Разговор с искусственным интеллектом (ИИ) о форексе. - страница 112
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
Продолжая изучать модель глубокого обучения, написанного ChatGPT, я дам краткое описание модели и покажу результаты тестирования наиболее успешного результата обучения на данный момент с использованием различных валютных пар в тесте.
Модель представляет собой нейронную сеть, которая состоит из нескольких слоев и используется для решения задачи регрессии.
Алгоритм применения этой нейронной сети заключается в следующем:
Стоит отметить, что данная модель была реализована с использованием фреймворка TensorFlow и библиотеки Keras. Она может быть использована для решения задач прогнозирования временных рядов, анализа сигналов и других задач, где необходимо предсказать числовую величину.
Первые три слоя - это сверточные слои (Conv1D) с функцией активации ReLU. Они обрабатывают входные данные с размерностью (window_size_value, 1) и извлекают признаки из исходных данных. После каждого сверточного слоя применяется слой нормализации данных (BatchNormalization).
Следующие три слоя - это полносвязные слои (Dense), которые применяются для обработки выходных данных сверточных слоев. После первого полносвязного слоя применяется слой отсева (Dropout) с коэффициентом 0.2, который случайным образом выключает некоторые нейроны для предотвращения переобучения. Последний полносвязный слой имеет один нейрон и использует линейную функцию активации.
Следующие два слоя - это рекуррентные слои LSTM. Они предназначены для обработки последовательных данных и позволяют учитывать контекст из прошлых временных шагов. После каждого LSTM слоя также применяется слой нормализации данных (BatchNormalization) и слой отсева (Dropout) с коэффициентом 0.2.
Последние два слоя - это полносвязные слои с регуляризацией (kernel_regularizer и bias_regularizer) и случайной инициализацией весов (kernel_initializer). Первый полносвязный слой имеет размерность filters_min_value и использует функцию активации ReLU. После него применяется слой отсева (Dropout) с коэффициентом 0.5. Последний полносвязный слой имеет один нейрон и использует линейную функцию активации.
Код использует два callback-объекта в обучении модели:
LearningRateScheduler - позволяет динамически изменять скорость обучения модели в зависимости от номера эпохи. В данном случае скорость обучения определяется лямбда-функцией, которая увеличивает скорость обучения в 10 раз каждые 50 эпох. Это помогает ускорить обучение в начале процесса и уменьшить скорость в конце, чтобы достичь более точных результатов.
EarlyStopping - позволяет остановить обучение модели раньше, если модель перестает улучшаться на проверочных данных. Это помогает предотвратить переобучение и ускорить процесс обучения. Монитором, на основе которого будет приниматься решение о прекращении обучения, является val_loss , который отслеживает значение функции потерь на проверочных данных. patience_value определяет количество эпох, которые необходимо дождаться, чтобы убедиться в том, что модель не улучшается, прежде чем остановить обучение. Параметр restore_best_weights=True позволяет сохранить веса модели, которые достигли наилучших результатов на проверочных данных, чтобы использовать их в дальнейшем.

Модель обучалась на 31680 свечей RSI, таймфрейм H1 AUDUSD.Результаты теста:
Верхний график — фактические данные, нижний график — прогнозные данные AUDCAD
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.74
Верхний график — фактические данные, нижний график — прогнозные данные AUDNZD
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.73
Верхний график — фактические данные, нижний график — прогнозные данные AUDCHF
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.74
Верхний график — фактические данные, нижний график — прогнозные данные AUDJPY
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.75
Верхний график — фактические данные, нижний график — прогнозные данные AUDUSD
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.75
Верхний график — фактические данные, нижний график — прогнозные данные CHFJPY
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.76
Верхний график — фактические данные, нижний график — прогнозные данные EURAUD
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.73
Верхний график — фактические данные, нижний график — прогнозные данные EURCAD
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.70
Верхний график — фактические данные, нижний график — прогнозные данные EURCHF
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.68
Верхний график — фактические данные, нижний график — прогнозные данные EURGBP
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.71
Верхний график — фактические данные, нижний график — прогнозные данные EURJPY
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.76
Верхний график — фактические данные, нижний график — прогнозные данные EURUSD
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.73
Верхний график — фактические данные, нижний график — прогнозные данные GBPAUD
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.76
Верхний график — фактические данные, нижний график — прогнозные данные GBPCHF
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.71
Верхний график — фактические данные, нижний график — прогнозные данные GBPJPY
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.75
Верхний график — фактические данные, нижний график — прогнозные данные GBPUSD
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.74
Верхний график — фактические данные, нижний график — прогнозные данные NZDUSD
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.74
Верхний график — фактические данные, нижний график — прогнозные данные USDCAD
Pearson Correlation coefficient: 0.94, Average correlation, window size 24: 0.72
Верхний график — фактические данные, нижний график — прогнозные данные USDCHF
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.72
Верхний график — фактические данные, нижний график — прогнозные данные USDJPY
Pearson Correlation coefficient: 0.95, Average correlation, window size 24: 0.76
Для сравнения результат теста лучшей тренировки на данный момент.
И результат теста плохой тренировки.
В обоих случаях для проверки весов модели выбираются одни и те же входные данные.
Описанная ниже реализация кода написана с использованием ChatCPT.
Данный код представляет собой скрипт машинного обучения на языке Python, который позволяет создать модель для прогнозирования временных рядов. Он состоит из следующих шагов:
Преобразование списка в массив numpy.
Проверка, является ли последовательность унитарной.
Масштабирование выходных значений с помощью MinMaxScaler().
Создание списка без первых двух элементов со значениями 100 и 0.
Расчет значения минимального размера окна для скользящего окна.
Проверка прежде чем подгонять масштабировщик.
Создание входных/выходных последовательностей с использованием подхода скользящего окна.
Разделение данных на обучающую, валидационную и тестовую выборки.
Определение архитектуры модели с использованием Keras Sequential.
Определение пользовательских функций для оценки модели (r_square, r_squared_adj, rmse и rrmse).
Компиляция модели с использованием функции потерь mean squared error, оптимизатора Adam и метрик mean squared error, r_square, r_squared_adj, rmse и rrmse.
Общая задача кода - создать модель машинного обучения, которая может использоваться для прогнозирования временных рядов. Он использует библиотеки numpy, scikit-learn и TensorFlow для преобразования данных, создания модели и оценки ее производительности.
В результате выполнения кода машинного обучения достигается результат, показанный ниже, где синяя кривая на графике представляет тестовые данные, а красная кривая показывает прогнозируемые данные.
Тренировался с AUDUSD, но тестировался с:
EURAUD
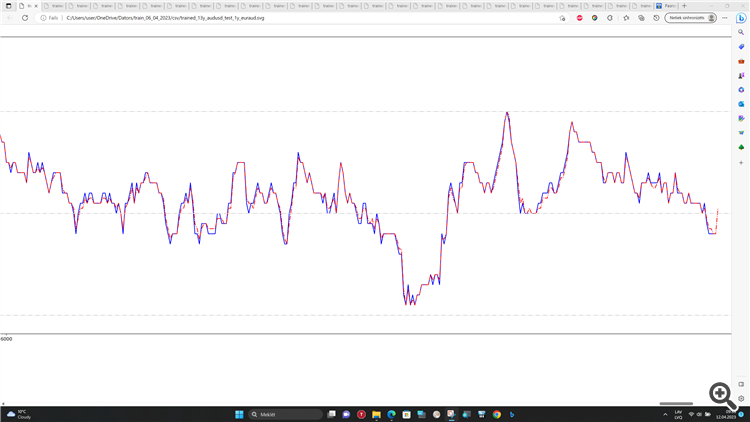
EURCHF
AUDCAD
EURCAD
AUDCHF
EURGBP
CHNAUD
AUDJPY
CHFJPY
AUDNZD
AUDUSD (результат тренировки)
USDCAD
USDCHF
USDCNH
EURSEK
EURJPY
EURUSD
GBPCHF
GBPEUR
GBPAUD
GBPJPY
GBPUSD
NZDUSD
USDJPY
USDSEK
USDX
Я не знаю, куда идти дальше? Где и как можно с пользой использовать такой обученный код?
Конвертировать модель в ONNX формат, чтобы использовать её в советнике.
Конвертировать модель в ONNX формат, чтобы использовать её в советнике.
Конвертация для использования в EA — это меньшее, что нужно сделать, в принципе сам CatGPT ничего содержательного не говорит о возможностях использования этой модели.
ChatGPT: "Я не могу дать вам конкретных советов по использованию этого кода в торговле на рынке Форекс, так как я не являюсь экспертом в этой области. Кроме того, использование модели машинного обучения в торговле на рынке Форекс требует глубокого понимания рынка, экономических факторов и других факторов, которые могут влиять на цены.
Однако, я могу предложить некоторые общие рекомендации.
Первым шагом должно быть тестирование модели на исторических данных. Для этого вам нужно иметь доступ к большому объему данных и разделить его на тренировочные, тестовые и валидационные наборы данных. Вы должны проверить, насколько точно модель предсказывает цены на тестовых данных.
Кроме того, при использовании моделей машинного обучения в торговле на рынке Форекс нужно учитывать не только точность прогноза, но и стоимость ошибки. Таким образом, вы должны оценить потенциальные убытки и риски, связанные с использованием модели.
Наконец, не забывайте, что прошлые результаты не гарантируют будущие выигрыши на рынке Форекс. Всегда существует риск потери капитала. Если вы не уверены в своих знаниях о рынке Форекс, рекомендуется обратиться к финансовым консультантам или другим специалистам в этой области."
Хотелось бы услышать возможности применения, самый примитивный способ это использовать код для предсказания следующего значения индикатора. Но, возможно, есть лучшее применение. Я говорю все это потому, что у меня совершенно нет опыта машинного обучения.
Дополнено.
Я просто следовала рекомендациям ChatGPT при построении кода этой модели, подготовке данных и проведении обучения.
Я не знаю, куда идти дальше? Где и как можно с пользой использовать такой обученный код?
можно сдвинуть график на 1 бар назад и сравнить ошибки между таким прогнозом и вашей моделью :)
можно сдвинуть график на 1 бар назад и сравнить ошибки между таким прогнозом и вашей моделью :)
Я не поняла, поясните, что именно вы хотите сравнить?
Тестирование происходит следующим образом:
"seq" - это тестовые данные.
"current_window = seq[start_index:end_index]" создает скользящее окно, которое перемещается от "0" до "len(seq)" по тестовым данным с шагом +1.
"predictions.append(round(next_number, 0))" прогнозы "next_number" записываются в "predictions" и, наконец, отображаются на графике вместе с тестовыми данными "seq".
Я не поняла, поясните, что именно вы хотите сравнить?
Тестирование происходит следующим образом:
"seq" - это тестовые данные.
"current_window = seq[start_index:end_index]" создает скользящее окно, которое перемещается от "0" до "len(seq)" по тестовым данным с шагом +1.
"predictions.append(round(next_number, 0))" прогнозы записываются в "predictions" и, наконец, отображаются на графике вместе с тестовыми данными "seq".
ошибка обучения модели, и посчитать такую же для сдвинутых графиков относительно друг друга на 1 бар
ошибка обучения модели, и посчитать такую же для сдвинутых графиков относительно друг друга на 1 бар
Что такое "ошибка обучения модели", это метрика (loss = 0.0285, mse = 0.0007, mae = 0.0191, msle = 0.0003, rmse = 0.0252, r_square = 0.9091,