6")// + "\tR: " + R.ToString("F6") + "\tlog(R/S): " + logRS.ToString("F6"));
}
}
logRS /= count;
double logPeriod = Math.Log(N, 10);
PrintDebug(logPeriod + "\t" + logRS + "\tCount:" + count);
if(count >= 2)
File.AppendAllText(@"c:\Users\Василий\Documents\Wealth-Lab\Reports\Strategys\Herst\herst.csv", logPeriod + "\t" + logRS + "\n");
}
}
}
Не знаю. Для начала надо идентифицировать модель ВР. В ней могут быть тренды, циклы, шум, причем с разными параметрами - от рабочих до таких, в которых модель не работоспособна. Бокс рассматривает несколько моделей с разным набором параметров. Если взять хотя бы то, что он идентифицировал Бокс и для них посчитать Херста - это будет один и тот же херст или это будут разные, с разными величинами или алгоритмами.
Я видел попытки посчитать Херста на нескольких форумах и в литературе. Ни одного работоспособного. Это навело на выше приведенные мысли.
我对你在"...... "之后说的 "没有一个可行的 "感到困惑。和文献中"。文献中有许多不同的方法,彼此给出的结果略有不同,这并不奇怪,因为它们都是估计。然而,同样的事实是,样本越大,这些估计应该越准确,它们之间的关系也越 "平等"。我只同意,在论坛上很难找到一个可行的赫斯特算法。
至于向算法的输入输入什么,算法并不关心。馈赠价格,你会得到一个左右的东西。事实上,对于算法的本质来说,价格有很强的长期记忆,因为它与原始值保持相对较远的距离。饲料价格增量--你得到的是0.5这样的东西,这又是合理的,因为它们的相对变化很大,几乎是随机的。供给趋势和/或周期--获得持久性。噪声一般会降低指数。我看到,"我们的价格是嘈杂的还是公平的市场价格?"这个问题不是赫斯特算法的主题,那是另一个境界。
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
一般来说,时间越长越好。根据彼得斯书中的算法,整数除数最多的长度更好。
Подскажите пожалуйста, каким образом в RS-анализе выбирается длина анализируемого ВР.
有两种模式可以区分。
1.该过程有一个 "稳定的 "Hurst指数。也就是说,该指数是一个常数,在时间上不发生变化(在整个过程的存在期间)。在这种情况下,它的定义是作为一个最低限度的--统计上有意义的部分--即允许对过程的分布作出有把握的估计的部分。或者不费吹灰之力--尽可能大的部分。
2.该指标是一些函数,可能非常复杂,也可能是随机的。在这种情况下,没有选择BP长度的客观标准。无论是在时域还是频域,估计一般情况下的指数都是不可能的,除非你是个通灵者。
重要的是,RS分析是最粗糙的方法之一,它的估计总是有偏差的,样本量不会有任何帮助。为了得到Hurst指数的正确计算,请使用基于小波的估计(例如,在mathlab中可以找到该算法)。
Добрый день!С большим вниманием читала данную ветку, так как интересуюсь данной тематикой, хотя в этих вопросах я еще новичок. В ходе своего исследования показателя Херста интересует реализация следующей задачи: необходимо определить эффективность индикатора iVAR, _hurst_classik для финансового ряда.
Мое видение реализации данной задачи следующее: необходимо сделать индикатор, который бы на основе данных индикатора ZigZag, рассчитал расстояние d1 (количество баров) между двумя соседними точками (минимумам и максимумам), а также получить расстояние d2 (количество точек за соответствующий интервал), который дает индикатор iVAR(множество значений меньше 0,5 в случаи индекса вариации) и индикатор _hurst_classik (множество значений больше 0,5 в случаи показателя Херста ). В конечном итоге получить массив отношений d2/d1. Конечный результат представить в виде гистограммы.
Надеюсь на этом сайте есть джентльмен - программисты на MQL4,которые помогут девушке в ее исследовании, буду рада любой помощи!За ранее огромное спасибо!
PS: хотя индикатор ZigZag является трендовым, возможно какое-то программное решение с флэтом. Если существуют какие-то готовые инструменты для решение данной задачи, прошу их указать. Кроме того повторно выкладываю коды индикаторов iVAR и _hurst_classik.
赫斯特的价格是~1,但这里是什么?
在这种情况下,我唯一能帮助的是指出_hurst_classik文件中没有赫斯特或R/S分析。名称 "R/S "本身的意义在于重新划分行的规模。但是,与_RS_Analiz相提并论的_hurst_classik文本并不包含任何重映射,而是,例如,微不足道地采取最高和最低价格之间的差异。
此外,R/S分析,为了达到赫斯特,计算曲线的斜率,为此它需要在平面log(R/S)-log(n)上的许多点而不是一个。在这个奇迹_RS_Analiz中,没有这样的事情。
我的帖子的主要观点是 "确定BP模型",但这并没有引起你的注意。
如果我们谈论的是ARFIMA类模型或类似的东西,我真的不感兴趣,因为这些模型正在成长的 "nakuya",其目的是为投资基金筹集资金。这样的 "科学 "被称为内阁科学,因为它只是为了调整已知的预期结果,通常是价格预测的科学基础而创造的。
如果我们谈论的是ARFIMA类模型或类似的东西,我真的不感兴趣,因为这些模型正在成长为 "naqui",其目的是为投资基金筹集资金。这样的 "科学 "被称为内阁科学,因为它只是为了将科学框架装入一个刻意想要的结果,通常是价格预测而创造的。
我们不要做估计。我们现在谈论的是使用BP模型和根本不使用BP模型的方法。帮助计算赫斯特指标!!! *
*小编说: 像彼得斯
我从头到尾读了整个主题:是的,我没有想到,每个人, 从受人尊敬的学者到普通的旁观者都对赫斯特是什么,以及应该如何计算和解释有自己的看法。最接近原作的是埃里克-尼曼在他的文章 和书 中。但是...我们(可以说是在俄罗斯)仍然没有一个足够的工具来生成图形,这在彼得斯的书中有介绍。
因此,我试图尽可能地模仿彼得斯在他的第一本书《资本世界的混沌与秩序》中描述的步骤顺序,来计算标准普尔500指数的R/S统计数据。
1.我们从1950年1月1日至1988年7月1日的标准普尔500指数的月度图表。
2.我们将它们加载到技术分析程序中(我使用WealthLab和C#,在这里和进一步我将使用WL/C#代码)。
3.使用彼得斯书中的公式将价格转换成收益: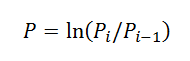
4.彼得斯本人没有提到,一旦计算出回报率,就会被转换回一个累积系列: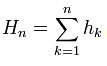 。然而,这是显而易见的,根据他的那些R/S传播值,此外,来源 也明确指出,我引用。"对于每个自然数n,让我们对其数值进行组合(见上述公式),并计算所产生的子序列的以下数字特征"。
。然而,这是显而易见的,根据他的那些R/S传播值,此外,来源 也明确指出,我引用。"对于每个自然数n,让我们对其数值进行组合(见上述公式),并计算所产生的子序列的以下数字特征"。
5.我们将所得的系列划分为k个时期,每个时期的长度为6至231个月或观测值的N。
6.现在,这里有一个重要的问题。如果没有得到整数的周期(未使用的数据仍然存在),它们将被丢弃。然而,如果余数过大(例如462/232=233,余数为230),就会得到一个错误的值。我的理解是Peters使用了移位,然而在编程方面这是一个非常麻烦的选项,如果周期的剩余值大于6,我就简单地丢弃它。由于相邻时期的R/S值几乎相同,所以这是一个正确的选项。
7.然后用公式计算R。
8.R除以标准差(由WL指标计算),对数:log10(R/S)。
9.当前的周期是对数的:log10(N)。
10.得到的对数10(R/S)与对数10(N)的比率被写进文件。
如果优化器将N从6(如Peters)到231(最小实验数为2),那么我们得到一个双对数比例的两列表格:1.周期2.R/S的值。
现在开始最有趣的部分。如果你在Excel中绘制这个表格,会得出以下结果。
原作呈现在右边。正如你所看到的,有一些相似之处,但仍然不一样。特别是,最初的数字被稍微高估了(0.33对0.31左右),其次,最终值突然开始急剧下降,这在原则上不应该是这样的。根据他的图表,只有斜率角在系列结束时应该发生变化,告诉我们记忆效应是有限的。
到目前为止,我已经在这一点上停止了。鉴于与原作只有部分重叠,我还没有决定应用U/V统计。
将R/S分数转换为Hearst分数也会得到一些夸大的结果。如果赫斯特的分数是。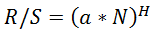 ,然后用Excel公式得到LOG(HERST(10;B1);C1*0.5),其中B1是当前的R/S得分。
,然后用Excel公式得到LOG(HERST(10;B1);C1*0.5),其中B1是当前的R/S得分。
下面是计算R/S统计的WL/C#代码。
p.s. 有趣的是,MQL4没有像overide和using这样的关键词,但语法上仍然突出了它们:)在Matcad中是否有Hurst指数的计算方法(需要离散形式的公式)?
到目前为止,我只发现了这个
附有时间序列分析方法的文件。我从那里得到了这些公式。
当然,对不起。
有意思吗?看看这些公式,我不认为将它们应用于外汇有什么意义。
拟定一个描述外汇的系列是比较容易的。它已经在那里了,人们已经为它赢得了诺贝尔奖。但结果是非常平均的。总是有必要先估计平均数--误差,然后尝试从与误差有关的概率中去除减分,然后再去管它。
当然,对不起。
那么,它有趣吗?看看这些公式--我完全看不出将它们应用于外汇有什么意义。
自己抛出一个能描述外汇的系列是比较容易的。它已经存在了,人们为此拿了一个诺贝尔奖。但结果是非常、非常平均的。首先总是需要估计平均数--误差,然后试图从与误差有关的概率中去除减分,然后再去管它。
对不起。但为了将来,让我们同意不在这个主题中发表闲聊。有些人对 "外汇行 "感兴趣,有些人对赫斯特的统计数据感兴趣。让每个人都有自己的主题。
我发布了一个CSV类型的表格,采用双对数比例:估计R/S到周期。