L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 146
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Non sono un trader di forex, non ho nemmeno familiarità con Metatrader :)
Vorrei sperimentare diversi profili in P, solo che non capisco come fare una distribuzione di due vettori
Mi piacerebbe sperimentare diverse varianti di profilo, solo che non è chiaro costruirlo con due vettori, non è necessario avere volumi, è solo un inizio, si può mettere quasi tutto nel profilo, ma dovrebbe essere fatto con il prezzo e questo è due vettori
Cosa ci fai allora su questo forum? Un forum dedicato interamente a MetaTrader? Hai già detto prima che non ci sarà un accesso diretto (API) all'ecosistema MetaTrader dall'esterno.
Leggete il titolo di questo thread e ditemi come è coinvolto Metatrader?
E qual è lo scopo di questa discussione?
Leggete il titolo di questo thread e ditemi come è coinvolto Metatrader?
e comunque qual è lo scopo di questa discussione?
Nuove biblioteche matematiche sono apparse nella consegna del terminale, per esempio:(Discutendo l'articolo "Distribuzioni statistiche in MQL5 - usando il meglio di R") - perché non pubblicate esempi per MetaTrader?
Non so come farlo :) non ho familiarità con MQL
Comunque, anche io (che non sono un programmatore) capisco che non posso farlo con le funzioni integrate, devo scrivere tutto io... Quello che hai tradotto una dozzina di funzioni statistiche da R è certamente buono e anche lodevole, ma capisci che questo non è nemmeno una goccia nell'oceano rispetto alle capacità diR, è in continua evoluzione, nuove librerie appaiono ogni giorno, non funzioni ma librerie, come puoi stare al passo con esso? E perché? Semplicemente deve essere usato...
Non so come farlo :) non ho familiarità con MQL
Comunque, anche io (che non sono un programmatore) capisco che non posso farlo con le funzioni integrate, devo scrivere tutto io... Quello che hai tradotto una dozzina di funzioni di statistica da R è certamente buono e anche lodevole, ma capire che questo non è nemmeno una goccia nel mare rispetto alle capacità di R, è in continua evoluzione, ogni giorno ci sono nuove librerie, non funzioni, ma librerie, come si può tenere il passo con questo?
Non conosci il linguaggio MQL, non conosci il terminale, come puoi giudicare qualcosa?
PS. Peccato, ci sono così tanti utenti su questo forum che sono parassiti dell'ecosistema MT. Ma mostra anche l'enorme popolarità e sofisticazione della piattaforma, che attira le persone più intelligenti per la ricerca in MQL, e naturalmente, attira i parassiti, come potrebbe essere senza di loro...
smettiamo di parlare di niente, ognuno ha un'opinione e questo thread ha un argomento specifico...
Allora, cosa c'è in quella distribuzione? Può essere costruita su due vettori o no? :)
Allora, che succede con quella distribuzione? Può essere tracciata su due vettori o no? :)
Ecco un buon articolo:https://www.r-bloggers.com/5-ways-to-do-2d-histograms-in-r/
Ecco un esempio più vitale. Nell'archivio c'è RData con eurusd h1 dal 2012 a oggi.
MetaQotes-Demo fornisce sia volumi di tick che volumi di trading, ma non so quanto siano affidabili.
Grazie! Ne ho uno simile nella mia roulotte...
Non so proprio come interpretare questa matriceh2$counts, c'è così tanta roba lì, è inquietante...
Vorrei ottenere qualcosa di simile a una distribuzione normale, come conhist() ricordate? Sarebbe simile al profilo del volume, o meglio ancora, uno a uno, è possibile farlo con gli strumenti P-key?
Ho qualcosa all'indirizzo https://futures.io/matlab-r-project-python/29465-r-volume-profile-volume-price.html, lo controllerò
Vorrei ottenere qualcosa di simile a una distribuzione normale, come conhist() ricordate? Sarebbe simile al profilo del volume, e meglio ancora, uno a uno, è possibile farlo con gli strumenti P-key?
Se si prende un solo vettore - il prezzo - l'istogramma mostrerà il numero di ripetizioni di ogni livello di prezzo. Ci saranno bar che crescono fuori dalla linea, per dirla semplicemente.
Se prendiamo due vettori - prezzo e volume, allora il prezzo avrà i suoi livelli e il volume avrà i suoi livelli. Sono due dimensioni diverse che formano un piano. Le barre dell'istogramma cresceranno verso l'alto dal piano, mostrando il numero di ripetizioni per ogni combinazione di prezzo e volume.
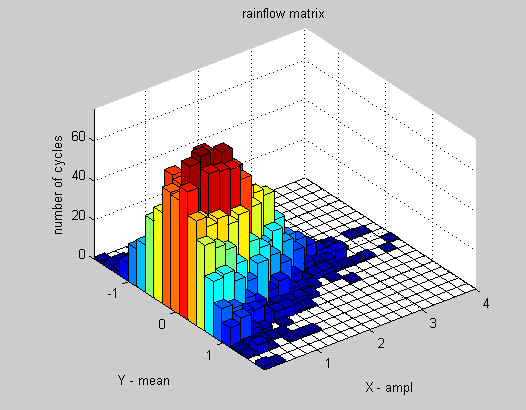
hist2d mostra l'altezza delle barre a colori invece di disegnare quelle tridimensionali. Una versione più carina sugli stessi dati sarebbe qualcosa del genere:
Per disegnare un semplice istogramma come in hist() per prezzo e volume, dovete prima usare una formula per convertire due vettori (prezzo e volume) in un singolo vettore e disegnare un istogramma per esso. Dovete decidere che tipo di nuovo vettore è questo, cosa volete da esso e dove prenderlo. In parole povere, si vuole ottenere un istogramma piatto da quell'immagine tridimensionale di cui sopra, il che può essere fatto in un numero infinito di modi.
h2$counts è la rappresentazione della matrice di questo istogramma. Prendete nbins=5 per esempio per ottenere un istogramma 5x5 e anche h2$counts sarà una matrice 5x5. Più luminosa è la cella dell'istogramma, più alto sarà il numero nella matrice nella cella corrispondente.
Ne aggiungerò altri più tardi.
Ho trovato un modo per farlo sembrare bello -