Нейросеть. Обучение.
Столкнулся с такой ситуацией, что при обучении сети с одинаковыми параметрами, обучение проходит по разному. Оцениваю обучение по количеству ошибок в % на необученных данных.
Это нормально?
Что делать, выбирать сеть с наименьшим количеством ошибок или как?
НС обычно инициализируются случайным образом и каждая попытка обучения должна давать уникальную сеть. Рекомендуется тренировать комитет сеток, выбрать из них лучшие по ошибке на OOS, и далее при штатной работе обобщать результаты по мажоритарному принципу.
Столкнулся с такой ситуацией, что при обучении сети с одинаковыми параметрами, обучение проходит по разному. Оцениваю обучение по количеству ошибок в % на необученных данных.
Это нормально?
Что делать, выбирать сеть с наименьшим количеством ошибок или как?
Чтобы получать воспроизводимые результаты обучения необходимо фиксировать seed() генератора случайных чисел.
Столкнулся с такой ситуацией, что при обучении сети с одинаковыми параметрами, обучение проходит по разному. Оцениваю обучение по количеству ошибок в % на необученных данных.
Это нормально?
Что делать, выбирать сеть с наименьшим количеством ошибок или как?
Для нормальной сети обучение не может проходить по разному, ищите ошибки в своих сетях и алгоритме обучения
НС обычно инициализируются случайным образом и каждая попытка обучения должна давать уникальную сеть. Рекомендуется тренировать комитет сеток, выбрать из них лучшие по ошибке на OOS, и далее при штатной работе обобщать результаты по мажоритарному принципу.
Это получается, если у меня 15 модулей, то каждый из них нужно обучать неоднократно, сохранять, строить таблицу ошибок и сводить вместе наилучшее обучение.
Вопрос - какой, по Вашему, должен быть цикл? 5-10-15 ?
Чтобы получать воспроизводимые результаты обучения необходимо фиксировать seed() генератора случайных чисел.
Если зафиксировать - значит, возможно, потерять лучшее обучение?
Для нормальной сети обучение не может проходить по разному, ищите ошибки в своих сетях и алгоритме обучения
Из предыдущих ответов я понял, что может. Почему противоречие?
П.С. Собственно говоря использую сеть от "Yurich"-а. Человек сведущий, и вмешиваться во внутреннюю структуру сети, при моих познаниях в этой области, считаю себе дороже )))
- www.mql5.com
Вопрос - какой, по Вашему, должен быть цикл? 5-10-15 ?
Не понял вопроса. Размер комитета? Период переобучения? Что-то еще?
Как правило, ответы зависят от объема и характеристик данных, поэтому нужно подбирать мета-параметры опытным путем.
Это получается, если у меня 15 модулей, то каждый из них нужно обучать неоднократно, сохранять, строить таблицу ошибок и сводить вместе наилучшее обучение.
Вопрос - какой, по Вашему, должен быть цикл? 5-10-15 ?
Если зафиксировать - значит, возможно, потерять лучшее обучение?
Из предыдущих ответов я понял, что может. Почему противоречие?
П.С. Собственно говоря использую сеть от "Yurich"-а. Человек сведущий, и вмешиваться во внутреннюю структуру сети, при моих познаниях в этой области, считаю себе дороже )))Не понял вопроса. Размер комитета? Период переобучения? Что-то еще?
Как правило, ответы зависят от объема и характеристик данных, поэтому нужно подбирать мета-параметры опытным путем.
Давайте по-простому. Я имел ввиду, сколько раз достаточно обучать сеть, для получения достоверных результатов ошибки?
Если обучение от обучения отличается, то это может быть отличие при формировании обучающей выборки. Обучающий файл разбивается случайным образом что является средством предотвращения переобучения. Для инженера по обучение необходимо детально знать внутреную организацию используемого продукта иначе многие процессы и результату будут не понятны. Seeds же влияет на сами коэффиценты что реально приводит к их отсличию в целом что влечёт за собой отличие на тестовом участке. А комитет делать нужно хитро это всё не просто так..... на самом деле....
Обучающая выборка подготавливается заранее и не меняется.
Надо сократить количество нейронов в сети.
А вот этот вопрос меня тоже очень интересует. )))
Я сколько не искал, так и не понял, сколько скрытых слоёв достаточно для сети и какого размера они должны быть?
Получил такую табличку.
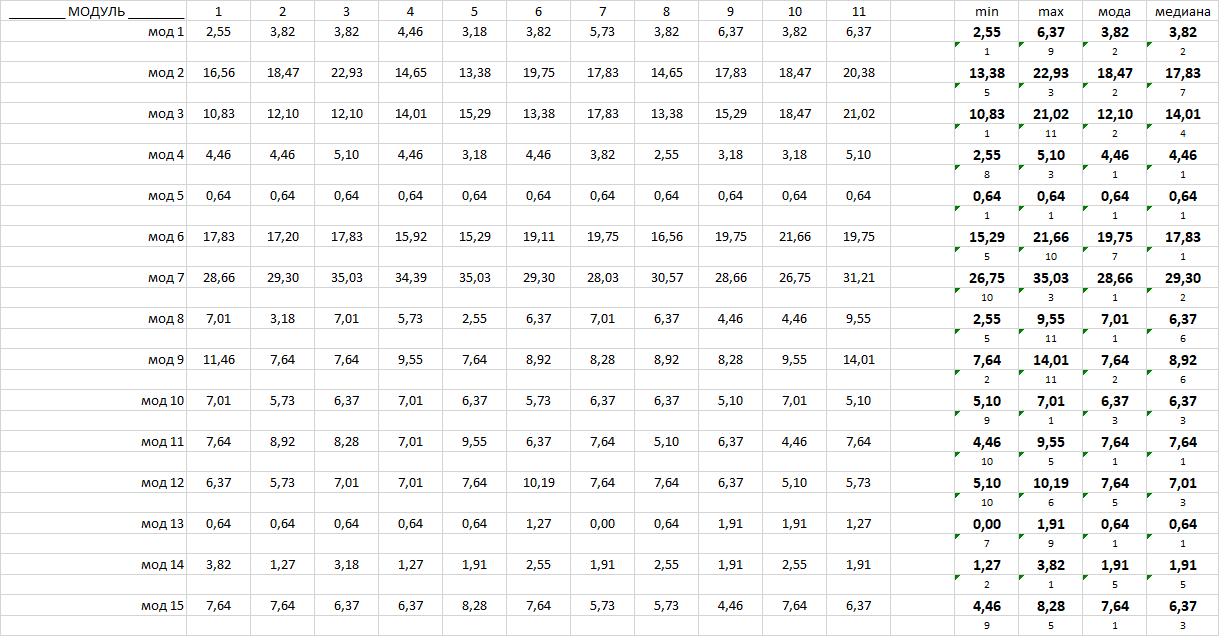
| ________ МОДУЛЬ ________ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | min | max | мода | медиана | |
| мод 1 | 2,55 | 3,82 | 3,82 | 4,46 | 3,18 | 3,82 | 5,73 | 3,82 | 6,37 | 3,82 | 6,37 | 2,55 | 6,37 | 3,82 | 3,82 | |
| 1 | 9 | 2 | 2 | |||||||||||||
| мод 2 | 16,56 | 18,47 | 22,93 | 14,65 | 13,38 | 19,75 | 17,83 | 14,65 | 17,83 | 18,47 | 20,38 | 13,38 | 22,93 | 18,47 | 17,83 | |
| 5 | 3 | 2 | 7 | |||||||||||||
| мод 3 | 10,83 | 12,10 | 12,10 | 14,01 | 15,29 | 13,38 | 17,83 | 13,38 | 15,29 | 18,47 | 21,02 | 10,83 | 21,02 | 12,10 | 14,01 | |
| 1 | 11 | 2 | 4 | |||||||||||||
| мод 4 | 4,46 | 4,46 | 5,10 | 4,46 | 3,18 | 4,46 | 3,82 | 2,55 | 3,18 | 3,18 | 5,10 | 2,55 | 5,10 | 4,46 | 4,46 | |
| 8 | 3 | 1 | 1 | |||||||||||||
| мод 5 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | |
| 1 | 1 | 1 | 1 | |||||||||||||
| мод 6 | 17,83 | 17,20 | 17,83 | 15,92 | 15,29 | 19,11 | 19,75 | 16,56 | 19,75 | 21,66 | 19,75 | 15,29 | 21,66 | 19,75 | 17,83 | |
| 5 | 10 | 7 | 1 | |||||||||||||
| мод 7 | 28,66 | 29,30 | 35,03 | 34,39 | 35,03 | 29,30 | 28,03 | 30,57 | 28,66 | 26,75 | 31,21 | 26,75 | 35,03 | 28,66 | 29,30 | |
| 10 | 3 | 1 | 2 | |||||||||||||
| мод 8 | 7,01 | 3,18 | 7,01 | 5,73 | 2,55 | 6,37 | 7,01 | 6,37 | 4,46 | 4,46 | 9,55 | 2,55 | 9,55 | 7,01 | 6,37 | |
| 5 | 11 | 1 | 6 | |||||||||||||
| мод 9 | 11,46 | 7,64 | 7,64 | 9,55 | 7,64 | 8,92 | 8,28 | 8,92 | 8,28 | 9,55 | 14,01 | 7,64 | 14,01 | 7,64 | 8,92 | |
| 2 | 11 | 2 | 6 | |||||||||||||
| мод 10 | 7,01 | 5,73 | 6,37 | 7,01 | 6,37 | 5,73 | 6,37 | 6,37 | 5,10 | 7,01 | 5,10 | 5,10 | 7,01 | 6,37 | 6,37 | |
| 9 | 1 | 3 | 3 | |||||||||||||
| мод 11 | 7,64 | 8,92 | 8,28 | 7,01 | 9,55 | 6,37 | 7,64 | 5,10 | 6,37 | 4,46 | 7,64 | 4,46 | 9,55 | 7,64 | 7,64 | |
| 10 | 5 | 1 | 1 | |||||||||||||
| мод 12 | 6,37 | 5,73 | 7,01 | 7,01 | 7,64 | 10,19 | 7,64 | 7,64 | 6,37 | 5,10 | 5,73 | 5,10 | 10,19 | 7,64 | 7,01 | |
| 10 | 6 | 5 | 3 | |||||||||||||
| мод 13 | 0,64 | 0,64 | 0,64 | 0,64 | 0,64 | 1,27 | 0,00 | 0,64 | 1,91 | 1,91 | 1,27 | 0,00 | 1,91 | 0,64 | 0,64 | |
| 7 | 9 | 1 | 1 | |||||||||||||
| мод 14 | 3,82 | 1,27 | 3,18 | 1,27 | 1,91 | 2,55 | 1,91 | 2,55 | 1,91 | 2,55 | 1,91 | 1,27 | 3,82 | 1,91 | 1,91 | |
| 2 | 1 | 5 | 5 | |||||||||||||
| мод 15 | 7,64 | 7,64 | 6,37 | 6,37 | 8,28 | 7,64 | 5,73 | 5,73 | 4,46 | 7,64 | 6,37 | 4,46 | 8,28 | 7,64 | 6,37 | |
| 9 | 5 | 1 | 3 |
Понятно, что хочется выбрать по минимуму )))
Но может лучше по МОДЕ или МЕДИАНЕ ?
Давайте по-простому. Я имел ввиду, сколько раз достаточно обучать сеть, для получения достоверных результатов ошибки?
Обучающая выборка подготавливается заранее и не меняется.
А вот этот вопрос меня тоже очень интересует. )))
Я сколько не искал, так и не понял, сколько скрытых слоёв достаточно для сети и какого размера они должны быть?
По закону больших чисел, чем большее количество сеток ресурсы позволяют обучить, тем лучше ;-). Если не особо строго в мат. плане подходить, то вот в этой статье есть формула для расчета вероятности успеха сигнала от количества N независимых индикаторов (в нашем случае сетей), где p - вероятность правильной классификации одной сетью.
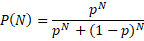
Так что один-два десятка в комитете - уже хорошо.
Одного скрытого слоя достаточно для нелинейной обработки большинства задач. Размер скрытого слоя рекомендуют выбирать исходя из пары ограничений сверху и снизу: общее число весов сети, т.е. Ninput*Nhidden+Noutput*Nhidden должно быть в несколько (десятков/сотен) раз меньше Npatterns/Noutput, но Nhidden при этом больше или равно корню из произведения количества входов на количество выходов.

- www.mql5.com
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Столкнулся с такой ситуацией, что при обучении сети с одинаковыми параметрами, обучение проходит по разному. Оцениваю обучение по количеству ошибок в % на необученных данных.
Это нормально?
Что делать, выбирать сеть с наименьшим количеством ошибок или как?