Algoritmaların optimizasyonu.
joo
Başlamak için, kodu şuraya getirmeniz gerektiğini düşünüyorum:
1. Derlenmiş görünüm.
2. Okunabilir.
3. Yorumlar.
Prensip olarak, konu ilginç ve acildir.
joo
Başlamak için, kodu şuraya getirmeniz gerektiğini düşünüyorum:
1. Derlenmiş görünüm.
2. Okunabilir.
3. Yorumlar.
TAMAM.
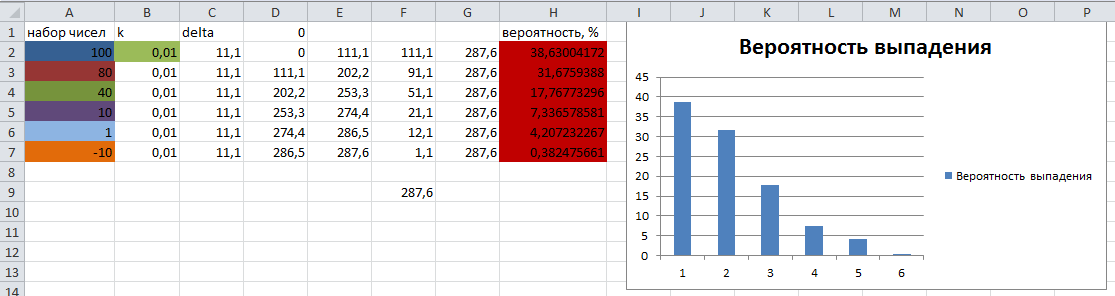
Sıralanmış bir gerçek sayı dizimiz var. Hayali rulet sektörünün boyutuna karşılık gelen olasılıkla diziden bir hücre seçmek gerekir.
Sayıların test seti ve teorik olarak düşme olasılıkları Excel'de hesaplandı ve algoritmanın sonuçlarıyla karşılaştırma için aşağıdaki şekilde sunuldu:
Algoritma yürütmenin sonucu:
2012.04.04 21:35:12 Rulet (EURUSD,H1) h0 38618465 38.618465
2012.04.04 21:35:12 Rulet (EURUSD,H1) h1 31685360 31.68536
2012.04.04 21:35:12 Rulet (EURUSD,H1) h3 7334754 7.334754
2012.04.04 21:35:12 Rulet (EURUSD,H1) h4 4205492 4.205492
2012.04.04 21:35:12 Rulet (EURUSD,H1) h5 385095 0.385095
2012.04.04 21:35:12 Rulet (EURUSD,H1) 12028 ms - Yürütme süresi
Gördüğünüz gibi, ilgili sektöre düşen bir "top" olasılığının sonuçları pratik olarak teorik olarak hesaplananlarla örtüşüyor.
#property script_show_inputs //--- input parameters input int StartCount= 100000000 ; // Границы соответствующих секторов рулетки double select1[]; // начало сектора double select2[]; // конец сектора //—————————————————————————————————————————————————————————————————————————————— void OnStart () { MathSrand (( int ) TimeLocal ()); // сброс генератора // массив с тестовым набором чисел double array[ 6 ]={ 100.0 , 80.0 , 40.0 , 10.0 , 1.0 ,- 10.0 }; ArrayResize (select1, 6 ); ArrayInitialize (select1, 0.0 ); ArrayResize (select2, 6 ); ArrayInitialize (select2, 0.0 ); // счетчики для подсчета выпадений соответствующего числа из тестового набора int h0= 0 ,h1= 0 ,h2= 0 ,h3= 0 ,h4= 0 ,h5= 0 ; // нажмём кнопочку секундомера int time_start=( int ) GetTickCount (); // проведём серию испытаний for ( int i= 0 ;i<StartCount;i++) { switch (Roulette(array, 6 )) { case 0 : h0++; break ; case 1 : h1++; break ; case 2 : h2++; break ; case 3 : h3++; break ; case 4 : h4++; break ; default : h5++; break ; } } Print (( int ) GetTickCount ()-time_start, " мс - Время исполнения" ); Print ( "h5 " ,h5, " " ,h5* 100.0 /StartCount); Print ( "h4 " ,h4, " " ,h4* 100.0 /StartCount); Print ( "h3 " ,h3, " " ,h3* 100.0 /StartCount); Print ( "h1 " ,h1, " " ,h1* 100.0 /StartCount); Print ( "h0 " ,h0, " " ,h0* 100.0 /StartCount); Print ( "----------------" ); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Рулетка. int Roulette( double &array[], int SizeOfPop) { int i= 0 ,u= 0 ; double p= 0.0 ,start= 0.0 ; double delta=(array[ 0 ]-array[SizeOfPop- 1 ])* 0.01 -array[SizeOfPop- 1 ]; //------------------------------------------------------------------------------ // зададим границы секторов for (i= 0 ;i<SizeOfPop;i++) { select1[i]=start; select2[i]=start+ MathAbs (array[i]+delta); start=select2[i]; } // бросим "шарик" p=RNDfromCI(select1[ 0 ],select2[SizeOfPop- 1 ]); // посмотрим, на какой сектор упал "шарик" for (u= 0 ;u<SizeOfPop;u++) if ((select1[u]<=p && p<select2[u]) || p==select2[u]) break ; //------------------------------------------------------------------------------ return (u); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Генератор случайных чисел из заданного интервала. double RNDfromCI( double min, double max) { return (min+((max-min)* MathRand ()/ 32767.0 ));} //——————————————————————————————————————————————————————————————————————————————
TAMAM.
Sıralanmış bir gerçek sayı dizimiz var. Hayali rulet sektörünün boyutuna karşılık gelen olasılıkla diziden bir hücre seçmek gerekir.
"Sektör genişliğini" ayarlama ilkesini açıklayın. Dizideki değerlerle eşleşiyor mu? Yoksa ayrı mı ayarlanıyor?
Bu en karanlık soru, diğer her şey sorun değil.
İkinci soru: 0.01 sayısı nedir? Nereden alınır?
Kısaca: Düşen sektörlerin doğru olasılıklarını nereden alacağımı söyleyin (çevrenin kesirleri cinsinden genişlik).
Her sektörü sadece boyutlandırabilirsiniz. Negatif boyutların doğada mevcut olmaması (varsayılan olarak) şartıyla. Kumarhanede bile. ;)
"Sektör genişliğini" ayarlama ilkesini açıklayın. Dizideki değerlerle eşleşiyor mu? Yoksa ayrı mı ayarlanıyor?
Sektörlerin genişliği dizideki değerlerle eşleşemez, aksi takdirde algoritma hiçbir sayı için çalışmayacaktır.
Rakamların birbirleri arasındaki mesafe önemlidir. Tüm sayılar ilkinden ne kadar uzaksa, düşme olasılıkları o kadar az olur. Aslında, 0,01 faktörüyle ayarlanmış sayılar arasındaki mesafelerle orantılı sayısal bir düz çizgi parçaları ayırdık, böylece son sayının düşme olasılığı ilkinden en uzak olan 0'a eşit değil. Katsayı ne kadar yüksek olursa, sektörler o kadar eşit olur. Ekli excel dosyası, deneme.
MetaSürücü :
1. Kısaca: Düşen sektörlerin doğru olasılıklarını nereden alacağımı söyleyin (çevrenin kesirleri cinsinden genişlik).
2. Her sektörü sadece boyutlandırabilirsiniz. Negatif boyutların doğada mevcut olmaması (varsayılan olarak) şartıyla. Kumarhanede bile. ;)1. Teorik olasılıkların hesaplanması Excel'de verilmiştir. İlk sayı en yüksek olasılıktır, son sayı en düşük olasılıktır ancak 0'a eşit değildir.
2. Kümenin azalan düzende sıralanması koşuluyla, hiçbir sayı kümesi için negatif sektör boyutları asla olmaz - ilk sayı en büyüktür (kümedeki en büyük sayıyla ancak negatif bir sayıyla çalışır).
Sektörlerin genişliği dizideki değerlerle eşleşemez, aksi takdirde algoritma hiçbir sayı için çalışmayacaktır.
zyu: Rakamların aralarındaki mesafe önemlidir. Tüm sayılar ilkinden ne kadar uzaksa, düşme olasılıkları o kadar az olur. Aslında, sayılar arasındaki mesafelerle orantılı sayısal bir düz çizgi segmentleri ayırdık 0.01 faktörü ile ayarlandı, böylece son sayının ilkinden en uzak olan 0'a eşit olmayan düşme olasılığı var. Katsayı ne kadar yüksek olursa, sektörler o kadar eşit olur. Ekli excel dosyası, deneme.
1. Teorik olasılıkların hesaplanması Excel'de verilmiştir. İlk sayı en yüksek olasılıktır, son sayı en düşük olasılıktır ancak 0'a eşit değildir.
2. Kümenin azalan düzende sıralanması koşuluyla, hiçbir sayı kümesi için negatif sektör boyutları asla olmaz - ilk sayı en büyüktür (kümedeki en büyük sayıyla ancak negatif bir sayıyla çalışır).
Şemanızda , "buldozerden", en küçük saat sayısı ( vmch ) olasılığında verilir. Hiçbir makul gerekçesi yoktur.
// Çünkü "haklı çıkarmak" zor. Her şey yolunda - N çivi arasında sadece N-1 boşluk var.
Bu nedenle, sizin için ( vmch ) "buldozerden" alınan "katsayıya" da bağlıdır. Neden 0.01? neden 0.001 değil?
Algoritmayı yapmadan önce, tüm sektörlerin "genişliğinin" hesaplanmasına karar vermeniz gerekir.
zyu: "Sayılar arasındaki mesafeleri" hesaplama formülünü verin. Hangi sayı "ilk"? Ne kadar uzakta? Excel'e gönderme, ben oradaydım. Orada ideolojik düzeyde her şey karışık. Düzeltme faktörü nereden geliyor ve neden tam olarak?
Kırmızı ile vurgulanan hiç doğru değil. :)
bu çok hızlı olacak:
int Selection() { return (RNDfromCI(1,SizeOfPop); }
Algoritmanın kalitesi bir bütün olarak etkilenmemelidir.
Ve biraz etkilese bile, hız nedeniyle bu seçenek kaliteyi geçecektir.
1. Şemanızda "buldozerden" sayıların en küçük olma olasılığı ( wmch ) verilmiştir. Makul bir gerekçe yok. Bu nedenle, sizin için ( vmch ) "buldozerden" alınan "katsayıya" da bağlıdır. Neden 0.01? neden 0.001 değil?
2. Algoritmayı yapmadan önce, tüm sektörlerin "genişliğinin" hesaplanmasına karar vermeniz gerekir.
3. zyu: "Sayılar arasındaki mesafeleri" hesaplama formülünü verin. Hangi sayı "ilk"? Ne kadar uzakta? Excel'e gönderme, ben oradaydım. Orada ideolojik düzeyde her şey karışık. Düzeltme faktörü nereden geliyor ve neden tam olarak?
4. Kırmızı ile vurgulananlar hiç doğru değil. :)
1. Evet, buldozerden. Bu oranı beğendim. Bir başkasını beğenirseniz, başka bir tane kullanırım - algoritmanın hızı değişmez.
2. Kesinlik sağlanmıştır.
3. Tamam. Sıralanmış bir sayı dizimiz var - en büyük sayının dizi[0] içinde olduğu dizi[] ve başlangıç noktası 0.0 olan bir sayı demeti (başka herhangi bir noktayı alabilirsiniz - hiçbir şey değişmez) ve pozitif olarak yönlendirilir yön. Kiriş üzerindeki segmentleri şu şekilde ayırın:
start0=0 end0=start0+|dizi[0]+delta|
start1=end0 end1=start1+|dizi[1]+delta|
start2=end1 end2=start2+|dizi[2]+delta|
......
start5=end4 end5=start5+|dizi[5]+delta|
nerede:
delta=(array[ 0 ]-array[5])* 0.01 -array[5];
Hepsi aritmetik. :)
Şimdi, işaretli kirişimize bir "top" atarsak, belirli bir parçaya çarpma olasılığı, bu parçanın uzunluğu ile orantılıdır.
4. Çünkü (hepinizi değil) tek tek ayırmadınız. Bunu şu şekilde vurgulamak gerekir: " Aslında, son sayının 0'a eşit olmayan düşme olasılığının olması için, 0,01 faktörü için ayarlanmış, sayılar arasındaki mesafelerle orantılı bir sayı doğrusu segmenti ayırdık. "
bu çok hızlı olacak:
int Selection() { return (RNDfromCI(1,SizeOfPop); }
Algoritmanın kalitesi bir bütün olarak etkilenmemelidir.
Ve biraz etkilese bile, hız nedeniyle bu seçenek kaliteyi geçecektir.
:)
Bir dizi öğesini rastgele seçmeyi mi öneriyorsunuz? - bu, dizinin sayıları arasındaki mesafeyi hesaba katmaz ve bu nedenle sürümünüz işe yaramaz.
- www.mql5.com
:)
Bir dizi öğesini rastgele seçmeyi mi öneriyorsunuz? - bu, dizinin sayıları arasındaki mesafeyi hesaba katmaz ve bu nedenle sürümünüz işe yaramaz.
kontrol etmek zor değil.
Kullanılamaz olduğu deneysel olarak doğrulandı mı?
Kullanılamaz olduğu deneysel olarak doğrulandı mı?
- Ücretsiz alım-satım uygulamaları
- İşlem kopyalama için 8.000'den fazla sinyal
- Finansal piyasaları keşfetmek için ekonomik haberler
Web sitesi politikasını ve kullanım şartlarını kabul edersiniz
Burada algoritma mantığının optimal inşası problemlerini tartışmayı öneriyorum.
Birisi algoritmasının hız (veya görünürlük) açısından en uygun mantığa sahip olduğundan şüphe ederse, hoş geldiniz.
Algoritma yapmak ve başkalarına yardım etmek isteyenleri de bu konuya davet ediyorum.
Sorumu ilk başta "Çaydan gelen sorular" başlığında sormuştum ama oraya ait olmadığını anladım.
Bu nedenle, lütfen "rulet" algoritmasının bundan daha hızlı bir versiyonunu önerin:
dizilerin her seferinde bildirilmemesi ve yeniden boyutlandırılmaması için fonksiyon dışına alınabileceği açık, ancak daha devrimci bir çözüme ihtiyacım var. :)