市場は制御されたダイナミックなシステムである。 - ページ 20 1...131415161718192021222324252627...551 新しいコメント СанСаныч Фоменко 2011.10.13 17:13 #191 -Aleksey-: 静止しているかどうかにかかわらず、どのような場合でも一定のステップ数でカウントされるのは間違いです。おそらく、やり方がわからないのでしょう。でも、それがメインではなく、働きながら掘り続けることがメインなのです。なんなら、私が教えてあげましょうか。HPで定常残差を得るということは、私の理解では、従来の計量経済学では1段階以上予測できない非決定 トレンドを同定したことになります。また、デトレンドされた トレンドを予測するのではなく、定常的なランダム 残差を予測する必要があるのはなぜでしょうか?逆さまにしているんですね。パッケージを計算ツールとして使う前に、やりたいことの意味を理解しておく必要があります。 静止しているかどうかに関わらず、ある一定のステップ数で一義的にカウントされます。 原則的に。上のモデルの予測誤差のグラフを示します。 この 誤差で予測を信用できると思いますか?予測誤差の記述統計量を与える。 HPを使用して定常残差を得ることは、非決定論的な トレンドが分離されたことを意味します。 HPで定常残差を得ることに失敗する(上記参照)。 HPは分析曲線、つまり決定論的であり、トレンドとして利用される。 従来の計量経済学 では、私の理解する限り、一歩以上予測することはできません。 完全に誤解していますね。 また、定常的なランダム残差を予測することに何の意味があるのでしょうか? ランダムな残差を予測する人はいません。それは決定論的なトレンドに対するノイズです。 ...専用の決定論的な傾向を予測するために? TAが通常行っている決定論的なトレンドの予測に問題はない。 何でもかんでも逆さまにしてしまうんですね。パッケージを計算ツールとして使う前に、やりたいことの意味を理解しておく必要があります。 私はパッケージを適用していますが、あなたはそれを見ずに議論しているのです。 私の投稿はすべて計算に基づいていますし、関連する教科書へのリンクも提供できます。 СанСаныч Фоменко 2011.10.13 17:30 #192 Vizard: +1 事実と予測の線を投げかける...妥当性を検証するために実行するか? できるんです。でも、上のモデルを見てください。成功はその中にある。これまでのところ、この モデルは 適用できないことが判明しています。だから、まずはモデルから始めたいと思ったんです。このスレッドでは、「予測はできるが、それをどの程度まで信用できるか」という点を伝えようとしている。信頼の問題こそ本丸であり、あとはここぞとばかりに数字を出す。 СанСаныч Фоменко 2011.10.13 17:43 #193 Vizard: と、予測の信頼性について話しています。では、興味のある方はチェックしてみましょう。2つの行を投げます。1つは実際の値、もう1つは予測です。実行して、あなたの意見を言ってください。そして、予測が実際にどうなるかを見てください... 勿論、大雑把にですが...興味本位で...。 上のモデルに問題はないが、うまくいかない。これでは予報を信用することはできない。 削除済み 2011.10.13 18:02 #194 faa1947 さん、HPフィルターとは何か、なぜ決定論的なトレンドでないのか、理解されていません。決定論的とは、パラメトリックな傾向のことである。一方、HPはノンパラメトリックなトレンドであり、このようなトレンドは予測には使われないので、一段階予測にしか使えない。もちろん、申し訳ありませんが、すべての文字を説明することはできません、ボリュームが非常に大きくなってしまいます。。 СанСаныч Фоменко 2011.10.13 18:41 #195 Vizard: バッグに移動しました。 みたいですね。回帰式 ファクト = c(1)*fact(-1) + c(2)*hp(-1) + c(3)*hp(-2) 平滑化し、フィルタと商の間の残差はノイズであることを得る я なお、絶対予測誤差は9pipsである。 ジョイントグラフ。 赤が私の予想です。あなたのよりずっといい。 私たちは、聖杯を手に入れたと考えることができます、イェーイ!!!! 使用しないでください。残留異分散性検定では、残留異分散性がない確率はゼロであり、異分散性をモデル化する必要がある。一歩先の予測は、不吉な嘘をつく。それが全財産です。 予測誤差のグラフを見てみよう。 バイアスがかかっている、つまり、トレンドを完全に取り除いたわけではありません。記述統計学は最終的な評決を下す - このような素晴らしい予測を使うべきではありません。 СанСаныч Фоменко 2011.10.13 18:43 #196 -Aleksey-: faa1947 さん、HPフィルターとは何か、なぜ決定論的なトレンドでないのか理解されていないようですね。決定論的とは、パラメトリックな傾向のことである。一方、HPはノンパラメトリックなトレンドであり、このようなトレンドは予測には使われないので、一段階予測にしか使えない。もちろん、申し訳ないですが、すべての文字を説明することはできません、ボリュームが非常に大きくなってしまいます。 お説教はうんざりだが、中身のあるものが欲しい。 削除済み 2011.10.13 18:50 #197 Vizard: どれを使ったらいいのか、教えてください。 解析的な関数で、滑らかなものが望ましいですが、理由と時期を理解すれば区分関数も使用できますし、t に依存しますが y(t) には依存しません。 СанСаныч Фоменко 2011.10.13 19:29 #198 Vizard: 私の予測の結論は、信頼できるものですか? 私のはもっと優れていて、信用できないし、その理由も示しています。 あなたの予測の信頼性については、私は何も言えません。なぜなら、その予測がどのように得られるのか、この予測の誤差はどのくらいか、この誤差の統計はどのくらいか、といった予測が付随する計算もありませんし、その上、ワゴン車と小さな荷台があるのですからね。 このシリーズを続けられますか? 20本ですか? できない。ただ、誤差が蓄積され、加算され、20本のロウソクで20倍の大きさになることはわかる。だから、やったことがないんです。パッケージにはいわゆる「ダイナミック」な予報があるが、面白いものはない。 СанСаныч Фоменко 2011.10.13 19:37 #199 Vizard: 4MB以上あります。計量経済学」でググればいくらでも本がある、大学にもそういう専門がある。一番いいのはEViewsを入れることで、ツールもあるし、各章へのリンクもある。 頑張ってください。 削除済み 2011.10.14 07:51 #200 faa1947: お説教はうんざりだが、中身のあるものが欲しい。 私もあなたと同じ初心者です。まずは簡単なものから、つまり確率論や数理統計学の観点から、トレンドの存在とその形態について論理的に整合性のある数学的定義を行うべきと考えます。現在のトレンド、予測されるトレンド、それらの相互関係。そのような明確な認識がない以上、何をカウントしてもあまり意味がないと思います。 1...131415161718192021222324252627...551 新しいコメント 取引の機会を逃しています。 無料取引アプリ 8千を超えるシグナルをコピー 金融ニュースで金融マーケットを探索 新規登録 ログイン スペースを含まないラテン文字 このメールにパスワードが送信されます エラーが発生しました Googleでログイン WebサイトポリシーおよびMQL5.COM利用規約に同意します。 新規登録 MQL5.com WebサイトへのログインにCookieの使用を許可します。 ログインするには、ブラウザで必要な設定を有効にしてください。 ログイン/パスワードをお忘れですか? Googleでログイン
静止しているかどうかにかかわらず、どのような場合でも一定のステップ数でカウントされるのは間違いです。おそらく、やり方がわからないのでしょう。でも、それがメインではなく、働きながら掘り続けることがメインなのです。なんなら、私が教えてあげましょうか。HPで定常残差を得るということは、私の理解では、従来の計量経済学では1段階以上予測できない非決定 トレンドを同定したことになります。また、デトレンドされた トレンドを予測するのではなく、定常的なランダム 残差を予測する必要があるのはなぜでしょうか?逆さまにしているんですね。パッケージを計算ツールとして使う前に、やりたいことの意味を理解しておく必要があります。
静止しているかどうかに関わらず、ある一定のステップ数で一義的にカウントされます。
原則的に。上のモデルの予測誤差のグラフを示します。
この 誤差で予測を信用できると思いますか?予測誤差の記述統計量を与える。
HPを使用して定常残差を得ることは、非決定論的な トレンドが分離されたことを意味します。
HPで定常残差を得ることに失敗する(上記参照)。
HPは分析曲線、つまり決定論的であり、トレンドとして利用される。
従来の計量経済学 では、私の理解する限り、一歩以上予測することはできません。
完全に誤解していますね。
また、定常的なランダム残差を予測することに何の意味があるのでしょうか?
ランダムな残差を予測する人はいません。それは決定論的なトレンドに対するノイズです。
...専用の決定論的な傾向を予測するために?
TAが通常行っている決定論的なトレンドの予測に問題はない。
何でもかんでも逆さまにしてしまうんですね。パッケージを計算ツールとして使う前に、やりたいことの意味を理解しておく必要があります。
私はパッケージを適用していますが、あなたはそれを見ずに議論しているのです。
私の投稿はすべて計算に基づいていますし、関連する教科書へのリンクも提供できます。
+1
事実と予測の線を投げかける...妥当性を検証するために実行するか?
と、予測の信頼性について話しています。では、興味のある方はチェックしてみましょう。2つの行を投げます。1つは実際の値、もう1つは予測です。実行して、あなたの意見を言ってください。そして、予測が実際にどうなるかを見てください...
勿論、大雑把にですが...興味本位で...。
。
バッグに移動しました。
みたいですね。回帰式
ファクト = c(1)*fact(-1) + c(2)*hp(-1) + c(3)*hp(-2)
平滑化し、フィルタと商の間の残差はノイズであることを得る
я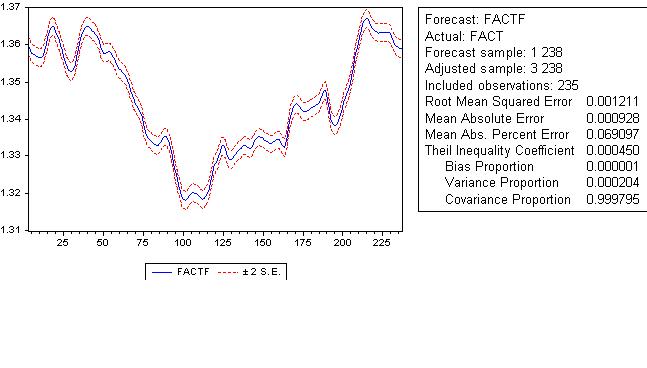
なお、絶対予測誤差は9pipsである。
ジョイントグラフ。
赤が私の予想です。あなたのよりずっといい。
私たちは、聖杯を手に入れたと考えることができます、イェーイ!!!!
使用しないでください。残留異分散性検定では、残留異分散性がない確率はゼロであり、異分散性をモデル化する必要がある。一歩先の予測は、不吉な嘘をつく。それが全財産です。
予測誤差のグラフを見てみよう。
バイアスがかかっている、つまり、トレンドを完全に取り除いたわけではありません。記述統計学は最終的な評決を下す - このような素晴らしい予測を使うべきではありません。
faa1947 さん、HPフィルターとは何か、なぜ決定論的なトレンドでないのか理解されていないようですね。決定論的とは、パラメトリックな傾向のことである。一方、HPはノンパラメトリックなトレンドであり、このようなトレンドは予測には使われないので、一段階予測にしか使えない。もちろん、申し訳ないですが、すべての文字を説明することはできません、ボリュームが非常に大きくなってしまいます。
どれを使ったらいいのか、教えてください。
私の予測の結論は、信頼できるものですか?
私のはもっと優れていて、信用できないし、その理由も示しています。
あなたの予測の信頼性については、私は何も言えません。なぜなら、その予測がどのように得られるのか、この予測の誤差はどのくらいか、この誤差の統計はどのくらいか、といった予測が付随する計算もありませんし、その上、ワゴン車と小さな荷台があるのですからね。
このシリーズを続けられますか? 20本ですか?
できない。ただ、誤差が蓄積され、加算され、20本のロウソクで20倍の大きさになることはわかる。だから、やったことがないんです。パッケージにはいわゆる「ダイナミック」な予報があるが、面白いものはない。
4MB以上あります。計量経済学」でググればいくらでも本がある、大学にもそういう専門がある。一番いいのはEViewsを入れることで、ツールもあるし、各章へのリンクもある。
頑張ってください。
お説教はうんざりだが、中身のあるものが欲しい。