Discussione sull’articolo "Sviluppo di un robot in Python e MQL5 (Parte 1): Preelaborazione dei dati" - pagina 6
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Campione forward dal 2010, formazione prima del 2010.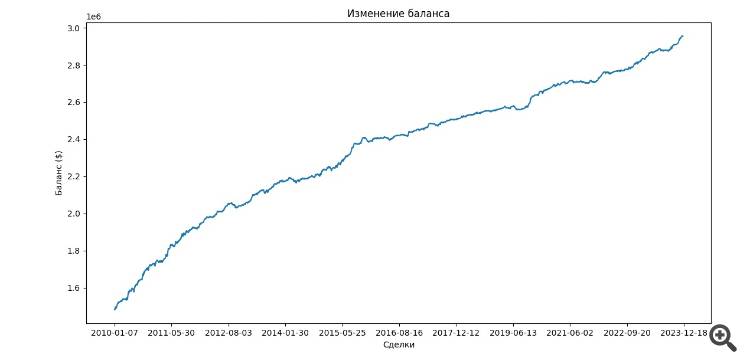
Ad esempio, ho implementato anche il campione EXAMWARD per testare il modello separatamente, ecco il risultato. Tutti gli altri modelli e reti neurali si sono basati su queste caratteristiche fin dal primo giorno.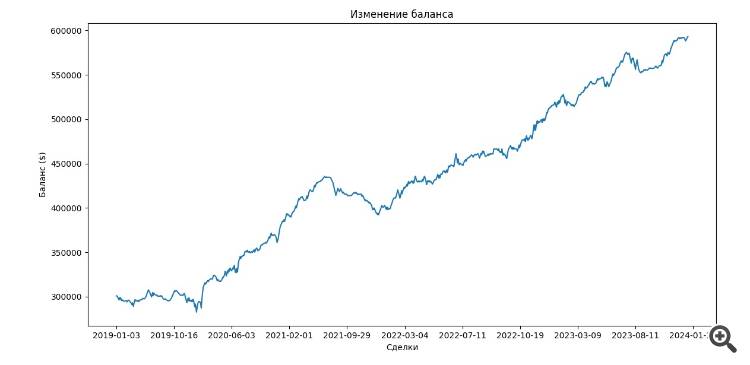
Ecco come si differenzia un semplice forward: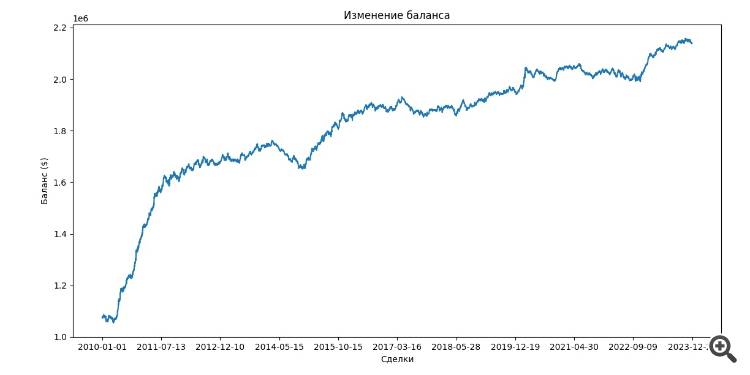
E un forward con chip come la convalida incrociata, il bagging del modello (sì, questo è tutto cucito in XGB per impostazione predefinita, credo, ma ho deciso di implementarlo), l'enumerazione degli iperparametri della griglia, ecc:
Se le etichette delle classi non vengono azzerate, allora la caratteristica migliore per prevedere le etichette saranno le etichette stesse, no?
Non si azzerano le etichette (che significa azzerare - cancellare - come sinonimo), ma si escludono le colonne che contengono le etichette e si inseriscono le etichette stesse separatamente nel modello come target, cioè le informazioni su di esse non vengono azzerate e non scompaiono irrimediabilmente, ma vengono utilizzate durante l'addestramento del modello.
Il modello XGBoost sui test, non importa quante volte lo esegua, in date diverse, mostra uno dopo l'altro proficui forward, decine di volte in date diverse con segni attuali. Anche se sono un principiante, ma non un idiota, ho interrotto l'allenamento per il periodo 2007-2016, e poi ho eseguito un test forward puro. L'accuratezza dei tag con operazioni di rischio-ricompensa 1:8 - 66% sui forward è nella media, a volte XGB tira fuori il 72-74%. Tutti gli altri modelli, le reti neurali, tutti gli altri bousting, le foreste casuali, hanno un'accuratezza spaventosa.
Ci sono molti errori da principiante nell'articolo - ho scritto prima, se si usa lo stesso codice - ci possono essere miracoli.
Provate a fare trading con la vostra soluzione per un mese su una demo, poi confrontate i punti di ingresso aggiungendo un campione per testare il modello.
È sicuramente interessante leggere dei miracoli di XGB, soprattutto per quanto riguarda il modo in cui hai trovato gli iperparametri - ho letto che è molto sensibile a questi ultimi.
Non volevo fare questa supposizione per non offenderti :)
D'ora in avanti, controlla la tua fonte prima di rimproverare
Ho installato il terminale in modalità portatile, devo scrivere la chiave "portatile" in qualche modo?
Se il terminale è in esecuzione - il codice non funziona, e se lo si spegne, prova ad avviarsi senza la chiave, ma non funziona nemmeno.
Ho installato il terminale in modalità portatile, devo scrivere la chiave "portatile" in qualche modo?
Se il terminale è in esecuzione, il codice non funziona, e se è spento, tenta di avviarsi senza la chiave, ma non funziona nemmeno questo.
Provate a eseguirlo direttamente dal terminale. Basta lanciare lo script sul grafico per stampare i risultati nella scheda "Esperti".
Forse è necessario specificare il percorso della cartella python nel meta-editor.
A me funziona così. Ma dopo un bel po' di balletti))))
Provate a eseguirlo direttamente dal terminale. Basta lanciare lo script sul grafico e i risultati vengono stampati nella scheda "Esperti".
Forse è necessario specificare il percorso della cartella python nel meta-editor.
A me funziona così. Ma dopo un bel po' di balletti))))
State usando il terminale in modalità portatile?
In ME il percorso è prescritto (appare automaticamente).
Siete in modalità portatile utilizzando il terminale?
In ME il percorso è prescritto (appare automaticamente).
Ho controllato nella versione portatile e tutto funziona.
Se sono in esecuzione due terminali e il percorso del terminale non è specificato nello script, si verifica un errore in uno dei terminali quando si cerca di compilare.
Controllato nella versione portatile, tutto funziona.
Se sono in esecuzione due terminali e il percorso del terminale non è specificato nello script, si verifica un errore in uno dei terminali quando si cerca di compilare.
L'ho eseguito dal terminale
Il percorso è stato specificato in entrambi i modi per il terminale.
Da qualche parte sta cercando nel posto sbagliato: c'è una cronologia nel terminale.