記事"人工知能を用いたTDシーケンシャル(トーマス デマークのシーケンシャル)"についてのディスカッション
では、あなたの言う「人工知能」はどこにあるのか?ニューラルネットワークはどこにあるのか?
1.2つのNNの方向性?ニューラルネットワークは回帰と分類の2つの問題を解決します。クラスタリングやランキングを使うことはあまりない。そして、ニューラルネットワークは何百もないにしても何十もあります。どんなニューラルネットワークを使ったことがありますか?
2.オーバーフィッティングは定義されているだけでなく、その発生確率を減らすための方法も開発されています。ニューラルネットワークの場合、それは正則化(L1/L2)、安定化(ドロップアウト、ドロップコネクト、その他多数)である。したがって、よく知られた表現を言い換えれば、「すべてのモデルは再学習されるが、その確率がはるかに低いモデルもある」ということになる。
3.分類器には、予測を決してあきらめない "ハード "なものと、予測を拒否して "わからない "と言う "ソフト "なものがある。"ハードな分類器 "は、キャリブレーション後に "ソフト "になる。分類器を "ソフト "にする方法は他にもあります。
4.さて、冒頭の1回目のエラー後にシグナルを反転させる推奨はスーパーだ。
もし、ニューラルネットワークの使用における革命を約束する著者の数多くの事前発表がなかったら、素通りしてしまうかもしれない。
というわけで、私としてはノークレジットである。
では、あなたの言う「人工知能」はどこにあるのか?ニューラルネットワークはどこにあるのか?
1.2つのNNの方向性?ニューラルネットワークは回帰と分類の2つの問題を解決します。クラスタリングやランキングを使うことはあまりない。そして、ニューラルネットワークは何百もないにしても何十もあります。どんなニューラルネットワークを使ったことがありますか?
2.オーバーフィッティングは定義されているだけでなく、その発生確率を減らすための方法も開発されています。ニューラルネットワークの場合、それは正則化(L1/L2)、安定化(ドロップアウト、ドロップコネクト、その他多数)である。したがって、よく知られた表現を言い換えれば、「すべてのモデルは再学習されるが、その確率がはるかに低いモデルもある」ということになる。
3.分類器には、予測を決してあきらめない "ハード "なものと、予測を拒否して "わからない "と言う "ソフト "なものがある。"ハードな分類器 "は、キャリブレーション後に "ソフト "になる。分類器を "ソフト "にする方法は他にもあります。
4.さて、冒頭の1回目のエラー後にシグナルを反転させる推奨はスーパーだ。
もし、ニューラルネットワークの使用における革命を約束する著者の数多くの事前発表がなかったら、この本を通り過ぎてしまうかもしれない。
しかし、私としては失敗作である。
さて.素晴らしい最初のコメントがある。
1.はい、確かに、NSの多くの種類がありますが、メインは2つの方向、分類と予測であり、クラスタリングは、クラスが0と1の2つではなく、よりである場合を意味します。
2.オーバートレーニングの程度を特定することは容易ではない。
3.2つのネットワークの委員会が使われる。各ネットワークは別々に、あなたの言うように「予測をあきらめない」が、我々は委員会が同時に「Yes」または「No」と言う瞬間にのみ興味がある。ネットワークの委員会は長い間使われており、広く使われている。著者のユーリによれば、委員会は単一のネットワークよりも汎化能力が高い。
4.ネットワークをひっくり返すと、2度目のミスを犯す可能性があるからだ。ポイントは、現在の信号と以前の信号の2つを比較し、以前の信号の結果を知ることで、現在の信号について、その真偽などについて結論を導き出すことができるということだ。確かに、ネットワークは単純に間違いを犯す可能性がある。
まあ、私はクーデターを約束したわけではなく、TSのRIGHT構築の方法を約束しただけなのだが、時々、ちょっと怖くなるような異端なことを書く人がいるからだ。
申し訳ないが、この記事はとてもひどい。レシェトフというオプティマイザーの宣伝であり、それだけで何の役にも立たない。フォメンコ氏の森林とトレンドに関する記事を例にとると、初心者向けではあるが、非常に有益な記事である。
正直言って、初めての経験だ。何が気に入らなかったのですか?もっと具体的に教えてください。たぶん、何かが明確になっていないのでは?結局のところ、この記事のポイントは、誰もが自分のTSを構築する際に使用できる方法について知らせることであり、特に私のTSを採用する必要はない。
まあ...素晴らしい最初のコメントがあり、うれしい限りだ。
1.クラスタリングは、クラスが0と1の2つではなく、それ以上であることを意味します。
2.確かに、何も立ち止まることはありませんし、オーバートレーニングを減らすための方法はすでにありますが、オーバートレーニングの程度を識別することは容易ではありません。
3. 2つのネットワークからなる委員会が使用される。各ネットワークは別々に、あなたの言うように「予測をあきらめない」が、我々は委員会が同時に「Yes」または「No」と言う瞬間にのみ興味がある。ネットワークの委員会は長い間使われており、広く使われている。著者のユーリによれば、委員会は単一のネットワークよりも汎化能力が高い。
4.ネットワークをひっくり返すと、2度目のミスを犯す可能性があるからだ。ポイントは、現在の信号と以前の信号の2つを比較し、以前の信号の結果を知ることで、現在の信号について、その真偽などについて結論を導き出すことができるということだ。確かに、ネットワークは単純に間違いを犯す可能性がある。
まあ、私はクーデターを約束したわけではなく、TSのRIGHT構築の方法を約束しただけなのだが、時々、ちょっと怖くなるような異端なことを書く人がいるからだ。
1.分類器は、10クラス、100クラス、1000クラスを予測することができ、分類器のままである。分類とは、ラベル付けされていない データ集合を、ある属性に基づいてグループに分けることである。
2.オーバートレーニングが始まる瞬間を決定するのは簡単ではありませんが、非常に簡単です。
3.3.確かに、モデルの委員会は(常にではありません!)最良の結果をもたらします。しかし、あなたの場合は委員会とは言えない。
幸運を祈る。
残念ながら、私の批判は記事の文学的な質についてではなく、その意味内容についてのものだ。あなたは何も面白いことを言っていない。
デマークの代わりにどんな指標を入れても意味は変わらない、 では何のためのフィルターなのか?また、この特定のフィルターが良い機能であるとしても、その 理由を 説明していない。その後、実際にMLと 機能エンジニアリングについて 、すべてがオプティマイザーReshetovを作るということです...うーん...まあそれは...これは "肉 "のために、その後、特定の聴衆の記事のためのものですが、肉もジャー 実行する方法を理解することはできませんが、そこだけmtで実行し、どのように 排水の プロセスを見てする必要があります))。
レシェトフのオプティマイザーがどのように機能するのか、写真と数式を使って簡潔かつ簡潔に説明してください。
そして、特にレシェトフとストラディバリウスとの比較については、歌詞をすべて捨ててください。そうしないと、あなたとレシェトフが一人の物理的な人間のように見えるので、レクンでさえ誰も褒めません))))。私はReshetovのソートをダウンロードしましたが、そう手は、ソース上のアルゴリズムで理解するために到達しなかった、それは約一週間までかかることができますが、おそらく奇妙なアルゴリズムにそんなに時間がない、なぜか2桁のデータセットさえ食べたくない)))))2次元分布の分割マスクはどうやるのか見たかったのですが・・・。
私は記事の中で、どんなTSでもベースとして使うことができるということを話していたのですが、私は記事の中で説明した理由でDemarkを使いました(ウィンドウがあり、ピークと谷にシグナルがあります)。ポイントは、出力変数の一般化を持つ多項式を構築することであり、どのような助けを借りてそれを行うかに違いはありません。主なものは、価格の理由であるべき入力データである。
私は記事を編集した後、このリソースを見つけました。ここではオプティマイザーの仕事についてより明確に説明している。AI開発者にとっては非常に役に立つだろう。私はそうではないが、https://sites.google.com/site/libvmr/home/theory/method-brown-robinson-resetov。
- sites.google.com
1.分類器は、10クラス、100クラス、1000クラスを予測することができ、分類器のままである。分類 -ラベルのない データ集合を、特定の属性に基づいてグループに分けること。
2.オーバートレーニングが始まる瞬間を決定するのは簡単ではありませんが、非常に簡単です。
3.3.確かに、モデルの委員会は(常にではありません!)最良の結果をもたらします。しかし、あなたの場合は委員会とは言えない。
幸運を祈る。
1.分類器とクラスタリングがある場合とない場合の先生の違い、同感です。
2.再学習の将来のノーベル賞受賞者の話を聞くのは興味深いです。どのような方法で?また、過学習の程度を検出することは可能なのか?
3.委員会ではないと断定する理由は何ですか?興味深い......。
よし、レシェトフがストラディバリウスなら、自分はモーツァルトに過ぎないと言いたいんだな!
データセットを渡すから、そのデータセットで学習して、学習済みの分類器を作ってくれ。 やシリアライゼーションは 関係ない。重要なのは、数クリックで使えることだ。そして、Reshetovの創作についての会話を続けましょう。私は彼のソースのコードを取って解析するだけなので、Brown-Robinson法やShackleyベクトルなどについて理解するよりも簡単でしょう。
その結果をデータとあなたのモデルで公表するつもりだ。申し訳ないが、XGBより悪くないという証拠もなしに、1週間も分析に費やす余裕はない。
素晴らしいプランだ!前からやってみたかったんだ。トレーニング用のファイルを送ってくれたら、モデルを送るよ。いいね?
よし、レシェトフがストラディバリウスなら、自分はモーツァルトに過ぎないと言いたいんだな!
データセットを渡すから、そのデータセットで学習して、学習済みの分類器を作ってくれ。 やシリアライゼーションは 関係ない。重要なのは、数クリックで使えることだ。そして、Reshetovの創作についての会話を続けましょう。私は彼のソースのコードを取って解析するだけなので、Brown-Robinson法やShackleyベクトルなどについて理解するよりも簡単でしょう。
その結果をデータとあなたのモデルで公表するつもりだ。今のところ、それは何万とある単純な広告のブラックボックスに過ぎず、申し訳ないが、XGBより悪くないという証拠もなしに、1週間も分析に費やす余裕はない。
HMM。モーツァルトが誇らしげに聞こえる。しかし、重要な役割を果たすのは、与えられた変数の準備と出力変数の選択です。インプットがアウトプットの記述に合っていることをどうやって知るかだ。しかし、よく言われるように、入力がどれだけ出力に合っているかを判断するのはオプティマイザーなのだ。ポイントはこうだ。トレーニングセットでは出力をうまく解釈できる入力を選択できるが、OOSではその入力はうまく機能しない。これは、入力が出力の原因ではないことを示唆している。もうひとつは、入力が本当に出力の原因である場合、トレーニング時とOOS時のネットワークの性能は同じになるということです。考えてみてください。
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
新しい記事 人工知能を用いたTDシーケンシャル(トーマス デマークのシーケンシャル) はパブリッシュされました:
本稿では、よく知られている戦略とニューラルネットワークを融合させた成功裡の取引方法を説明します。これは、人工知能システムを用いたトーマス デマークのシーケンシャル戦略に関するもので、「セットアップ」シグナルと「インターセクション」シグナルを使用して、戦略の最初の部分のみが適用されます。
「不明」状態を分類するには、2つの方法があります。次の図をご覧ください。ここには矢印なしの「不明」シグナルが見られます。委員会の2つのネットワークは、それぞれ違った解釈をしています。これらのシグナルは、図中では1と2で示されています。最初のシグナルは、利益を上げるためには偽でなければなりません。
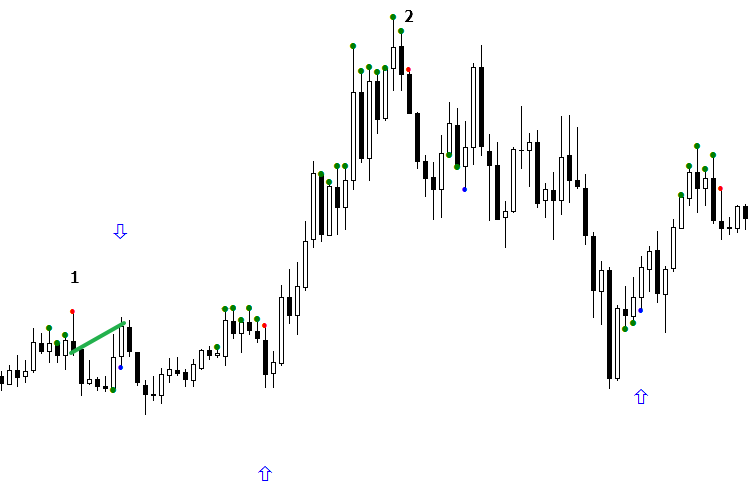
図6 日々の状況に応じたシグナル方向の編成方法作者: Mihail Marchukajtes