記事「PatchTST機械学習アルゴリズムによる24時間の値動きの予測」についてのディスカッション
MT5で見かけるバーが何なのか、もっと詳しく説明してもらえますか?緑と赤の2色がありますが、何を示しているのでしょうか?ありがとうございます。
緑と赤のバーはこのコードスニペットから生成されます:
ObjectSetInteger(0, obj_name, OBJPROP_COLOR, close > open ? clrGreen : clrRed);
つまり、緑色は、その時点の終値が始値よりも高くなるとモデルが考えていることを意味します(ローソク足チャートの緑色のバーのようなものです)。
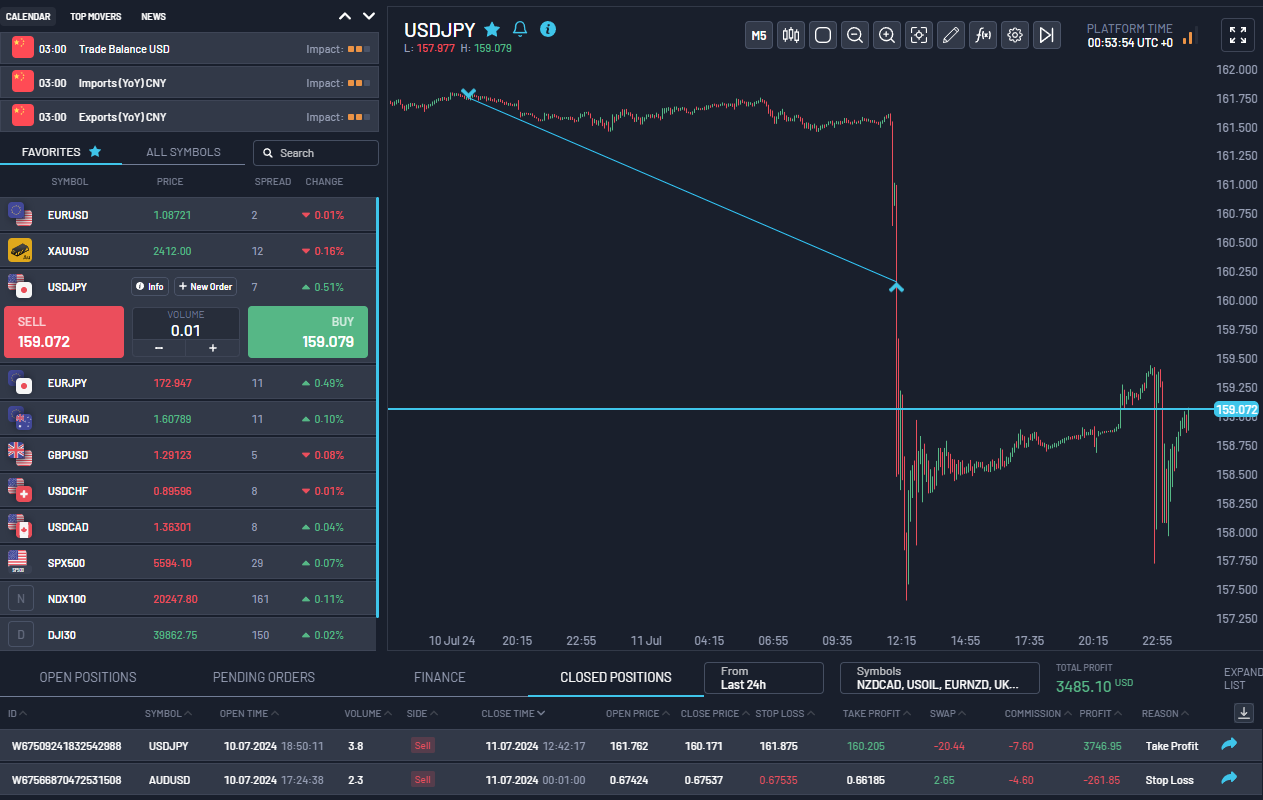
例えば、昨日、他のいくつかのペアのモデルをトレーニングしました。チャートに表示したインジケータを使いましたが、ONNXモデルはUSDJPYとAUDUSDでトレーニングしました。今朝、USDJPYのモデル予測に基づいて15Rのトレードをした。この間、私はチャートを見ていなかった。トレーニングを終えてから午後に取引を行い、一晩ポジションを保有しました(スワップは私が支払いました)。私の経験では、これまでのところ、モデルが予測する方向はおおむね信頼できるということがわかりました。例えば、チャート上で赤いバーが連続している場合は、モデルが価格が下がると考えていることを示しています。緑のバーが多ければ、モデルは価格が上昇すると考えていることを示します。
ご覧の通り、私もモデル予測に基づいてAUDUSDで約1Rの損失を出した。SLとTPを設定するための需給ゾーン、マクロのファンダメンタルズ、ポジションのサイジング、リスク管理など、他のスキルを使う必要があります。私の意見では、訓練されたPatchTSTモデルを使えば、少なくともその日の適切な時間帯、または適切なセッション(アジア、ロンドン、またはNY)に取引を行う際に、より多くの精度と自信を得ることができます。下のスクリーンショットは、私が現在取り組んでいるプロップファーム評価のものです。
こんにちは!
MLトレーディング・アルゴリズムにご関心とご丁寧なコメントをいただき、ありがとうございます!アイデアを面白いと思っていただけて嬉しいです。ご指摘の点を一つずつ取り上げていきましょう:
- LSTMとPatchTSTのパフォーマンス比較:
- PatchTSTの方がトレンド予測の精度が高いと感じました。
- LSTMは、統合時にはより良いパフォーマンスを発揮するようだ。
- 全体として、私のテストではPatchTSTの方が若干勝率が良かった。
- トレーニング期間とタイムフレーム
- 異なる時間枠でトレーニングする実験を行った。
- 私の経験では、1時間の時間枠が最も効果的なようだ。
- 過去データが長いほど、よりロバストなモデルが得られる傾向があるため、1ヶ月間だけのトレーニングは特に試していない。
- モデルと時間枠の組み合わせ:
- 異なるタイムフレーム(例えばH1とM15)のモデルを組み合わせるというアイデアは興味深い。
- トレードオフを考慮する必要があります。より短いタイムフレームを使用すると、より多くのデータポイントが必要となり、トレーニング時間が指数関数的に増加します。
- 例えば、15 分足のタイムフレームを使用すると、1 時間足の 4 倍の数のバーが必要になり、予測ホライズンも 4 倍になります。
- M1でのスキャルパー戦略:
- 予測をフィルターとして使用し、M1時間枠でスキャルパーを作成するという提案は独創的です。
- 7/10のグリーンバーを買いに、5-6/10のレンジ相場に使うというアイデアは、戦略の出発点として良い。
- このアプローチは、偽シグナルを減らし、エントリータイミングを改善する可能性がある。
- 現在の仕事と今後の方向性
- a) 1週間のタイムフレームでプライスアクションを予測するモデル b) 1日のタイムフレームで別のモデル c) 5分のタイムフレームで3番目のモデル。
- これらはすべて異なるモデルであり、特定の時間枠に合わせたものである。
- 目標は、複数の時間軸を考慮した、より包括的な取引システムを構築することである。
- その他の考慮事項
- 複数の時間枠とモデルからの予測を組み合わせることで、戦略全体のパフォーマンスを高めることができます。
- しかし、複雑さを管理し、オーバーフィッティングを避けることが極めて重要である。
- 組み合わせたアプローチの有効性を検証するためには、サンプル外のデータでバックテストとフォワードテストを行うことが不可欠です。
今回もアイデアを共有していただきありがとうございました。私の現在進行中の仕事において考慮すべき、いくつかの新しい視点を与えてくれました。また何かお気づきの点やご質問がありましたら、遠慮なくお尋ねください!
# Step 11: Train the model for epoch in range(num_epochs): model.train() total_loss = 0 for batch_X, batch_y in train_loader: optimizer.zero_grad() batch_X = batch_X.to(device) batch_y = batch_y.to(device) outputs = model(batch_X) outputs = outputs[:, -pred_length:, :4] loss = loss_fn(outputs, batch_y) loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch {epoch+1}/{num_epochs}, Loss: {total_loss/len(train_loader):.10f}")
RuntimeError: permute(sparse_coo): number of dimensions in the tensor input does not match the length of the desired ordering of dimensions i.e. input.dim() = 3 is not equal to len(dims) = 4
このような魅力的な記事を掲載していただきありがとうございます。私はpythonの経験はありますが、AIモデルにはあまり手を出していません。
H1ではなくM1のデータでトレーニングしたい場合、トレーニングスクリプトを変更するのが妥当でしょうか?ありがとうございます。
seq_length = 10080 # 1週間のM1データ pred_length = 30 # 次の30分を予測する
このような魅力的な記事を掲載してくれてありがとう。私はパイソンの経験はありますが、AIモデルにはあまり手を出していません。
H1ではなくM1のデータでトレーニングしたい場合、トレーニングスクリプトを変更するのが妥当でしょうか?ありがとうございます。
ご質問ありがとうございます!しかし、M1データに切り替える際には、いくつかの重要な考慮事項があります:
1.データ量:データ量:10080分(1週間)のM1データでトレーニングすることは、H1データよりもはるかに多くのデータポイントを扱うことを意味します。これは次のようなことを意味する:
- トレーニング時間が大幅に増加
- より多くのメモリを必要とする
- 効率的なトレーニングのためにGPUアクセラレーションが必要になる可能性がある。
2.モデル・アーキテクチャの調整:モデルトレーニングのステップ8と予測コードのステップ4で、より大きな入力シーケンスに対応するために他のパラメータを調整したくなるかもしれません:
class Config: def __init__(self): self.patch_len = 120 # M1データではより大きなパッチサイズを考慮する self.stride = 120 # ストライドを調整する self.d_model = 128 # より大きなモデル容量が必要かもしれない3.予測の質:より詳細な予測が得られる一方で、M1データには通常より多くのノイズが含まれていることに注意してください。最適なバランスを見つけるために、異なるシーケンス長や予測ウィンドウを試してみるとよいでしょう。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事「PatchTST機械学習アルゴリズムによる24時間の値動きの予測」はパブリッシュされました:
この記事では、PatchTSTと呼ばれる2023年にリリースされた比較的複雑なニューラルネットワークアルゴリズムを適用し、今後24時間の値動きを予測します。公式リポジトリを使用し、若干の修正を加え、EURUSDのモデルを訓練し、PythonとMQL5の両方で将来の予測をおこなうために適用します。
私が初めてPatchTSTというアルゴリズムに出会ったのは、Huggingface.coで時系列予測に関連するAIの進歩を調べ始めたときでした。大規模言語モデル(LLM)を扱ったことのある人なら誰でも知っているように、Transformerの発明は、自然言語、画像、ビデオ処理用のツールを開発する上でゲームチェンジャーとなりました。しかし、時系列ではどうでしょう。ただ置き去りにされるものなのでしょうか。それとも、ほとんどの研究は単に密室でおこなわれているのでしょうか。時系列の予測にTransformerをうまく適用した新しいモデルがたくさんあることがわかりました。この記事では、そのような実装のひとつを見てみましょう。
PatchTSTで印象的なのは、モデルの訓練が非常に速く、訓練されたモデルをMQLで使用するのが非常に簡単なことです。自分がニューラルネットワークの概念には疎いことは認めます。しかし、このプロセスを経て、この記事で概説されているMQL5用のPatchTSTの実装に取り組むことで、このような複雑なニューラルネットワークがどのように開発され、トラブルシューティングされ、訓練され、使用されるのかについて学び、理解する上で大きな飛躍を遂げたように感じました。やっと歩けるようになったばかりの子供をプロのサッカーチームに入れ、ワールドカップ決勝で勝利のゴールを決めることを期待するようなものです。
作者: Shashank Rai