Bayesian regression - Делал ли кто советник по этому алгоритму? - страница 40
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
А моя душа все хочет копнуть тему якобы нормально распределенных приращений котировок.
Если кто-то выскажется "за", я приведу аргументы, почему этот процесс не может быть нормальным. Причем это будут понятные всем аргументы, которые при этом будут согласовываться с ЦПТ. И эти аргументы настолько банальны, что сомнений остаться не должно.
А вероятность что будет выражать, прогноз на ближайший бар, или вектор движения ближайших баров?
Вероятность будет выражать прогноз следующего тика ( приращения). Просто я хочу:
- вычислить величины будущих тиков Ybayes для которых вероятность по формуле Байеса будет максимальна.
- сравнить Ybayes с реально приходящими тиками Yreal . Собрать и обработать статистику .
Если разность величин будет в пределах разумного то выложу код и спрошу что делать дальше. Регрессию? Вектор? Кривульку? Скальпинг?
Вероятность будет выражать прогноз следующего тика ( приращения). Просто я хочу:
А зачем до тиков спускаться? Направления тиков можно за 5 минут нучиться прогнозировать с 70% точностью, но на 100 тиков вперед, сами понимаете, точность упадет.
Попробуйте приращения на полчаса или час вперед. Это и мне интересно, может и я помогу чем-то.
Вероятность будет выражать прогноз следующего тика ( приращения). Просто я хочу:
- вычислить величины будущих тиков Ybayes для которых вероятность по формуле Байеса будет максимальна.
- сравнить Ybayes с реально приходящими тиками Yreal . Собрать и обработать статистику .
Если разность величин будет в пределах разумного то выложу код и спрошу что делать дальше. Регрессию? Вектор? Кривульку? Скальпинг?
А чем не устраивает ARIMA? В пакетах количество дифферецирований (приращений приращений) вычисляется автоматически в зависимости от входного потока. Куча тонкостей, связанных со стационарностью, сокрыто внутри пакета.
Если уж так хочется углубиться, то какой-нибудь ARCH?
Когда-то пробовал. Проблема в следующем. Приращение можно вычислить запросто. Но если сложить доверительный интервал этого приращения с самим приращение, то ли BUY, то ли SELL, так как предыдущее значение цены попадает внутрь доверительного интервала.
Да, классический подход, как пишет СанСаныч, это анализ данных , требования к данным, про системные ошибки вспомнить.
Но эта ветка про Байеса и я пытаюсь мыслить по байесовски, как тот солдат в окопе вычисляющий апостериорную ( после опыта ) вероятность. Пример про солдата я приводил выше.
Один из главных вопросов, что принимать за априорную вероятность. Другими словами , кого ставить за занавес будущего, справа от нулевого бара. Гаусса? Лапласа? Винера ? То что пишут здесь профессиональные математики ( для меня тёмный "лес") ?
Выбираю Гаусса, т.к во первых имею представление о нормальном распределении , во вторых в него верю. Если не "выстрелит" то можно взять другие законы и подставить в формулу Байеса вместо Гаусса, или вместе с Гауссом как произведение двух вероятностей. Попытаться сделать байесовскую сеть, если я правильно её понимаю.
Естественно я это один не осилю. Мне бы с Гауссом справится в задаче которую я сформулировал под букетом. Если кто желает присоединится на общественных началах - милости прошу. Вот например актуальная задача.
Дано: Штатный генератор случайных чисел МТ4.
Нужно: Написать код MQL4 в виде функции FP() преобразования массива МТ4[] сформированного штатным ГСЧ в массив ND[] c нормальным распределением.
Формулы преобразования показал https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Василий (не знаю отчества) Соколов.
Верхом любезности и альтруизма будет графическое отображение результатов, хотя графики по вычисленным массивам могу и я могу замаштабировать прямо в окне МТ4. Занимался этим в своих проектах.
Я понимаю, что многие здесь двумя кликами решат эту задачу в мат. пакетах , но я хочу разговаривать на общедоступном для трейдеров, программистов, экономистов, философов - языке MQL4.
Да, классический подход, как пишет СанСаныч, это анализ данных , требования к данным, про системные ошибки вспомнить.
Но эта ветка про Байеса и я пытаюсь мыслить по байесовски, как тот солдат в окопе вычисляющий апостериорную ( после опыта ) вероятность. Пример про солдата я приводил выше.
Один из главных вопросов, что принимать за априорную вероятность. Другими словами , кого ставить за занавес будущего, справа от нулевого бара. Гаусса? Лапласа? Винера ? То что пишут здесь профессиональные математики ( для меня тёмный "лес") ?
Выбираю Гаусса, т.к во первых имею представление о нормальном распределении , во вторых в него верю. Если не "выстрелит" то можно взять другие законы и подставить в формулу Байеса вместо Гаусса, или вместе с Гауссом как произведение двух вероятностей. Попытаться сделать байесовскую сеть, если я правильно её понимаю.
Естественно я это один не осилю. Мне бы с Гауссом справится в задаче которую я сформулировал под букетом. Если кто желает присоединится на общественных началах - милости прошу. Вот например актуальная задача.
Дано: Штатный генератор случайных чисел МТ4.
Нужно: Написать код MQL4 в виде функции FP() преобразования массива МТ4[] сформированного штатным ГСЧ в массив ND[] c нормальным распределением.
Формулы преобразования показал https://www.mql5.com/go?link=https://habrahabr.ru/post/208684/ Василий (не знаю отчества) Соколов.
Верхом любезности и альтруизма будет графическое отображение результатов, хотя графики по вычисленным массивам могу и я могу замаштабировать прямо в окне МТ4. Занимался этим в своих проектах.
Я понимаю, что многие здесь двумя кликами решат эту задачу в мат. пакетах , но я хочу разговаривать на общедоступном для трейдеров, программистов, экономистов, философов - языке MQL4.
Здесь есть генератор с разными распределениями, в том числе и с нормальным:
https://www.mql5.com/ru/articles/273
Краткий анализ распределения на языке R:
# load data fx_data <- read.table('C:/EURUSD_Candlestick_1_h_BID_01.08.2003-31.07.2015.csv' , sep= ',' , header = T , na.strings = 'NULL') fx_dat <- subset(fx_data, Volume > 0) # create open price returns dat_return <- diff(x = fx_dat[, 2], lag = 1) # check summary for the returns summary(dat_return) Min. 1st Qu. Median Mean 3rd Qu. Max. -2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02 # generate random normal numbers with parameters of original data norm_generated <- rnorm(n = length(dat_return), mean = mean(dat_return), sd = sd(dat_return)) #check summary for generated data summary(norm_generated) Min. 1st Qu. Median Mean 3rd Qu. Max. -8.013e-03 -1.166e-03 -7.379e-06 -7.697e-06 1.152e-03 7.699e-03 # test normality of original data shapiro.test(dat_return[sample(length(dat_return), 4999, replace = F)]) Shapiro-Wilk normality test data: dat_return[sample(length(dat_return), 4999, replace = F)] W = 0.86826, p-value < 2.2e-16 # test normality of generated normal data shapiro.test(norm_generated[sample(length(norm_generated), 4999, replace = F)]) Shapiro-Wilk normality test data: norm_generated[sample(length(norm_generated), 4999, replace = F)] W = 0.99967, p-value = 0.6189Мы оценили параметры нормального распределения по имеющимся приращениям цен открытия часовых баров и отобразили для сравнение частоты и плотности для оригинального ряда и нормального с теми же распределениями. Как видно даже глазками, ориниальный ряд приращений часовых баров далеко не нормальный.
И, кстати, мы же не в храме Божьем. Верить необязательно и даже вредно.
Вот любопытная строчка из поста выше, которая перекликается с тем что писал выше
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
Насколько я понимаю в квадрантах, 50% всех приращений на часовике менее 7 пипсов! А более приличные приращения находятся в толстых хвостах, т.е. по ту сторону добра и зла.
И как будет выглядеть ТС? В этом вся проблема, а не в байесах и прочая, прочая...
Или надо понимать как-то по другому?
Вот любопытная строчка из поста выше, которая перекликается с тем что писал выше
-2.515e-02 -6.800e-04 0.000e+00 -3.400e-07 6.900e-04 6.849e-02
Насколько я понимаю в квадрантах, 50% всех приращений на часовике менее 7 пипсов! А более приличные приращения находятся в толстых хвостах, т.е. по ту сторону добра и зла.
И как будет выглядеть ТС? В этом вся проблема, а не в байесах и прочая, прочая...
Или надо понимать как-то по другому?
СанСаныч, да!
plot(y = hour1_quantiles$value, x = hour1_quantiles$probability, main = 'Quantile values for EURUSD H1 returns')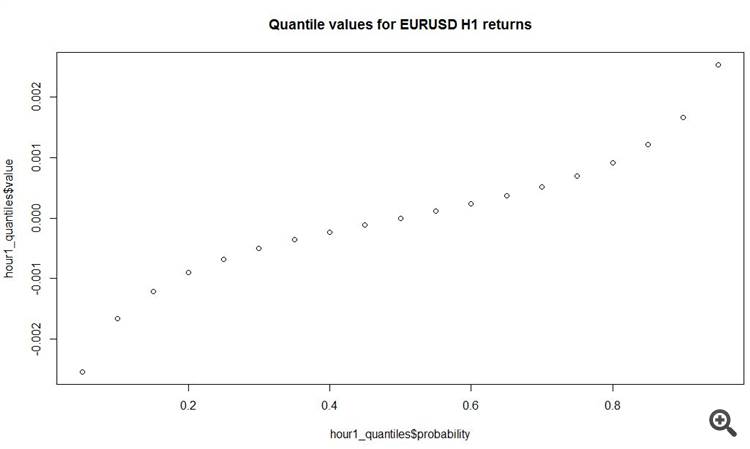
И еще одна интересная фигня - среднее абсолютное приращение на часовых барах - 11 пунктов! Всего.
Помудохаться придется долго, ведь нужна и ретрансформация и... , а Бокс-Кокс как то не особо нравится))) Жаль лишь, что если нет
нормальных предикторов, это мало повлияет на конечный результат...