Обсуждение статьи "Объединяем 3D-бары, квантовые вычисления и машинное обучение в единую торговую систему"
bar3d_yellow_cluster на последнем месте. Что не так?
Опубликована статья Объединяем 3D-бары, квантовые вычисления и машинное обучение в единую торговую систему:
Автор: Yevgeniy Koshtenko
Путем перебора параметров модели CatBoost и долгих часов максимум что удалось получить
================================================================================
Средняя точность: 55.66% ± 4.34%
Обучение финальной модели на всех данных...
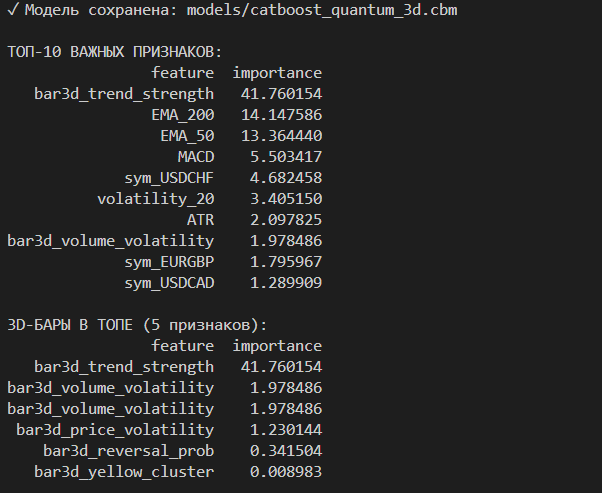
✓ Модель сохранена: models/catboost_quantum_3d.cbm
ТОП-10 ВАЖНЫХ ПРИЗНАКОВ:
feature importance
bar3d_trend_strength 30.591319
EMA_200 22.086104
EMA_50 14.959278
MACD 4.816617
volatility_20 4.555638
ATR 3.050433
bar3d_volume_volatility 2.690818
bar3d_price_volatility 2.354294
vol_ratio 2.308871
price_change_21 2.308647
3D-БАРЫ В ТОПЕ (5 признаков):
feature importance
bar3d_trend_strength 30.591319
bar3d_volume_volatility 2.690818
bar3d_price_volatility 2.354294
bar3d_reversal_prob 0.735604
bar3d_yellow_cluster 0.215698
Как у вас получился bar3d_yellow_cluster самым важным, не понимаю
제공된 코드를 분석한 결과, 현재 버전에서는 학습 데이터(Training) 와 백테스트 데이터(Backtest)가 명확하게 구분되어 있지 않은 것으로 나타났습니다.
이는 데이터 유출 로 이어져 백테스팅 결과가 실제 결과보다 훨씬 좋게 나오는 구조를 만들어냅니다.
코드의 논리를 분석하여 그 이유를 자세히 설명하겠습니다.
1. 문제 분석
A. 훈련 단계 (모드 1)
main() 함수에서 모드 1이 선택되면 load_mt5_data(180)가 호출됩니다.
if choice == "1": data = load_mt5_data(180) # Загружаются все данные за последние 180 дней # ... model = train_catboost_model(data, quantum_encoder, bars_3d)
다음으로, 함수 내부를 살펴보면 train_catboost_model 교차 검증이 수행되지만 마지막에는 전체 데이터셋을 사용하여 재학습이 이루어진다는 것을 알 수 있습니다 .
# Внутри train_catboost_model print("\n전체 데이터로 최종 모델 학습 중...") model.fit(X, y, verbose=500) # Здесь X — это полные данные за последние 180 дней
즉, 해당 모델은 "오늘"까지의 모든 데이터를 사용하여 학습됩니다.
B. 백테스트 단계 (모드 4)
backtest() 함수는 BACKTEST_DAYS = 30(최근 30일)으로 설정된 기간 동안 테스트를 수행합니다.
end = datetime.now().replace(second=0, microsecond=0) start = end - timedelta(days=BACKTEST_DAYS) # Последние 30 дней
2. 결론: 데이터 유출 발생 사례
-
학습 데이터: [오늘 - 180일] ~ [오늘]
-
테스트 데이터: [오늘 - 30일] ~ [오늘]
테스트하려는 기간(최근 30일) 은 이미 학습 데이터에 포함되어 있습니다 . 이는 모델이 이미 정답을 "본" 상태에서 시험을 치르는 것과 같으므로 백테스트 승률이 비현실적으로 높습니다.
3. 해결 방법 (코드 수정 가이드)
정확한 백테스트를 위해서는 학습 과정에서 테스트 기간을 제외 해야 합니다 .
해결 방법 1: 학습 함수에서 최신 데이터를 제외합니다(권장).
train_catboost_model 함수 내부 또는 데이터 로딩 단계에서 백테스트 기간만큼 데이터를 잘라내야 합니다.
# Предложение по исправлению: изменение внутри функции train_catboost_model def train_catboost_model(data_dict, quantum_encoder, bars_3d=None): # ... (пропуск) ... # [Исправление] Не создавайте X сразу из всех данных, нужно разделить их по дате. # Или просто исключите данные за последние BACKTEST_DAYS перед обучением. cutoff_index = len(df_features) - (BACKTEST_DAYS * 96) # Примерно 96 баров в день для M15 # Используем для обучения только данные до точки отсечения train_features = df_features.iloc[:cutoff_index] # ... далее используем train_features для обучения ...
해결 방법 2: 핵심 로직에서 데이터를 분리합니다.
가장 쉬운 방법은 main() 함수에서 데이터를 로드할 때 서로 다른 기간을 설정하는 것입니다.
-
모드 1 (학습): load_mt5_data(start_days=210, end_days=30) (예: 210일 전부터 30일 전까지의 데이터)
-
모드 4(테스트): backtest(days=30) (예: 30일 전부터 오늘까지의 데이터)
요약하자면, 현재 코드에는 예측 편향이 포함되어 있어 백테스트 결과를 신뢰할 수 없습니다. 실제 사용 전에 기간을 분할하고 모델을 재학습한 후 다시 테스트하는 것이 필수적입니다.
Приветствую, да, без углубления и изучения кода, выглядит очень заманчиво. НО, прочитав предыдущего комментатора - полез внутрь.
Действительно, бэктест проходит на данных, которые catboost уже видела.
Ради интереса деактивировал в коде вот эту строку:
print("\nОбучение финальной модели НА ВСЕХ ДАННЫХ...")
# model.fit(X, y, verbose=500)
и вуа ля, на бэктесте за 30 дней, режим 4, нет ни одной сделки(
CatBoost: еле-еле больше 50%
...эх, а счастье было так близко..)
Вами проделана огромная работа...и разочарование
Приветствую, да, без углубления и изучения кода, выглядит очень заманчиво. НО, прочитав предыдущего комментатора - полез внутрь.
Действительно, бэктест проходит на данных, которые catboost уже видела.
Ради интереса деактивировал в коде вот эту строку:
print("\nОбучение финальной модели НА ВСЕХ ДАННЫХ...")
# model.fit(X, y, verbose=500)
и вуа ля, на бэктесте за 30 дней, режим 4, нет ни одной сделки(
CatBoost: еле-еле больше 50%
...эх, а счастье было так близко..)
Вами проделана огромная работа...и разочарование
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Опубликована статья Объединяем 3D-бары, квантовые вычисления и машинное обучение в единую торговую систему:
Представлена полная интеграция модуля 3D-баров в квантово-усиленную торговую систему для прогнозирования движения валютных пар. Система объединяет стационарные четырёхмерные признаки, квантовый энкодер на 8 кубитах и градиентный бустинг CatBoost с 52+ признаками. Система реализована на Python с использованием MetaTrader 5, Qiskit, CatBoost и опциональной интеграцией LLM Llama 3.2 для интерпретации прогнозов.
В предыдущих статьях мы рассмотрели применение квантовых вычислений для извлечения нелинейных корреляций из рыночных данных, а также интеграцию языковых моделей с градиентным бустингом CatBoost. Точность прогнозирования составила 62.4% на кросс-валидации, что обеспечило доходность +27.39% за месяц бэктестинга на микросчёте $140.
Однако, анализ показал, что система упускает критически важную информацию — многомерную структуру взаимодействия цены, времени и объёма. Классические индикаторы работают с проекциями рынка на двумерные графики, теряя объёмную картину происходящего. В данной статье представлена полная интеграция модуля 3D-баров в квантово-усиленную торговую систему.
Автор: Yevgeniy Koshtenko